refactor : 전체 디렉토리 구조 변경
55
도서/SQL첫걸음/Contents.md
Normal file
@@ -0,0 +1,55 @@
|
||||
# Contents
|
||||
|
||||
## 1장. 데이터베이스와 SQL
|
||||
|
||||
- [01강. 데이터베이스](https://github.com/banjjoknim/TIL/blob/master/SQL%EC%B2%AB%EA%B1%B8%EC%9D%8C/Lecture01.md)
|
||||
- [02강. 다양한 데이터베이스](https://github.com/banjjoknim/TIL/blob/master/SQL%EC%B2%AB%EA%B1%B8%EC%9D%8C/Lecture02.md)
|
||||
- [03강. 데이터베이스 서버](https://github.com/banjjoknim/TIL/blob/master/SQL%EC%B2%AB%EA%B1%B8%EC%9D%8C/Lecture03.md)
|
||||
|
||||
## 2장. 테이블에서 데이터 검색
|
||||
|
||||
- [04강. Hello World 실행하기](https://github.com/banjjoknim/TIL/blob/master/SQL%EC%B2%AB%EA%B1%B8%EC%9D%8C/Lecture04.md)
|
||||
- [05강. 테이블 구조 참조하기](https://github.com/banjjoknim/TIL/blob/master/SQL%EC%B2%AB%EA%B1%B8%EC%9D%8C/Lecture05.md)
|
||||
- [06강. 검색 조건 지정하기](https://github.com/banjjoknim/TIL/blob/master/SQL%EC%B2%AB%EA%B1%B8%EC%9D%8C/Lecture06.md)
|
||||
- [07강. 조건 조합하기](https://github.com/banjjoknim/TIL/blob/master/SQL%EC%B2%AB%EA%B1%B8%EC%9D%8C/Lecture07.md)
|
||||
- [08강. 패턴 매칭에 의한 검색](https://github.com/banjjoknim/TIL/blob/master/SQL%EC%B2%AB%EA%B1%B8%EC%9D%8C/Lecture08.md)
|
||||
|
||||
## 3장. 정렬과 연산
|
||||
- [09강. 정렬 - ORDER BY](https://github.com/banjjoknim/TIL/blob/master/SQL%EC%B2%AB%EA%B1%B8%EC%9D%8C/Lecture09.md)
|
||||
- [10강. 복수의 열을 지정해 정렬하기](https://github.com/banjjoknim/TIL/blob/master/SQL%EC%B2%AB%EA%B1%B8%EC%9D%8C/Lecture10.md)
|
||||
- [11강. 결과 행 제한하기 - LIMIT](https://github.com/banjjoknim/TIL/blob/master/SQL%EC%B2%AB%EA%B1%B8%EC%9D%8C/Lecture11.md)
|
||||
- [12강. 수치 연산](https://github.com/banjjoknim/TIL/blob/master/SQL%EC%B2%AB%EA%B1%B8%EC%9D%8C/Lecture12.md)
|
||||
- [13강. 문자열 연산](https://github.com/banjjoknim/TIL/blob/master/SQL%EC%B2%AB%EA%B1%B8%EC%9D%8C/Lecture13.md)
|
||||
- [14강. 날짜 연산](https://github.com/banjjoknim/TIL/blob/master/SQL%EC%B2%AB%EA%B1%B8%EC%9D%8C/Lecture14.md)
|
||||
- [15강. CASE 문으로 데이터 변환하기](https://github.com/banjjoknim/TIL/blob/master/SQL%EC%B2%AB%EA%B1%B8%EC%9D%8C/Lecture15.md)
|
||||
|
||||
## 4장. 데이터의 추가, 삭제, 갱신
|
||||
- [16강. 행 추가하기 - INSERT](https://github.com/banjjoknim/TIL/blob/master/SQL%EC%B2%AB%EA%B1%B8%EC%9D%8C/Lecture16.md)
|
||||
- [17강. 삭제하기 - DELETE](https://github.com/banjjoknim/TIL/blob/master/SQL%EC%B2%AB%EA%B1%B8%EC%9D%8C/Lecture17.md)
|
||||
- [18강. 데이터 갱신하기 - UPDATE](https://github.com/banjjoknim/TIL/blob/master/SQL%EC%B2%AB%EA%B1%B8%EC%9D%8C/Lecture18.md)
|
||||
- [19강. 물리삭제와 논리삭제](https://github.com/banjjoknim/TIL/blob/master/SQL%EC%B2%AB%EA%B1%B8%EC%9D%8C/Lecture19.md)
|
||||
|
||||
## 5장. 집계와 서브쿼리
|
||||
- [20강. 행 개수 구하기 - COUNT](https://github.com/banjjoknim/TIL/blob/master/SQL%EC%B2%AB%EA%B1%B8%EC%9D%8C/Lecture20.md)
|
||||
- [21강. COUNT 이외의 집계함수](https://github.com/banjjoknim/TIL/blob/master/SQL%EC%B2%AB%EA%B1%B8%EC%9D%8C/Lecture21.md)
|
||||
- [22강. 그룹화 - GROUP BY](https://github.com/banjjoknim/TIL/blob/master/SQL%EC%B2%AB%EA%B1%B8%EC%9D%8C/Lecture22.md)
|
||||
- [23강. 서브쿼리](https://github.com/banjjoknim/TIL/blob/master/SQL%EC%B2%AB%EA%B1%B8%EC%9D%8C/Lecture23.md)
|
||||
- [24강. 상관 서브쿼리](https://github.com/banjjoknim/TIL/blob/master/SQL%EC%B2%AB%EA%B1%B8%EC%9D%8C/Lecture24.md)
|
||||
|
||||
## 6장. 데이터베이스 객체 작성과 삭제
|
||||
- [25강. 데이터베이스 객체](https://github.com/banjjoknim/TIL/blob/master/SQL%EC%B2%AB%EA%B1%B8%EC%9D%8C/Lecture25.md)
|
||||
- [26강. 테이블 작성, 삭제, 변경](https://github.com/banjjoknim/TIL/blob/master/SQL%EC%B2%AB%EA%B1%B8%EC%9D%8C/Lecture26.md)
|
||||
- [27강. 제약](https://github.com/banjjoknim/TIL/blob/master/SQL%EC%B2%AB%EA%B1%B8%EC%9D%8C/Lecture27.md)
|
||||
- [28강. 인덱스 구조](https://github.com/banjjoknim/TIL/blob/master/SQL%EC%B2%AB%EA%B1%B8%EC%9D%8C/Lecture28.md)
|
||||
- [29강. 인덱스 작성과 삭제](https://github.com/banjjoknim/TIL/blob/master/SQL%EC%B2%AB%EA%B1%B8%EC%9D%8C/Lecture29.md)
|
||||
- [30강. 뷰 작성과 삭제](https://github.com/banjjoknim/TIL/blob/master/SQL%EC%B2%AB%EA%B1%B8%EC%9D%8C/Lecture30.md)
|
||||
|
||||
## 7장. 복수의 테이블 다루기
|
||||
- [31강. 집합 연산](https://github.com/banjjoknim/TIL/blob/master/SQL%EC%B2%AB%EA%B1%B8%EC%9D%8C/Lecture31.md)
|
||||
- [32강. 테이블 결합](https://github.com/banjjoknim/TIL/blob/master/SQL%EC%B2%AB%EA%B1%B8%EC%9D%8C/Lecture32.md)
|
||||
- [33강. 관계형 모델](https://github.com/banjjoknim/TIL/blob/master/SQL%EC%B2%AB%EA%B1%B8%EC%9D%8C/Lecture33.md)
|
||||
|
||||
## 8장. 데이터베이스 설계
|
||||
- [34강. 데이터베이스 설계](https://github.com/banjjoknim/TIL/blob/master/SQL%EC%B2%AB%EA%B1%B8%EC%9D%8C/Lecture34.md)
|
||||
- [35강. 정규화](https://github.com/banjjoknim/TIL/blob/master/SQL%EC%B2%AB%EA%B1%B8%EC%9D%8C/Lecture35.md)
|
||||
- [36강. 트랜잭션](https://github.com/banjjoknim/TIL/blob/master/SQL%EC%B2%AB%EA%B1%B8%EC%9D%8C/Lecture36.md)
|
||||
70
도서/SQL첫걸음/Lecture01.md
Normal file
@@ -0,0 +1,70 @@
|
||||
# 01강. 데이터베이스
|
||||
- 데이터 : 컴퓨터 안에 기록되어 있는 숫자를 의미
|
||||
- 데이터베이스 : `데이터의 집합`, 넓은 의미에서는 컴퓨터 안에 기록된 모든 것을 데이터베이스라고 할 수 있다.
|
||||
- 다만, 일반적으로 통용되는 데이터베이스라는 개념은 `특정 데이터를 확인하고 싶을 때 간단하게 찾아낼 수 있도록 정리된 형태`를 가리킨다.
|
||||
- 데이터베이스 내의 데이터는 영구적으로 보존되어야 한다. 따라서 데이터베이스의 데이터는 하드디스크나 플래시메모리(`SSD`) 등 비휘발성 저장장치에 저장한다.
|
||||
|
||||
---
|
||||
|
||||
## 1. 시스템 내의 데이터베이스
|
||||
- 일반적으로 데이터센터의 서버에서 운용하는 형태가 있다.
|
||||
- 데이터베이스가 개인용 컴퓨터나 휴대용 기기에 내장되어 있기도 함.
|
||||
- 웹 시스템을 통해 데이터베이스에 접근할 수 있다.
|
||||
- 시스템을 직접 사용하지 않는 상황에서도 데이터베이스에 데이터가 전송되는 경우도 있다.
|
||||
- ex. 편의점에서 물건을 사면, 계산대(POS 시스템)에서 데이터가 데이터베이스로 전송된다.
|
||||
- 휴대용 기기에 존재하는 데이터베이스(ex. 휴대전화의 전화번호부)
|
||||
|
||||
---
|
||||
|
||||
## 2. DB와 DBMS
|
||||
- 데이터베이스는 일반적으로 `DB`라는 약자로 통용된다.
|
||||
- 데이터베이스는 저장장치 내에 정리되어 저장된 데이터의 집합이다.
|
||||
- 데이터베이스를 효율적으로 관리하는 소프트웨어를 `데이터베이스 관리 시스템(Database Management System)`, 약자로 `DBMS`라 부른다.
|
||||
|
||||
### 생산성
|
||||
- 시스템 개발 과정에서 생산성 향상을 도모할 수 있다.
|
||||
- `DBMS`는 데이터 검색, 추가, 삭제, 갱신과 같은 기본 기능을 제공한다.
|
||||
- 시스템을 구축할 때 기본 기능부터 구현하는 것은 비용 측면에서 효율적이지 않다.
|
||||
|
||||
### 기능성
|
||||
- `DBMS`는 데이터베이스를 다루는 기능을 많이 제공한다.
|
||||
- 복수 유저의 요청에 대응하거나, 대용량의 데이터를 저장하고 고속으로 검색하는 기능을 제공하기도 한다.
|
||||
- 데이터베이스 관리 기능을 유저가 확장할 수도 있어 유연하게 시스템을 개발할 수 있다.
|
||||
|
||||
### 신뢰성
|
||||
- 대규모 데이터베이스는 많은 요청에 대응할 수 있도록 만들어져 있다.
|
||||
- 이를 위해 하드웨어를 여러 대로 구성하여 신뢰성을 높이는 동시에 성능 향상을 꾀하기도 한다.
|
||||
- 일부 `DBMS`는 컴퓨터 여러 대를 두고, 소프트웨어를 통해 `확장성(Scalability)`과 `부하 분산(Load balancing)`을 구현한다. 이를 보통 `클러스터 구성` 또는 `스케일 아웃`이라 부른다.
|
||||
- 많은 `DBMS`가 데이터베이스의 데이터를 다른 저장장치로 내보내거나(`export`), 반대로 데이터베이스 안에 데이터를 집어넣는(`import`) 등의 기능을 갖추고 있다.
|
||||
- 이러한 집어넣기 및 내보내기 기능을 통해 데이터베이스를 간단하게 백업할 수도 있다.
|
||||
|
||||
##### DBMS란 데이터베이스를 관리하는 소프트웨어로, 사용 목적인 생산성 향상과 기능성, 신뢰성 확보에 있다!
|
||||
|
||||
---
|
||||
|
||||
## 3. 데이터베이스를 조작하는 언어 SQL
|
||||
- `DBMS`는 데이터베이스를 관리하는 소프트웨어이다.
|
||||
- `DBMS`를 이용하면 간접적으로 데이터베이스를 참조할 수 있고, 혹은 데이터를 추가하거나 삭제, 갱신할 수도 있다.
|
||||
- 이 같은 `DBMS`와의 대화에 필요한 것이 `SQL`이다.
|
||||
- 데이터베이스에도 몇 가지 종류가 있는데, `SQL`은 그중 `관계형 데이터베이스 관리 시스템(RDBMS:Relational Database Management System)`을 조작할 때 사용한다.
|
||||
- `SQL`은 `IBM`이 개발한 `SEQUEL`이라는 관계형 데이터베이스 조작용 언어를 기반으로 만들어졌다.
|
||||
- 현재 `ISO` 등에 의해 표준화가 진행되어, `C 언어`나 `자바(Java)`와 마찬가지로 표준 언어이다.
|
||||
- 이때 표준 언어라는 말은 곧 생산성을 향상시킬 수 있다는 의미이다.
|
||||
|
||||
##### SQL은 관계형 데이터베이스에서 사용한다!
|
||||
|
||||
### SQL 명령어의 종류
|
||||
`SQL` 명령은 크게 다음과 같이 3가지로 나뉠 수 있습니다.
|
||||
|
||||
- `DML`
|
||||
`Data Manipulation Language`의 약자. 데이터베이스에 새롭게 데이터를 추가하거나 삭제하거나 내용을 갱신하는 등, 데이터를 조작할 때 사용한다. `SQL`의 가장 기본이 되는 명령셋(`set`)이다.
|
||||
|
||||
- `DDL`
|
||||
`Data Definition Language`의 약자로 데이터를 정의하는 명령어. 데이터베이스는 `데이터베이스 객체(object)`라는 데이터 그릇을 이용하여 데이터를 관리하는데, 이 같은 객체를 만들거나 삭제하는 명령어이다.
|
||||
|
||||
- `DCL`
|
||||
`Data Control Language`의 약자로 데이터를 제어하는 명령어. `DCL`에는 트랜잭션을 제어하는 명령과 데이터 접근권한을 제어하는 명령이 포함되어 있다.
|
||||
|
||||
##### SQL명령은 DML, DDL, DCL의 세 종류로 나뉜다!
|
||||
|
||||
---
|
||||
95
도서/SQL첫걸음/Lecture02.md
Normal file
@@ -0,0 +1,95 @@
|
||||
# 02강. 다양한 데이터베이스
|
||||
- `DBMS`에는 여러 종류가 있다. 데이터베이스의 사용 용도나 이를 제어하는 프로그래밍 환경 등 각각의 조건에 들어맞는 다양한 `DBMS`가 고안되었기 때문이다.
|
||||
- 데이터베이스 중에서도 `SQL`로 데이터를 다루는 데이터베이스를 `관계형 데이터베이스(RDB: Relational Database)`라고 한다.
|
||||
|
||||
---
|
||||
|
||||
## 1. 데이터베이스 종류
|
||||
- `DBMS`는 데이터 저장 방법에 따라 몇 가지로 분류할 수 있다.
|
||||
|
||||
### 계층형 데이터베이스
|
||||
- 폴더와 파일 등의 계층 구조로 데이터를 저장하는 방식의 데이터베이스이다.
|
||||
- 하드디스크나 DVD 파일시스템을 이러한 계층형 데이터베이스라고 할 수 있다.
|
||||
- 하지만 현재 `DBMS`로 채택되는 경우는 많지 않다.
|
||||
|
||||
### 관계형 데이터베이스
|
||||
- `관계 대수(relational algebra)`라는 것에 착안하여 고안한 데이터베이스이다.
|
||||
- 쉽게 말하면 행과 열을 가지는 표 형식 데이터를 저장하는 형태의 데이터베이스를 가리킨다.
|
||||
- 다만, 엄밀히 말해 관계 대수는 표 형식 데이터와는 아무런 관계가 없다.
|
||||
- 표형식 데이터란 2차원 데이터를 말한다.
|
||||
- 가로 방향으로는 `열`을, 세로 방향으로는 `행`을 나열한다.
|
||||
- 관계형 데이터베이스에는 이러한 표를 잔뜩 저장해두고, 각각의 표에 이름을 붙여 관리한다. 이때 데이터베이스 안의 데이터는 `SQL` 명령어로 조작할 수 있다.
|
||||
|
||||
### 객체지향 데이터베이스
|
||||
- `자바`나 `C++`를 객체지향 언어라고 하는데, `객체(object)`라는 것을 중심으로 프로그래밍하는 언어이다.
|
||||
- 여기서 `가능하면 객체 그대로를 데이터베이스의 데이터로 저장하는 것`이 객체지향 데이터베이스이다.
|
||||
|
||||
### XML 데이터베이스
|
||||
- `XML`이란 자료 형식을 가리키는 용어로, 태그를 이용해 마크업 문서를 작성할 수 있게 정의한 것이다.
|
||||
태그는 `<data>데이터</data>`와 같은 형식으로 표현한다.
|
||||
- `XML` 데이터베이스는 이처럼 `XML` 형식으로 기록된 데이터를 저장하는 데이터베이스이다.
|
||||
- `XML` 데이터베이스에서는 `SQL` 명령을 사용할 수 없다. 대신 `XML` 데이터를 검색할 때는 `XQuery`라는 전용 명령어를 사용한다.
|
||||
|
||||
### 키-밸류 스토어(KVS)
|
||||
- 키와 그에 대응하는 값(밸류)이라는 단순한 형태의 데이터를 저장하는 데이터베이스이다.
|
||||
- 키와 밸류의 조합은 `연상배열`이나 해시 테이블(hash table)에서 자주 볼 수 있다.
|
||||
- `NoSQL(Not only SQL)`이라는 슬로건으로부터 생겨난 데이터베이스로, 열 지향 데이터베이스라고도 불린다.
|
||||
|
||||
```
|
||||
연상배열(associative array): 자료구조의 하나로, 키 하나와 값 하나가 연관되어 있으며
|
||||
키를 통해 연관되는 값을 얻을 수 있다. 연상 배열, 결합성 배열, 맵(map), 딕셔너리(dictionary)로 부르기도 한다.
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 2. RDBMS 사용 시스템
|
||||
- `RDBMS`는 역사가 깊은 만큼 다양한 시스템에서 사용된다.
|
||||
- `메인프레임(main frame)`은 대부분 `RDBMS`를 사용한다고 봐도 무방하다.
|
||||
- 다만, 최근에는 메인프레임 자체를 찾아보기가 어려워졌다. 다운사이징으로 인해 `소형 워크스테이션(workstation)`으로 대체되었기 때문이다.
|
||||
- 그래도 여전히 데이터베이스 서버로는 `RDBMS`가 사용되었는데, 이때부터 클라이언트/서버 구조도 유행했다.
|
||||
|
||||
---
|
||||
|
||||
## 3. 데이터베이스 제품
|
||||
- `RDBMS`는 관계형 데이터베이스를 관리하는 소프트웨어를 일컫는 말이다. 다만 `RDBMS`라는 이름의 소프트웨어가 존재한다는 뜻은 아니다.
|
||||
|
||||
### Oracle
|
||||
- `Oracle` 데이터베이스는 오라클에서 개발한 `RDBMS`이다.
|
||||
- 현재 가장 많이 쓰이는 `RDBMS` 중 하나로, 사실상 `RDBMS`의 표준이라고 해도 문제없을 정도로 유명하다.
|
||||
|
||||
### DB2
|
||||
- `IBM`이 개발한 `DB2`는 `Oracle`처럼 역사가 오래된 `RDBMS`이다.
|
||||
- 다만 오라클이 유닉스 워크스테이션 중심이었던 것과 달리, `DB2`는 발표된 이래 한동안 `IBM` 컴퓨터에서만 구동되었다.
|
||||
- 이후 유닉스나 윈도우 등의 플랫폼에서도 `DB2`를 구동할 수 있게 되었다.
|
||||
|
||||
### SQL Server
|
||||
- `SQL Server`는 윈도우를 개발한 마이크로소프트가 개발한 `RDBMS`로, 윈도우 플랫폼에서만 동작한다.
|
||||
|
||||
### PostgreSQL
|
||||
- `PostgreSQL`은 오픈소스 커뮤니티가 개발한 `RDBMS`이다. 무료 소프트웨어인 만큼 자유롭게 사용이 가능하다.
|
||||
- 기반이 되는 `RDBMS`는 캘리포니아 대학교 버클리 캠퍼스에서 탄생했는데, 그 때문인지는 몰라도 실험적인 기능이 포함되어 있거나 독특한 구로를 가지기도 한다.
|
||||
|
||||
### MySQL
|
||||
- `MySQL`은 `PostgreSQL`과 마찬가지로 오픈소스 커뮤니티에서 태어난 `RDBMS`이다.
|
||||
- 경량 데이터베이스라는 점을 강조하여, 필요한 최소한의 기능만을 갖추고 있다.
|
||||
- 하지만 기능이 확장되면서 지금은 다른 `RDBMS`와 비교해도 부족하지 않을 정도이다.
|
||||
|
||||
### SQLite
|
||||
- 오픈소스 커뮤니티에서 태어난 `SQLite`는 임베디드 시스템에 자주 쓰이는 작은 `RDBMS`이다.
|
||||
|
||||
---
|
||||
|
||||
## 4. SQL의 방언과 표준화
|
||||
- `RDBMS`는 처음부터 `SQL` 명령어를 이용해 데이터베이스를 조작하도록 설계된만큼, `SQL`을 사용할 수 없는 `RDBMS`는 없다.
|
||||
- 하지만 각 데이터베이스 제품 별로 기능 확장이 이루어지는 과정에서 `비슷한 조작을 실행하더라도 서로 다른 명령어가 필요한` 상황이 발생했다.
|
||||
- 즉 특정 데이터베이스 제품에만 통용되는 `고유 방언`이 생겨나게 되었다.
|
||||
- 고유 방언의 간단한 사례로 `키워드 생략`을 들 수 있다.
|
||||
- 데이터를 삭제할 때는 `DELETE` 명령어를 사용하는데, `Oracle`이나 `SQL Server`에서는 `DELETE` 뒤에 붙는 `FROM`을 생략해도 별 다른 문제가 없다. 그에 비해 `DB2`나 `PostgreSQL`, `MySQL`에서는 `FROM`을 생략할 경우 구문 에러가 발생해서 실행되지 않는다.
|
||||
- 다른 대표적인 방언의 사례로 `외부결합`을 들 수 있다.
|
||||
- `Oracle`에서는 `(+)`라는 특별한 연산자를 이용해 외부결합조건을 저장하는 데 비해, `SQL Server`에서는 `*=` 연산자를 이용한다.
|
||||
- 이와 같은 방언들 없애기 위해 `ISO`나 `ANSI`가 결정한 `SQL-92`, `SQL-99`, `SQL-2003`등이 바로 `표준 SQL`이고, 여기서 숫자는 책정된 해를 나타낸다.
|
||||
- 표준 SQL로 외부결합을 하는 방법은 `LEFT JOIN`이다.
|
||||
|
||||
##### SQL에는 방언이 있다! 방언 대신 표준 SQL을 사용하는 편이 좋다!
|
||||
|
||||
---
|
||||
64
도서/SQL첫걸음/Lecture03.md
Normal file
@@ -0,0 +1,64 @@
|
||||
# 03강. 데이터베이스 서버
|
||||
- `RDBMS`는 복수의 클라이언트가 보내오는 요청에 응답할 수 있도록 클라이언트/서버 모델로 동작한다.
|
||||
- 클라이언트는 서버에 접속 요청이나 SQL 명령 실행 요청을 보낼 수 있고, 서버는 이를 처리하고 클라이언트에 그 결과를 반환한다.
|
||||
- 일반적인 `RDBMS`는 네트워크 상에 하나의 서버를 두고 독점해 사용한다.
|
||||
|
||||
---
|
||||
|
||||
## 1. 클라이언트/서버 모델
|
||||
- `클라이언트/서버 모델`이란 사용자 조작에 따라 요청을 전달하는 `클라이언트`와 해당 요청을 받아 처리하는 `서버`로 소프트웨어가 나눠져있다.
|
||||
- `클라이언트/서버 모델`은 복수의 컴퓨터 상에서 하나의 모델을 구현하는 시스템을 말한다.
|
||||
|
||||
### 웹 시스템에서의 클라이언트/서버
|
||||
|
||||
##### 클라이언트/서버 모델은 클라이언트와 서버로 구성된다!
|
||||
|
||||
- 웹 시스템에서 클라이언트 기능을 하는 브라우저는 사용자가 지정한 `URL`과 연결된 웹 서버에 요청을 보낸다.
|
||||
- 이때 클라이언트가 보내는 요구사항을 웹 용어로는 `리퀘스트(request)`라고 한다.
|
||||
- 클라이언트의 요청을 받은 웹 서버에서는 그에 맞게 처리한다.
|
||||
- 서버는 브라우저가 페이지를 표시할 수 있도록 `HTML`로 된 데이터를 클라이언트로 반환하고 데이터는 네트워크를 통해서 전송된다.
|
||||
- 서버의 응답은 웹 용어로 `리스폰스(response)`라고 한다.
|
||||
- 페이지 내용을 전달받은 브라우저는 화면에 해당 페이지 내용을 표시한다.
|
||||
- 실제 웹에서는 요청과 응답이 되풀이되면서 웹 페이지가 표시된다.
|
||||
|
||||
### RDBMS의 클라이언트/서버
|
||||
- `RDBMS`도 웹 시스템과 마찬가지로 클라이언트/서버 모델로 시스템이 구성된다. 하지만 단순히 요청과 응답을 되풀이하는 것은 아니다.
|
||||
- 먼저, 웹 시스템에는 없었던 `사용자 인증`이 필요하다.
|
||||
- `RDBMS`는 사용자 별로 데이터베이스 접근을 제한할 수 있는데, 이 때문에 데이터베이스를 사용하기 위해서는 사용자 인증을 거쳐야 한다.
|
||||
- 사용자 인증은 `ID`와 `비밀번호`로 실행되고, 만약 인증에 실패하면 데이터베이스에 접속할 수 없다.
|
||||
|
||||
##### 데이터베이스를 사용할 때는 ID와 비밀번호를 이용한 사용자 인증이 필요하다!
|
||||
|
||||
### SQL명령 실행
|
||||
- `RDBMS`에 접속하면 SQL 명령을 서버에 보낼 수 있다.
|
||||
- 일단 한 번 데이터베이스에 접속하면, 이를 유지하여 재접속 없이 SQL 명령을 여러 번 보낼 수 있다.
|
||||
- 사용이 끝나면 데이터베이스와의 접속은 끊긴다. 일반적으로 클라이언트를 종료하면 데이터베이스 접속도 끊긴다.
|
||||
|
||||
---
|
||||
|
||||
## 2. 웹 애플리케이션의 구조
|
||||
- 웹 애플리케이션은 일반적으로 웹 서버와 데이터베이스 서버의 조합으로 구축된다.
|
||||
- 웹 시스템은 클라이언트/서버 모델로 구성되며 브라우저가 클라이언트, `아파치(Apache)`나 `IIS`와 같은 웹 소프트웨어가 서버 역할을 한다.
|
||||
- 웹 사이트가 정적인 `HTML`만으로 구성되어 있다면 웹 서버만으로도 시스템을 구축할 수 있을 것이다. 하지만 웹 애플리케이션이라 부를 정도의 규모라면 데이터베이스가 필요하다.
|
||||
- 웹 서버에서 동적으로 `HTML`을 생성하려면 제어용 프로그램이 필요하다. 웹 서버에는 `CGI`라 불리는 동적 콘텐츠를 위한 확장 방식이 있는데, 이 `CGI`를 이용하여 프로그램과 웹 서버 간을 연동, 통신하여 처리한다.
|
||||
- 프로그래밍 언어로서는 `펄(Perl)`이나 `PHP`, `루비(Ruby)` 등의 스크립트 언어가 자주 사용된다.
|
||||
- 윈도우의 경우는 `ASP.NET`이 많이 사용되며, `자바(Java)`와 `Servlet`과 같은 조합도 있다.
|
||||
- 실제로 데이터베이스에 접속하는 것은 `PHP`나 `루비` 등의 프로그래밍 언어로 만들어진 `CGI` 프로그램이다.
|
||||
- 데이터베이스 서버를 사용하기 위해서는 먼저 데이터베이스 서버와의 접속이 성립되어야 한다.
|
||||
- 그 후 데이터베이스에 필요한 SQL 명령을 전달하고, 실행 결과는 클라이언트로 되돌아간다.
|
||||
- 이때 웹 서버의 `CGI 프로그램이 데이터베이스의 클라이언트`가 된다.
|
||||
|
||||
##### 클라이언트/서버 모델은 유연한 하드웨어 구성을 실현한다!
|
||||
|
||||
---
|
||||
|
||||
## 3. MySQL 서버와 mysql 클라이언트
|
||||
- `MySQL` 패키지를 PC에 인스톨하면 서버와 클라이언트 모두 사용할 수 있다.
|
||||
- `MySQL` 서비스가 데이터베이스 서버가 되고, `mysql` 커맨드가 클라이언트가 된다.
|
||||
- `MySQL` 서비스는 PC 기동과 함께 자동으로 실행된다.
|
||||
- `MySQL` 서버에 접속해서 SQL 명령을 실행하는 방법에는 여러 가지가 있는데, `mysql` 클라이언트가 `MySQL`의 표준 커맨드이다.
|
||||
- `클라이언트/서버 모델`은 시스템의 하드웨어 구성을 유연하게 변경할 수 있도록 해준다. 클라이언트가 많아져 서버의 능력이 부족해지면 추가로 설치하여 부하 분산해 시스템 전체의 성농을 높일 수 있다.
|
||||
- PC 한 대로 클라이언트와 서버 모두 실행할 수 있지만 네트워크 기능은 필요하다.
|
||||
- 클라이언트에서 서버에 접속할 필요가 있는데, 이때 네트워크를 경유해서 PC의 서버로 되돌아오는 형태로 접속하고 이를 `루프 백 접속`이라 부른다.
|
||||
|
||||
---
|
||||
93
도서/SQL첫걸음/Lecture04.md
Normal file
@@ -0,0 +1,93 @@
|
||||
# 04강. Hello World 실행하기
|
||||
|
||||
- `Hello World`라는 것은 프로그래밍 언어를 배울 때 가장 처음 만들어보는 아주 간단한 프로그램일 일컫는 말이다.
|
||||
- `SQL`에서는 다음과 같은 `SELECT` 명령이 `Hello World`에 해당한다.
|
||||
|
||||
```
|
||||
SELECT * FROM 테이블명
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 1. 'SELECT * FROM 테이블명' 실행
|
||||
- `SQL` 명령은 `mysql 클라이언트에 문자를 입력하여 실행할 수 있다.
|
||||
- `SELECT`와 `*` 그리고 `FROM` 사이에는 스페이스를 넣어 구분한다.
|
||||
- 입력이 끝나면 명령의 마지막을 나타내는 `세미콜론(;)`을 넣어줘야 한다.
|
||||
- 세미콜론을 붙이지 않고 Enter 키를 누르면 입력중인 것으로 간주되어 명령문은 실행되지 않는다.
|
||||
|
||||
##### mysql 클라이언트에 SQL 명령을 입력하여 실행할 수 있다! 이때 SQL 명령의 마지막에는 세미콜론(;)을 붙인다!
|
||||
|
||||
---
|
||||
|
||||
## 2. SELECT 명령 구문
|
||||
- `SELECT`는 `DML`에 속하는 명령으로 `SQL`에서 자주 사용된다.
|
||||
- `SELECT` 명령으로 데이터베이스의 데이터를 읽어올 수 있다.
|
||||
- `SELECT` 명령은 `질의`나 `쿼리`로 불리기도 한다.
|
||||
|
||||
```
|
||||
SELECT * FROM sample21;
|
||||
```
|
||||
|
||||
- 맨 앞의 `SELECT`는 `SQL` 명령의 한 종류로 `SELECT 명령을 실행하세요`라는 의미이다.
|
||||
- 그 다음의 `애스터리스크(*)`는 `모든 열`을 의미하는 메타문자이다.
|
||||
- 위 명령어를 실행하면 `sample21 테이블`의 모든 데이터를 읽어온다.
|
||||
- `sample21 테이블`에 `*`라는 이름의 열이 존재하는 것은 아니다.
|
||||
- `SELECT` 명령을 실행할 때 `*` 부분이 자동으로 `모든 열`로 바뀐다고 생각하면 이해하기 쉬울 것이다.
|
||||
- 그 다음의 `FROM`은 처리 대상 테이블을 지정하는 키워드이다.
|
||||
- `FROM` 뒤에 테이블명을 지정한다.
|
||||
- `SQL` 명령은 키워드에 의해 `구`라는 단위로 나눌 수 있다.
|
||||
- 위 명령어의 경우, `SELECT 구`와 `FROM 구`로 나눌 수 있다.
|
||||
- `SELECT` 명령은 여러 개의 구로 구성된다.
|
||||
|
||||
##### *는 모든 열을 의미하는 메타문자이다! SQL 명령은 몇 개의 구로 구성된다!
|
||||
|
||||
---
|
||||
|
||||
## 3. 예약어와 데이터베이스 객체명
|
||||
- 다른 테이블의 내용을 보고 싶은 경우에는 `FROM` 뒤의 테이블명을 재지정하면 된다.
|
||||
|
||||
```
|
||||
SELECT * FROM sample21;
|
||||
```
|
||||
|
||||
- `SELECT`와 `FROM`이 구를 결정하는 키워드이자 **예약어**이다.
|
||||
- 데이터베이스에는 테이블 외에 다양한 데이터를 저장하거나 관리하는 `어떤 것`을 만들 수 있다.
|
||||
- 이것을 `데이터베이스 객체`라고 부른다(예를 들면 `뷰(view)`가 그에 해당함).
|
||||
- 데이터베이스 객체는 이름을 붙여 관리한다.
|
||||
- 같은 이름으로 다른 데이터베이스 객체는 만들 수 없다.
|
||||
- 통상적으로 데이터베이스 객체에는 예약어(`SELECT` 등)와 동일한 이름을 사용할 수 없다.
|
||||
|
||||
### 대소문자 구별
|
||||
- 예약어와 데이터베이스 객체명은 대소문자를 구별하지 않는다.
|
||||
|
||||
##### 예약어와 데이터베이스 객체명은 대소문자를 구별하지 않는다!
|
||||
|
||||
- `SQL` 명령과 달리 많은 데이터베이스 제품들은 데이터의 대소문자를 구별한다.
|
||||
- 단, 설정에 따라 구별하지 않는 경우도 있다.
|
||||
|
||||
---
|
||||
|
||||
## 4. Hello World를 실행한 결과 = 테이블
|
||||
- `SELECT` 명령을 실행하면 표 형식의 데이터가 출력된다.
|
||||
- 표 형식의 데이터는 `행(레코드)`과 `열(컬럼/필드)`로 구성된다.
|
||||
- 행은 모두 동일한 형태로 되어 있으며 옆으로 `열(컬럼/필드)`이 나열되는데, 열마다 이름이 지정되어 있다.
|
||||
- 각각의 행과 열이 만나는 부분을 `셀`이라고 부르며, `셀`에는 하나의 데이터 값이 저장되어 있다.
|
||||
|
||||
##### 테이블은 행과 열로 구성된 표 형식의 데이터다!
|
||||
|
||||
- 출력결과에서 숫자만으로 구성된 데이터를 `수치형` 데이터라고 하며, `수치형` 데이터는 오른쪽 정렬로 표시된다.
|
||||
- 임의의 문자로 구성된 데이터를 `문자열형` 데이터라 부른다. 문자형은 왼쪽으로 정렬되어 표시된다.
|
||||
- 날짜와 시각을 나타내는 데이터를 `날짜시간형` 데이터라고 하며 왼쪽으로 정렬되어 표시된다.
|
||||
- 열은 하나의 자료형만 가질 수 있으며, 수치형의 열에 문자형의 데이터를 저장할 수는 없다.
|
||||
|
||||
##### 데이터는 자료형으로 분류할 수 있다! 열은 하나의 자료형만 가질 수 있다!
|
||||
|
||||
---
|
||||
|
||||
## 5. 값이 없는 데이터 = NULL
|
||||
- `SELECT`의 결과를 잘 살펴보면 셀의 값이 `NULL`로 표시된 부분이 있는데, `NULL`은 특별한 데이터 값으로 아무것도 저장되어 있지 않은 상태를 의미한다.
|
||||
- `NULL`이라는 데이터가 저장되어 있는 것이 아닌, `아무 것도 저장되어 있지 않는 상태`라는 뜻이다.
|
||||
|
||||
##### NULL은 데이터가 들어있지 않은 것을 의미하는 특별한 값이다.
|
||||
|
||||
---
|
||||
68
도서/SQL첫걸음/Lecture05.md
Normal file
@@ -0,0 +1,68 @@
|
||||
# 05강. 테이블 구조 참조하기
|
||||
- `DESC` 명령으로 테이블 구조를 참조하는 방법을 알아본다.
|
||||
|
||||
**`DESC 명령`**
|
||||
```
|
||||
DESC 테이블명;
|
||||
```
|
||||
|
||||
- 열을 지정하여 조건을 붙이거나 특정 열의 값을 읽어올 수 있다.
|
||||
- 테이블에 어떤 열이 있는지 참조할 수 있으면 `SELECT` 명령을 작성하기 쉬워진다.
|
||||
|
||||
---
|
||||
|
||||
## 1. DESC 명령
|
||||
|
||||
```
|
||||
mysql> DESC sample21;
|
||||
```
|
||||
위의 명령을 실행하면 아래와 같은 결과가 화면에 나타난다.
|
||||
|
||||
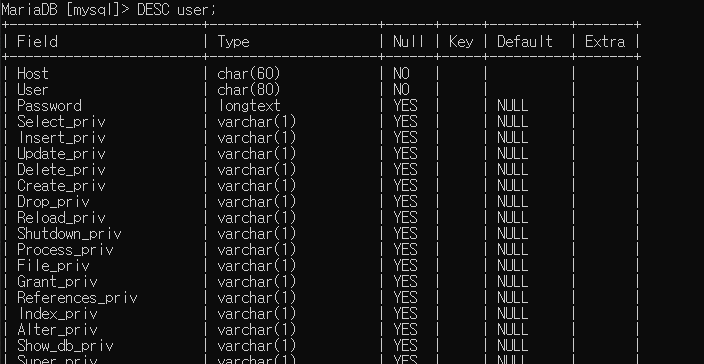
|
||||
|
||||
- `DESC` 명령으로 테이블에 어떤 열이 정의되어 있는지 알 수 있다(`DESC`는 `SQL` 명령이 아니다).
|
||||
- 맨 앞의 `Field`에는 열 이름이 표시된다.
|
||||
- `Type`은 해당 열의 `자료형`을 나타낸다.
|
||||
- `int`는 `Integer(정수)`를 의미한다.
|
||||
- 괄호안의 숫자는 최대 길이를 나타내는데, 예를 들어 `int(11)`은 `11자리의 정수값을 저장할 수 있는 자료형`이라는 의미이다.
|
||||
- `Null`은 `NULL` 값을 허용할 것인지 아닌지를 나타내는 **제약사항**으로 `Yes`로 지정하면 `NULL` 값을 허용하게 된다.
|
||||
- `Key`는 해당 열이 `키`로 지정되어 있는지를 나타낸다(행을 특정하기 위해 사용할 수 있는 열).
|
||||
- `Default`는 그 열에 주어진 `기본값` 즉, 생략했을 경우 적용되는 값이며, 테이블에 행을 추가할 때 열의 데이터 값을 생략하면 이 기본값으로 채워진다.
|
||||
|
||||
##### DESC 명령으로 테이블 구조를 참조할 수 있다.
|
||||
|
||||
---
|
||||
|
||||
## 2. 자료형
|
||||
- 테이블은 하나 이상의 열로 구성되며 `DESC` 명령으로 그 구조를 참조할 수 있다.
|
||||
- 열에는 몇 가지 속성을 지정할 수 있는데 그중 가장 중요한 속성은 `자료형`이다.
|
||||
|
||||
### INTEGER 형
|
||||
- `INTEGER 형`은 수치형의 하나로 정수값을 저장할 수 있는 자료형이다.
|
||||
- 소수점은 포함할 수 없다.
|
||||
|
||||
### CHAR 형
|
||||
- `CHAR 형`은 문자열형의 하나로 문자열을 저장할 수 있는 자료형이다.
|
||||
- 문자열형에서는 열의 최대 길이를 지정해야 한다. `CHAR(10)`으로 자료형을 지정했을 경우 `최대 10문자`로 된 문자열을 저장할 수 있으며 11문자로 된 문자열은 저장할 수 없다.
|
||||
- `CHAR 형`은 언제나 고정된 길이로 데이터가 저장된다.
|
||||
- `고정 길이 문자열` 자료형이라고 한다.
|
||||
- `CHAR 형`에서는 길이가 고정되기 때문에 최대 길이보다 작은 문자열을 저장할 경우 공백문자로 나머지를 채운후 저장하게 된다.
|
||||
|
||||
### VARCHAR 형
|
||||
- `VARCHAR 형` 역시 문자열을 저장할 수 있는 자료형이다.
|
||||
- 단, `CHAR 형`과는 달리 데이터 크기에 맞춰 저장공간의 크기도 변경된다.
|
||||
- `가변 길이 문자열` 자료형이라고 한다.
|
||||
|
||||
### DATE 형
|
||||
- `DATE 형`은 날짜값을 저장할 수 있는 자료형이다.
|
||||
- 날짜값이란 `2013년 3월 23일`과 같이 `연월일의 데이터`를 저장할 수 있는 형이다.
|
||||
|
||||
### TIME 형
|
||||
- `TIME 형`은 시간을 저장할 수 있는 자료형이다.
|
||||
- 예를들어 `12시 30분 20초`와 같이 `시분초의 데이터`를 저장할 수 있는 형이다.
|
||||
|
||||
##### 문자열형에는 고정 길이와 가변 길이가 있다!
|
||||
|
||||
`자주 쓰이는 자료형 위주로 설명한 것이며, 이 외에도 많은 자료형이 있다.`
|
||||
|
||||
---
|
||||
121
도서/SQL첫걸음/Lecture06.md
Normal file
@@ -0,0 +1,121 @@
|
||||
# 06강. 검색 조건 지정하기
|
||||
- 데이터 검색에는 열을 지정하는 방법과 행을 지정하는 방법이 있다.
|
||||
|
||||
**`SELECT 구와 WHERE 구`**
|
||||
```
|
||||
SELECT 열1, 열2 FROM 테이블명 WHERE 조건식
|
||||
```
|
||||
|
||||
- 행을 선택할 때는 `WHERE` 구를 사용하며, 열을 선택할 때는 `SELECT` 구를 사용한다.
|
||||
|
||||
---
|
||||
|
||||
## 1. SELECT 구에서 열 지정하기
|
||||
- 데이터를 선택할 때는 열이나 행을 한정한다.
|
||||
|
||||
**`SELECT 구에서 열 지정`**
|
||||
```
|
||||
SELECT 열1, 열2 ... FROM 테이블명
|
||||
```
|
||||
|
||||
- 열은 위의 구문처럼 `콤마(,)`를 이용하여 구분 지으며 여러 개를 지정할 수 있고 지정한 열만 결괏값으로 표시된다.
|
||||
- 만약 열을 전혀 지정하지 않으면 구문 에러가 발생하며, 또한 테이블에 존재하지 않는 열을 지정해도 에러가 발생한다.
|
||||
- 열 지정 순서는 임의로 정할 수 있다.
|
||||
- 결과는 지정한 열의 순서대로 표시되며, 동일한 열을 중복해서 지정해도 무관하다.
|
||||
|
||||
##### SELECT 구에서 결과로 표시하고 싶은 열을 지정할 수 있다!
|
||||
|
||||
---
|
||||
|
||||
## 2. WHERE 구에서 행 지정하기
|
||||
- 행 속에서 필요한 데이터만 검색하기 위해서는 `WHERE` 구를 사용한다.
|
||||
- `WHERE` 구는 `FROM` 구의 뒤에 표기하며, 예약어 `WHERE` 뒤에 검색 조건을 표기한다.
|
||||
- 조건에 일치하는 행만 `SELECT`의 결과로 반환된다.
|
||||
|
||||
**`WHERE 구로 행 추출`**
|
||||
```
|
||||
SELECT 열 FROM 테이블명 WHERE 조건식
|
||||
```
|
||||
|
||||
### 구의 순서와 생략
|
||||
- `SQL`에서는 구의 순서가 정해져 있어 바꿔적을 수 없다.
|
||||
- `FROM` 구 뒤에 `WHERE` 구를 표기한다.
|
||||
- 구에는 `WHERE` 구처럼 생략 가능한 것도 있다.
|
||||
- 만약 `WHERE` 구를 생략한 경우는 테이블 내의 모든 행이 검색 대상이 된다.
|
||||
|
||||
### WHERE 구
|
||||
- 조건식은 `열과 연산자, 상수로 구성되는 식`이다.
|
||||
- 예를 들면 `no = 2`는 올바른 조건식이며, 이 조건식에 일치하는 행만 `SELECT`의 결과로 반환된다.
|
||||
- `WHERE` 구로 행을 추출하면서 `SELECT` 구로 열 지정을 동시에 할 수도 있다.
|
||||
|
||||
##### WHERE 구의 조건에 일치하는 행만 결과로 반환된다!
|
||||
|
||||
### 조건식
|
||||
- 조건식 `no = 2`는 `no 열 값이 2일 경우에` 참이 되는 조건이다.
|
||||
- `no = 2`은 `no` `=` `2`의 세 개 항목으로 나눌 수 있다. 첫 번째 항목인 `no`는 열 이름이고 두 번째 항목 `=`는 연산자이다.
|
||||
- 연산자란 어떤 계산을 할지 지정하는 것으로 보통 기호로 표기한다.
|
||||
- `=`의 경우, 좌우로 2개 항목이 필요한 `이항 연산자`에 해당하며 일반적으로 많이 쓰이는 기호이다.
|
||||
- `=` 연산자를 기준으로 좌변과 우변의 항목을 비교하고, 서로 같은 값이면 참을, 같지 않으면 거짓을 반환한다.
|
||||
- 조건식을 만족한(참) 행만 결괏값으로 반환된다.
|
||||
- `=` 연산자는 비교한 결괏값이 참인지 거짓인지를 반환하므로 `비교 연산자`라 부른다.
|
||||
|
||||
##### 조건식은 참 또는 거짓의 진리값을 반환하는 식으로 비교 연산자를 사용해 표현한다!
|
||||
|
||||
### 값이 서로 다른 경우 '<>'
|
||||
- 비교 연산자는 `=` 외에도 존재한다.
|
||||
- 조건식에 사용하는 연산자를 바꾸거나 복수의 연산자를 조합하면 복잡한 조건식을 만들 수 있다.
|
||||
- `=` 연산자가 서로 같은 값인지를 비교하는 연산자인 데 반해, `<>` 연산자는 서로 다른 값인지를 비교하는 연산자이다.
|
||||
|
||||
##### <> 연산자를 통해 '값이 서로 다른 경우' 참이 되는 조건식으로 변경할 수 있다!
|
||||
|
||||
- `WHERE` 구에서 지정한 조건식에 따라 반환되는 행의 갯수는 달라지며, 반드시 하나의 행만 반환되는 것은 아니다.
|
||||
- 조건식에 일치하는 행이 전혀 없는 경우에는 아무것도 반환되지 않을 수도 있다.
|
||||
|
||||
---
|
||||
|
||||
## 3. 문자열형의 상수
|
||||
- 수치형 조건식의 경우 비교할 숫자를 그대로 조건식에 표기한다.
|
||||
- 하지만 문자열형을 비교할 경우는 `'banjjoknim'`처럼 `싱글쿼트(' ')`로 둘러싸 표기해야 한다.
|
||||
- 날짜시간형의 경우에도 싱글쿼트로 둘러싸 표기하며, 이때 연월일을 `하이픈(-)`으로 구분한다.
|
||||
- 시각은 `시분초`를 `콜론(:)`으로 구분하여 표기한다.
|
||||
- 문자열형의 열과 비교하기 위해서는 조건으로 지정할 값도 그 자료형에 맞춰 지정해야 한다.
|
||||
- 자료형에 맞게 표기한 상수값을 `리터럴(literal)`이라 부른다.
|
||||
- 문자열 리터럴은 싱글쿼트로 둘러싸 표기한다.
|
||||
|
||||
```
|
||||
수치형 상수 -> 1 100 -3.8
|
||||
문자열형 상수 -> 'ABC' 'banjjoknim'
|
||||
날짜시간형 상수 -> '2013-01-25' '2013-03-03 10:21:00'
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 4. NULL값 검색
|
||||
- `=` 연산자로 `NULL`을 검색할 수는 없다.
|
||||
|
||||
### IS NULL
|
||||
`NULL` 값을 검색할 때는 `=` 연산자가 아닌 `IS NULL`을 사용한다.
|
||||
- `IS NULL`은 술어로 연산자의 한 종류로 생각하면 된다.
|
||||
- `birthday IS NULL` 과 같이 사용하면 된다.
|
||||
- 반대로 `NULL` 값이 아닌 행을 검색하고 싶다면 `IS NOT NULL`을 사용하면 된다.
|
||||
|
||||
##### NULL 값을 검색할 경우에는 IS NULL 을 사용한다!
|
||||
|
||||
---
|
||||
|
||||
## 5. 비교 연산자
|
||||
- `=` 연산자와 `<>` 연산자, `IS NULL`로 검색할 수 있다.
|
||||
- `WHERE` 구로 지정하는 조건식은 참과 거짓을 반환하는 비교 연산자나 술어를 사용해서 표기할 수 있다.
|
||||
- `= 연산자` : 좌변과 우변의 값이 같을 경우 참이 된다.
|
||||
- `<> 연산자` : 좌변과 우변의 값이 같지 않을 경우 참이 된다.
|
||||
- `> 연산자` : 좌변의 값이 우변의 값보다 클 경우 참이 된다. 같거나 작을 경우는 거짓이 된다.
|
||||
- `>= 연산자` : 좌변의 값이 우변의 값보다 크거나 같을 경우 참이 된다. 작을 경우는 거짓이 된다.
|
||||
- `< 연산자` : 좌변의 값이 우변의 값보다 작을 경우 참이 된다. 같거나 클 경우는 거짓이 된다.
|
||||
- `<= 연산자` : 좌변의 값이 우변의 값보다 작거나 같을 경우 참이 된다. 클 경우는 거짓이 된다.
|
||||
|
||||
- `< 연산자와 > 연산자`는 대소관계를 비교하는 연산자이지만 `=`을 붙임으로써 서로 값이 같은 경우도 비교할 수 있다.
|
||||
- `=`은 `<`, `>`의 뒤에 붙인다(앞에 붙이는 것은 틀린 표기법).
|
||||
- 또한 `<=`나 `>=`을 표기할 때에는 사이에 스페이스를 넣어서는 안된다.
|
||||
- `< =`와 같이 스페이스를 넣으면 `<`와 `=`로 연산자가 두 개라고 판단하여 에러가 발생한다.
|
||||
|
||||
---
|
||||
99
도서/SQL첫걸음/Lecture07.md
Normal file
@@ -0,0 +1,99 @@
|
||||
# 07강. 조건 조합하기
|
||||
|
||||
**`AND, OR, NOT`**
|
||||
```
|
||||
조건식1 AND 조건식2
|
||||
조건식1 OR 조건식2
|
||||
NOT 조건식
|
||||
```
|
||||
|
||||
- 조건식을 조합해 사용할 경우 복수의 조건은 `WHERE` 구로 지정한다.
|
||||
- 조합할 때는 `AND`, `OR`, `NOT`의 3가지 방법을 사용할 수 있다.
|
||||
|
||||
---
|
||||
|
||||
## 1. AND로 조합하기
|
||||
- 복수의 조건을 조합할 경우 `AND`를 가장 많이 사용한다.
|
||||
- `AND`는 논리 연산자의 하나로 좌우에 항목이 필요한 이항 연산자가 된다.
|
||||
- 좌우의 식 모두 참일 경우 `AND` 연산자는 참을 반환한다.
|
||||
- `모든 조건을 만족하는 경우 조건식은 참이 된다`고 할 때 `AND` 연산자로 조건식을 조합한다.
|
||||
- 쉽게 말하면 `및`에 해당한다.
|
||||
|
||||
**`AND`**
|
||||
```
|
||||
조건식1 AND 조건식2
|
||||
```
|
||||
|
||||
- 0이 아니라는 조건은 `a<>0`과 같이 표현한다.
|
||||
- `AND` 연산은 조건을 만족하는 행을 집합으로 표현했을 때 이들 집합이 겹치는 부분, 즉 `교집합`으로 계산할 수 있다.
|
||||
- `AND` 연산자는 논리곱을 계산하는 논리 연산자이다.
|
||||
|
||||
##### AND로 조건식을 연결하면 모든 조건을 만족하는 행을 검색할 수 있다!
|
||||
|
||||
---
|
||||
|
||||
## 2. OR로 조합하기
|
||||
- `어느 쪽이든 하나만 참이 되면 조건식은 참이 된다`라고 할 경우에는 `OR`로 조건식을 연결한다.
|
||||
- `OR` 또한 논리 연산자의 하나로 좌우 항목이 모두 필요한 이항 연산자이다.
|
||||
- `AND`와 달리 어느 쪽이든 조건을 만족하면 결과는 참이 된다.
|
||||
- 모든 조건이 거짓인 경우 결과는 거짓이 된다.
|
||||
- 즉, `OR`는 `또는`에 해당한다.
|
||||
|
||||
**`OR`**
|
||||
```
|
||||
조건식1 OR 조건식2
|
||||
```
|
||||
|
||||
- `OR` 연산은 조건을 만족하는 행을 집합으로 표현했을 때, 이 집합들을 합한 부분, 즉 `합집합`으로 계산할 수 있다.
|
||||
- `OR` 연산자는 논리합을 계산하는 논리 연산자이다.
|
||||
|
||||
##### OR로 조건식을 연결하면 어느 쪽이든 조건을 만족하는 행을 모두 검색할 수 있다!
|
||||
|
||||
---
|
||||
|
||||
## 3. AND와 OR를 사용할 경우 주의할 점
|
||||
- `AND` 연산자나 `OR` 연산자의 좌우로 참과 거짓을 반환하는 조건식을 지정하는 경우가 많다.
|
||||
- 열이나 상수만을 지정해도 에러가 발생하지는 않지만 기대한 결괏값을 얻을 수 없다.
|
||||
- 예를 들어 다음과 같은 조건식을 사용하면 올바른 결과를 얻을 수 없다.
|
||||
|
||||
```
|
||||
SELECT * FROM sample24 WHERE no = 1 OR 2;
|
||||
```
|
||||
|
||||
- 상수 `2`는 논리 연산으로 항상 참이 되기 때문에 결과적으로 모든 행을 반환하게 된다.
|
||||
|
||||
올바른 조건식은 다음과 같다.
|
||||
|
||||
```
|
||||
SELECT * FROM sample24 WHERE no = 1 OR no = 2;
|
||||
```
|
||||
|
||||
### AND와 OR를 조합해 사용하기
|
||||
- `a<>0 AND b<>0`이라는 조건식을 `a=1 OR a=2 AND b=1 OR b=2`로 변경해보면, `a<>0 AND b<>0`의 조건식 결과와는 다른 것을 알 수 있다.
|
||||
|
||||
### 연산자의 우선 순위
|
||||
- 결과가 다른 이유는 `AND`와 `OR`의 계산 우선 순위가 다르기 때문이다.
|
||||
- `OR` 보다 `AND` 쪽이 우선 순위가 높기 때문에 `a = 2 AND b = 1`이 먼저 계산된다.
|
||||
- 즉, `WHERE a=1 OR (a=2 AND b=1) OR b=2`와 같다.
|
||||
- 따라서 조건식은 `a=1`, `a=2 AND b=1`, `b=2`의 3개로 나뉜다.
|
||||
- 그러므로 처음 원한 대로 조건을 지정하기 위해서는 괄호로 우선 순위를 변경하면 된다.
|
||||
- `SELECT * FROM sample24 WHERE (a=1 OR a=2) AND (b=1 OR b=2);`
|
||||
- 일반적으로 `OR` 조건식은 괄호로 묶어 지정하는 경우가 많다.
|
||||
|
||||
##### AND는 OR에 비해 우선 순위가 높다!
|
||||
|
||||
---
|
||||
|
||||
## 4. NOT으로 조합
|
||||
|
||||
**`NOT`**
|
||||
```
|
||||
NOT 조건식
|
||||
```
|
||||
|
||||
- `NOT` 연산자는 오른쪽에만 항목을 지정하는 `단항 연산자`이다.
|
||||
- 오른쪽에 지정한 조건식의 반대 값을 반환한다.
|
||||
- 만약 조건식이 참을 반환하면 `NOT`은 이에 반하는 거짓을 반환한다.
|
||||
- 주로 복수의 조건식에 대해 `~아닌`, `~외에`, `~를 제외한 나머지` 등의 조건을 지정할 경우 사용한다.
|
||||
|
||||
---
|
||||
76
도서/SQL첫걸음/Lecture08.md
Normal file
@@ -0,0 +1,76 @@
|
||||
# 08강. 패턴 매칭에 의한 검색
|
||||
- `LIKE` 술어를 사용하면 문자열의 일부분을 비교하는 `부분 검색`을 할 수 있다.
|
||||
|
||||
**`LIKE`**
|
||||
```
|
||||
열 LIKE 패턴
|
||||
```
|
||||
|
||||
- `특정 문자나 문자열이 포함되어 있는지를 검색하고 싶은` 경우에 사용하는 방법이다.
|
||||
- `패턴 매칭` 또는 `부분 검색`이라고도 한다.
|
||||
|
||||
---
|
||||
|
||||
## 1. LIKE로 패턴 매칭하기
|
||||
- `LIKE` 술어를 사용하면 열 값이 부분적으로 일치하는 경우에도 참이 된다.
|
||||
|
||||
**`LIKE`**
|
||||
```
|
||||
열명 LIKE '패턴'
|
||||
```
|
||||
|
||||
- `LIKE` 술어는 이항 연산자처럼 항목을 지정한다.
|
||||
- 왼쪽에는 매칭 대상을 지정하고 오른쪽에는 패턴을 문자열로 지정한다.
|
||||
- 단, 수치형 상수는 지정할 수 없다.
|
||||
- 패턴을 정의할 때는 `%_`과 같은 `메타문자`를 사용할 수 있다.
|
||||
- `와일드카드`라고도 불리는 메타문자는 패턴 매칭 시 `임의의 문자 또는 문자열`에 매치하는 부분을 지정하기 위해 쓰이는 `특수문자`이다.
|
||||
- `퍼센트(%)`는 임의의 문자열을 의마하며, `언더스코어(_)`는 임의의 문자 하나를 의미한다.
|
||||
- 패턴을 정의할 때는 메타문자를 여러 개 사용할 수 있다.
|
||||
- 메타문자를 전혀 정의하지 않아도 문제는 없지만, 완전 일치로 검색되므로 의미가 없다.
|
||||
- 와일드카드로 자주 쓰이는 `*`는 `LIKE`에서는 사용할 수 없다.
|
||||
|
||||
##### LIKE 술어를 사용하여 패턴 매칭으로 검색할 수 있다!
|
||||
##### 패턴을 정의할 때 사용할 수 있는 메타문자로는 %와 _이 있다!
|
||||
|
||||
- 메타문자 패턴은 `%SQL`, `%SQL%`, `SQL%` 의 형식으로 사용된다.
|
||||
|
||||
##### %는 임의의 문자열과 매치하며, 빈 문자열에도 매치한다!
|
||||
|
||||
- `SQL%`을 이용한 검색은 문자열 앞쪽에 지정한 문자와 일치하므로 `전방 일치`라고 부르며, 지정한 문자 뒤로 임의의 문자열이 존재하게 된다.
|
||||
- `%SQL%`의 경우는 지정 문자열이 중간에 있기 때문에 `중간 일치`라고 부르며 지정한 문자 앞뒤로 임의의 문자열이 존재한다.
|
||||
- 마찬가지로 `%SQL`의 경우에는 `후방 일치`라고 하며, 앞쪽에 임의의 문자열이 존재한다.
|
||||
|
||||
---
|
||||
|
||||
## 2. LIKE로 %를 검색하기
|
||||
- `LIKE`에서는 메타문자 부분이 임의의 문자열을 의미하므로, `%` 자신을 검색조건으로 지정할 때는 `WHERE text LIKE %%%`로도 매치하지 않기 때문에 구분할 필요가 있다.
|
||||
- 이러한 문제를 `이스케이프`라는 방법으로 처리할 수 있다.
|
||||
- `LIKE`로 `%`를 검색하는 경우에는 `\%`와 같이 `\`을 `%` 앞에 붙인다.
|
||||
- 결국 `%`를 포함하는 데이터를 검색하고 싶을 경우 조건식은 `WHERE text LIKE '%\%%'`와 같다.
|
||||
|
||||
##### %를 LIKE로 검색할 경우에는 \%로 한다!
|
||||
##### _를 LIKE로 검색할 경우에는 \_로 한다!
|
||||
|
||||
---
|
||||
|
||||
## 3. 문자열 상수 '의 이스케이프
|
||||
- 메타문자를 검색할 때처럼 문자열 상수를 검색할 때도 같은 문제가 발생한다.
|
||||
- 문자열 상수 안에 `'`를 포함하고 싶을 경우, `표준 SQL`에서는 `'`를 2개 연속해서 기술하는 것으로 이스케이프 처리를 할 수 있다.
|
||||
- 예를 들어 `'It's'`라는 문자열을 문자열 상수로 표기하면 `'It''s'`로 쓴다.
|
||||
- 또한 `'` 하나만 문자열 데이터일 경우에는 `''''`으로 쓰면 된다.
|
||||
|
||||
**`문자열 상수 안에 ' 기술하기`**
|
||||
```
|
||||
It's -> 'It''s'
|
||||
' -> ''''
|
||||
```
|
||||
|
||||
- SQL에서는 싱글쿼트로 문자열 상수를 기술하는데 시작의 `'`과 끝의 `'`이 정확하게 표기되지 않으면 에러가 발생하므로 주의해야 한다.
|
||||
|
||||
##### '을 문자열 상수 안에 포함할 경우는 '를 2개 연속해서 기술한다!
|
||||
|
||||
- 간단한 패턴 매칭이라면 `LIKE`로 충분하다.
|
||||
- 복잡한 패턴을 매칭하는 경우는 `정규 표현식(Regular Expression)`을 사용하는 편이 낫다.
|
||||
- 정규 표현식에서는 더 많은 메타문자를 사용해서 폭넓게 패턴을 지정할 수 있다.
|
||||
|
||||
---
|
||||
79
도서/SQL첫걸음/Lecture09.md
Normal file
@@ -0,0 +1,79 @@
|
||||
# 09강. 정렬 - ORDER BY
|
||||
**`ORDER BY 구`**
|
||||
```
|
||||
SELECT 열명 FROM 테이블명 WHERE 조건식 ORDER BY 열명
|
||||
```
|
||||
|
||||
- `SELECT` 명령에 `ORDER BY` 구를 지정하면 검색 결과의 행 순서를 바꿀 수 있다.
|
||||
- `ORDER BY` 구를 지정하지 않을 경우에는 데이터베이스 내부에 저장된 순서로 반환된다.
|
||||
- 언제나 정해진 순서로 결괏값을 얻기 위해서는 `ORDER BY` 구를 지정해야 한다.
|
||||
|
||||
---
|
||||
|
||||
## 1. ORDER BY로 검색 결과 정렬하기
|
||||
- `SELECT` 명령의 `ORDER BY` 구로 정렬하고 싶은 열을 지정하면 지정된 열의 값에 따라 행 순서가 변경된다.
|
||||
- 이때 `ORDER BY` 구는 `WHERE` 구 뒤에 지정한다.
|
||||
|
||||
**`WHERE 구 뒤에 ORDER BY 구를 지정하는 경우`**
|
||||
`SELECT 열명 FROM 테이블명 WHERE 조건식 ORDER BY 열명`
|
||||
|
||||
- 검색 조건이 필요없는 경우에는 `WHERE` 구를 생략하는데 이때 `ORDER BY` 구는 `FROM` 구의 뒤에 지정한다.
|
||||
|
||||
**`FROM 구 뒤에 ORDER BY 구를 지정하는 경우`**
|
||||
```
|
||||
SELECT 열명 FROM 테이블명 ORDER BY 열명
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 2. ORDER BY DESC로 내림차순으로 정렬하기
|
||||
- `ORDER BY` 구에 지정한 열의 값에 따라 행의 순서가 바뀐다.
|
||||
- 기본적으로는 오름차순으로 정렬된다.
|
||||
- 내림차순으로 정렬할 때는 열명 뒤에 `DESC`를 붙여 지정한다.
|
||||
|
||||
**`내림차순으로 정렬`**
|
||||
```
|
||||
SELECT 열명 FROM 테이블명 ORDER BY 열명 DESC
|
||||
```
|
||||
|
||||
- 오름차순으로 정렬할 때는 내림차순과 달리 생략 가능하며 `ASC`로도 지정할 수 있다.
|
||||
|
||||
**`오름차순으로 정렬`**
|
||||
```
|
||||
SELECT 열명 FROM 테이블명 ORDER BY 열명 ASC
|
||||
```
|
||||
|
||||
- `DESC`는 `descendant(하강)`, `ASC`는 `ascendant(상승)`의 약자이다.
|
||||
|
||||
##### DESC로 내림차순 정렬한다!
|
||||
##### ASC로 오름차순 정렬한다!
|
||||
|
||||
- `ASC`나 `DESC`로 정렬방법을 지정하지 않은 경우에는 `ASC`로 간주되며, 즉 `ORDER BY`의 기본 정렬방법은 오름차순이다.
|
||||
|
||||
---
|
||||
|
||||
## 3. 대소관계
|
||||
- `ORDER BY`로 정렬할 때는 값의 대소관계가 중요하다.
|
||||
- 수치형 데이터라면 대소관계는 숫자의 크기로 판별하므로 이해하기 쉽다.
|
||||
- 날짜시간형 데이터도 수치형 데이터와 마찬가지로 숫자 크기로 판별한다.
|
||||
- 문자열형 데이터의 경우에는 알파벳이나 한글 자모음 배열순서를 사용하면 문자를 차례대로 나열할 수 있다.
|
||||
- 알파벳, 한글 순이며 한글은 자음, 모음 순이다.
|
||||
|
||||
##### 문자열형 데이터의 대소관계는 사전식 순서에 의해 결정된다!
|
||||
|
||||
### 사전식 순서에서 주의할 점
|
||||
- 수치형과 문자열은 대소관계 계산 방법이 서로 다르다.
|
||||
- 수치형은 수치형의 대소관계로, 문자열형은 사전식 순서로 비교한다.
|
||||
- 문자열형 열에 숫자 데이터를 넣을 수 있다(숫자도 문자의 일종이므로 저장하는 데 아무런 문제가 되지 않는다).
|
||||
- 하지만 문자열형 열에 숫자를 저장하면 문자로 인식되어 대소관계의 계산 방법이 달라지므로 정렬이나 비교 연산을 할 때는 이 점에 주의해야 한다.
|
||||
|
||||
##### 수치형과 문자열형 데이터는 대소관계의 계산 방법이 다르다!
|
||||
|
||||
---
|
||||
|
||||
## 4. ORDER BY는 테이블에 영향을 주지 않는다.
|
||||
- `ORDER BY`를 이용해 행 순서를 바꿀 수 있다.
|
||||
- 하지만 이는 서버에서 클라이언트로 행 순서를 바꾸어 결과를 반환하는 것뿐, 저장장치에 저장된 데이터의 행 순서를 변경하는 것은 아닙니다.
|
||||
- `SELECT` 명령은 데이터를 검색하는 명령이다. 이는 테이블의 데이터를 참조만 할 뿐이며 변경은 하지 않는다.
|
||||
|
||||
---
|
||||
59
도서/SQL첫걸음/Lecture10.md
Normal file
@@ -0,0 +1,59 @@
|
||||
# 10강. 복수의 열을 지정해 정렬하기
|
||||
**`ORDER BY 구`**
|
||||
```
|
||||
SELECT 열명 FROM 테이블명 WHERE 조건식
|
||||
ORDER BY 열명1 [ASC | DESC], 열명2 [ASC | DESC]...
|
||||
```
|
||||
|
||||
- 데이터양이 많을 경우 하나의 열만으로는 행을 특정짓기 어려운 때가 많다.
|
||||
- 이런 경우 복수의 열을 지정해 정렬하면 편리하다.
|
||||
- 정렬 시에는 `NULL` 값에 주의해야 한다.
|
||||
|
||||
---
|
||||
|
||||
## 1. 복수 열로 정렬 지정
|
||||
- 데이터베이스 서버 당시 상황에 따라 어떤 순서로 행을 반환할지 결정된다.
|
||||
- 따라서 언제나 같은 손서로 결과를 얻고 싶다면 반드시 `ORDER BY` 구로 순서를 지정해야 한다.
|
||||
- `ORDER BY` 구를 지정해도 1개의 열만으로는 정확히 순서를 결정할 수 없는 경우가 많다(같은 값이 들어가 있는 경우).
|
||||
|
||||
### ORDER BY로 복수 열 지정하기
|
||||
- `ORDER BY` 구에는 복수로 열을 지정할 수 있다.
|
||||
- `SELECT` 구에서 열을 지정한 것처럼 `콤마(,)`로 열명을 구분해 지정하면 된다.
|
||||
|
||||
**`복수 열로 정렬하기`**
|
||||
```
|
||||
SELECT 열명 FROM 테이블명 ORDER BY 열명1, 열명2 ...
|
||||
```
|
||||
|
||||
- 복수 열을 지정하면 정렬 결과가 바뀐다.
|
||||
- 정렬 순서는 지정한 열명의 순서를 따른다.
|
||||
- 값이 같아 순서를 결정할 수 없는 경우에는 다음으로 지정한 열명을 기준으로 정렬하는 식으로 처리된다.
|
||||
|
||||
##### ORDER BY 구에 복수의 열을 지정할 수 있다!
|
||||
|
||||
---
|
||||
|
||||
## 2. 정렬방법 지정하기
|
||||
- 복수열을 지정한 경우에도 각 열에 대해 개별적으로 정렬방법을 지정할 수 있다.
|
||||
- 이때는 각 열 뒤에 `ASC`나 `DESC`를 붙여준다.
|
||||
|
||||
**`복수 열 정렬`**
|
||||
```
|
||||
SELECT 열명 FROM 테이블명
|
||||
ORDER BY 열명1 [ASC | DESC], 열명2 [ASC | DESC] ...
|
||||
```
|
||||
|
||||
- 구문 중에 `[]` 부분은 생략할 수 있다. `|`는 둘 중 하나라는 뜻이며 `...`는 동일한 형태로 연속해서 지정할 수 있다는 의미이다.
|
||||
- 이를 활용해 각 열의 정렬방법을 다르게 지정할 수 있다.
|
||||
- 복수 열을 지정하는 경우에도 정렬방법을 생략하면 기본값은 `ASC`가 된다.
|
||||
|
||||
---
|
||||
|
||||
## 3. NULL 값의 정렬순서
|
||||
- `NULL`에 관해서는 그 특성상 대소비교를 할 수 없어 정렬 시에는 별도의 방법으로 취급한다.
|
||||
- 이때 `특정 값보다 큰 값`, `특정 값보다 작은 값`의 두 가지로 나뉘며 이 중 하나의 방법으로 대소를 비교한다.
|
||||
- 간단히 말하면, `ORDER BY`로 지정한 열에서 `NULL` 값을 가지는 행은 `가장 먼저 표시`되거나 `가장 나중에 표시`된다.
|
||||
- `NULL`에 대한 대소비교 방법은 표준 SQL에도 규정되어 있지 않아 데이터베이스 제품에 따라 기준이 다르다.
|
||||
- `MySQL`의 경우는 `NULL` 값을 가장 작은 값으로 취급해 `ASC(오름차순)`에서는 가장 먼저, `DESC(내림차순)`에서는 가장 나중에 표시한다.
|
||||
|
||||
---
|
||||
73
도서/SQL첫걸음/Lecture11.md
Normal file
@@ -0,0 +1,73 @@
|
||||
# 11강. 결과 행 제한하기 - LIMIT
|
||||
**`LIMIT 구`**
|
||||
```
|
||||
SELECT 열명 FROM 테이블명 LIMIT 행수 [OFFSET 시작행]
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 1. 행수 제한
|
||||
- `LIMIT` 구는 표준 SQL은 아니다.
|
||||
- `MySQL`과 `PostgreSQL`에서 사용할 수 있는 문법이라는 것에 주의하자.
|
||||
- `LIMIT` 구는 `SELECT` 명령의 마지막에 지정하는 것으로 `WHERE` 구나 `ORDER BY` 구의 뒤에 지정한다.
|
||||
|
||||
**`LIMIT 구`**
|
||||
```
|
||||
SELECT 열명 FROM 테이블명 WHERE 조건식 ORDER BY 열명 LIMIT 행수
|
||||
```
|
||||
|
||||
- `LIMIT` 다음에는 최대 행수를 수치로 지정한다.
|
||||
- 지정된 수치만큼 행이 반환된다.
|
||||
|
||||
##### LIMIT 구로 반환될 행수를 제한할 수 있다!
|
||||
|
||||
### 정렬한 후 제한하기
|
||||
- `LIMIT`와 `WHERE`은 기능과 내부처리 순서가 전혀 다르다.
|
||||
- `LIMIT`는 반환할 행수를 제한하는 기능으로, `WHERE` 구로 검색한 후 `ORDER BY`로 정렬된 뒤 최종적으로 처리된다.
|
||||
|
||||
### LIMIT를 사용할 수 없는 데이터베이스에서의 행 제한
|
||||
- `LIMIT`는 표준 SQL이 아니기 때문에 `MySQL`과 `PostgreSQL` 이외의 데이터베이스에서는 사용할 수 없다.
|
||||
- `SQL Server`에서는 `LIMIT`와 비슷한 기능을 하는 `TOP`을 사용할 수 있다.
|
||||
- 다음과 같이 `TOP` 뒤에 최대 행수를 지정하면 된다.
|
||||
|
||||
```
|
||||
SELECT TOP 3 * FROM sample33;
|
||||
```
|
||||
|
||||
- `Oracle`에서는 `LIMIT`도 `TOP`도 없다.
|
||||
- 대신 `ROWNUM`이라는 열을 사용해 `WHERE` 구로 조건을 지정하여 행을 제한할 수 있다.
|
||||
|
||||
```
|
||||
SELECT * FROM sample33 WHERE ROWNUM <= 3;
|
||||
```
|
||||
|
||||
- `ROWNUM`은 클라이언트에게 결과가 반환될 때 각 행에 할당되는 행 번호이다.
|
||||
- 단, `ROWNUM`으로 행을 제한할 때는 `WHERE` 구로 지정하므로 정렬하기 전에 처리되어 `LIMIT`로 행을 제한한 경우와 결괏값이 다르다.
|
||||
|
||||
---
|
||||
|
||||
## 2. 오프셋 지정
|
||||
- 웹 시스템에서는 클라이언트의 브라우저를 통해 페이지 단위로 화면에 표시할 내용을 처리한다.
|
||||
- 이때 일반적으로 페이지 나누기 기능을 사용한다.
|
||||
- 페이지 나누기 기능은 `LIMIT`를 사용해 간단히 구현할 수 있다.
|
||||
- 한 페이지당 5건의 데이터를 표시하도록 한다면 첫 번째 페이지의 경우 `LIMIT 5`로 결괏값을 표시하면 된다.
|
||||
- 그 다음 페이지에서는 6번째 행부터 5건의 데이터를 표시하도록 한다.
|
||||
- 이때 '6번째 행부터'라는 표현은 결괏값으로부터 데이터를 취득할 위치를 가리키는 것으로, `LIMIT` 구에 `OFFSET`으로 지정할 수 있다.
|
||||
- `LIMIT 5 OFFSET 5`로 6번째 행부터 5건을 표시할 수 있다.
|
||||
- `LIMIT` 구의 `OFFSET`은 생략 가능하며 기본값은 0이다.
|
||||
- `OFFSET`에 의한 시작 위치 지정은 `LIMIT` 뒤에 기술한다.
|
||||
- 위치 지정은 컴퓨터 자료구조의 배열 인덱스와 비슷하여, `시작할 행 - 1`로 기억해 두면 편리하다.
|
||||
- 예를 들어 첫 번째 행부터 5건을 취득한다면, `1 - 1`로 위치는 0이 되어 `OFFSET 0`으로 지정하면 된다.
|
||||
|
||||
**`OFFSET 지정`**
|
||||
```
|
||||
SELECT 열명 FROM 테이블명 LIMIT 행수 OFFSET 위치
|
||||
```
|
||||
|
||||
```
|
||||
첫 번째 페이지 -> SELECT * FROM sample33 LIMIT 3 OFFSET 0;
|
||||
두 번째 페이지 -> SELECT * FROM sample33 LIMIT 3 OFFSET 3;
|
||||
위와 같이 사용한다.
|
||||
|
||||
---
|
||||
|
||||
208
도서/SQL첫걸음/Lecture12.md
Normal file
@@ -0,0 +1,208 @@
|
||||
# 12강. 수치 연산
|
||||
**`산술연산`**
|
||||
```
|
||||
+ - * / % MOD
|
||||
```
|
||||
|
||||
- 어떤 계산을 할지는 연산자를 이용해 지정한다.
|
||||
- `WHERE` 구에서 조건을 지정할 때 사용했던 `=` 역시 연산자의 하나이다.
|
||||
|
||||
## 1. 사칙연산
|
||||
- 덧셈, 뺄셈, 곱셈, 나눗셈의 사칙 연산과 나눗셈의 나머지
|
||||
|
||||
|연산자|연산|예|
|
||||
|-|-|-|
|
||||
|+|덧셈(가산)|1+2 -> 3|
|
||||
|-|뺄셈(감산)|1-2 -> -1|
|
||||
|\*|곱셈(승산)|1*2 -> 2|
|
||||
|/|나눗셈(제산)|1/2 -> 0.5|
|
||||
|%|나머지|1%2 -> 1|
|
||||
|
||||
- 곱셈은 `x` 기호를 사용하지만 컴퓨터 언어에서는 `x` 기호가 존재하지 않아 대신 `애스터리스크(*)`를 사용한다.
|
||||
- `*`는 `모든 열`을 의미하는 메타 문자이지만 연산자로도 사용할 수 있다.
|
||||
- 컴퓨터 언어에서는 나눗셈 기호로 `슬래시(/)`를 사용한다.
|
||||
- 나머지는 나눗셈을 한 후의 나머지를 계산하는 것으로 `%` 기호를 사용한다.
|
||||
- 나머지 연산의 결과는 몫이 정수값이 되도록 계산하는 것이 특징이다.
|
||||
- 제품에 따라서는 `%` 대신 `MOD` 함수를 사용하는 경우도 있다.
|
||||
|
||||
##### 연산자를 사용해 여러 가지 연산을 할 수 있다!
|
||||
|
||||
### 연산자의 우선순위
|
||||
|우선순위|연산자|
|
||||
|-|-|
|
||||
|1|* / % |
|
||||
|2|+ -|
|
||||
|
||||
- 곱셈, 나눗셈, 나머지 그룹과 덧셈, 뺄셈 그룹으로 나뉜다.
|
||||
- 같은 그룹 내 연산자의 우선 순위는 동일하다.
|
||||
- 계산 순서는 연산자에 따라 관계없는 경우도 있지만 기본적으로 왼쪽에서 오른쪽으로 진행된다.
|
||||
- 우선순위가 같은 연산자들끼리 연산하는 경우는 문제가 되지 않지만 우선순위가 다른 연산자들이 섞여있는 경우는 우선순위가 높은 쪽이 먼저 계산된다.
|
||||
- `SQL` 명령에서는 여러 부분에서 산술 연산자를 사용해 연산할 수 있다.
|
||||
- `SELECT` 구나 `WHERE` 구 안에서도 연산할 수 있다.
|
||||
|
||||
---
|
||||
|
||||
## 2. SELECT 구로 연산하기
|
||||
- `SELECT` 구에는 열명 외에도 여러 가지 식을 기술할 수 있다.
|
||||
- 이때의 식은 열명, 연산자, 상수로 구성된다.
|
||||
|
||||
**`SELECT 구`**
|
||||
```
|
||||
SELECT 식 1, 식 2 ... FROM 테이블명
|
||||
```
|
||||
|
||||
- 식을 기술할 수 있다는 건 명령이 실행될 때 연산을 할 수 있다는 것을 의미한다.
|
||||
|
||||
```
|
||||
SELECT *, price * quantity FROM sample34;
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 3. 열의 별명
|
||||
- 만약 열 이름이 길고 알아보기 어려운 경우는 별명을 붙여 열명을 재지정할 수 있다.
|
||||
|
||||
**`SELECT 구에서 식에 별명 붙이기`**
|
||||
```
|
||||
SELECT *, price * quantity AS amount FROM sample34;
|
||||
```
|
||||
|
||||
- 별명은 `예약어(AS)`를 사용해 지정한다.
|
||||
- `SELECT` 구에서는 `콤마(,)`로 구분해 복수의 식을 지정할 수 있으며, 각각의 식에 별명을 붙일 수 있다.
|
||||
- 별명을 지정할 때는 기본적으로 중복되지 않게 지정해야 한다(프로그래밍 언어에서 결괏값의 처리 방식에 따라 문제가 발생할 수 있다).
|
||||
- 키워드 `AS`는 생략할 수 있다. `SELECT price * quantity amount`라고 써도 무방하다.
|
||||
- `에일리어스(alias)`라고도 불리는 별명은 영어, 숫자, 한글 등으로 지정할 수 있다.
|
||||
- 단, 별명을 한글로 지정하는 경우에는 여러 가지로 오작동하는 경우가 많으므로 `더블쿼트(MySQL에서는 백쿼트)`로 둘러싸서 지정한다.
|
||||
- 이 룰은 데이터베이스 객체의 이름에 `ASCII` 문자 이외의 것을 사용할 경우에 해당한다.
|
||||
|
||||
```
|
||||
SELECT price * quantity "금액" FROM sample34;
|
||||
```
|
||||
|
||||
##### 이름에 ASCII 문자 이외의 것을 포함할 경우는 더블쿼트로 둘러싸서 지정한다!
|
||||
|
||||
- 더블쿼트로 둘러싸면 명령구문을 분석할 때 데이터베이스 객체의 이름이라고 간주한다.
|
||||
- 싱글쿼트로 둘러싸는 것은 문자열 상수이다.
|
||||
- 별명을 `예약어와 같은 이름은 지정할 수 없다`고 했지만 더블쿼트로 둘러싸서 지정하면 사용할 수 있다.
|
||||
|
||||
```
|
||||
SELECT price * quantity AS "SELECT" FROM sample34;
|
||||
```
|
||||
|
||||
- 이름을 붙일 때는 숫자로 시작할 수 없다.
|
||||
- 수치형 상수를 명령 안에서 사용할 경우에는 쿼트로 묶지 않고 숫자만 입력한다.
|
||||
- 이때 이름이 숫자로 시작한다면 그것이 수치형 상수를 의미하는 것인지 데이터베이스 객체명을 의미하는 것인지 구별할 수 없다.
|
||||
- 그에 따라 데이터베이스 객체명은 `숫자로 시작해서는 안 된다.`
|
||||
- 물론 이름이 예약어와 겹칠 때와 마찬가지로 더블쿼트로 묶으면 피할 수 있다.
|
||||
- `MySQL`에서는 숫자로 시작하는 객체명이 허용된다.
|
||||
- 다만 숫자만으로 구성되는 객체명은 허용되지 않는다.
|
||||
- 한편 `Oracle`에서는 숫자로 시작하는 이름은 허용되지 않는다.
|
||||
- 더블쿼트로 둘러싸면 객체명으로 간주하는 룰은 표준 SQL에 규정되어 있다.
|
||||
|
||||
##### 이름을 지정하는 경우 숫자로 시작되지 않도록 한다!
|
||||
|
||||
---
|
||||
|
||||
## 4. WHERE 구에서 연산하기
|
||||
- `SELECT` 구에 이어, 지금부터는 `WHERE` 구에서의 연산 또한 가능하다.
|
||||
- `WHERE` 구의 조건식은 `price * quantity`일 때, `price * quantity`로 금액을 계산해 그 값이 2000 이상인 행을 검색하라는 뜻이다.
|
||||
- 여기서 `price * quantity`를 계산할 때 `SELECT` 구에서 `amount`라는 별명을 붙였으므로 `WHERE` 구에도 `amount`로 지정하면 될 것 같지만 실제로 `SELECT` 명령을 실행해보면 `amount`라는 열은 존재하지 않는다는 에러가 발생한다.
|
||||
|
||||
```
|
||||
SELECT *, price * quantity AS amount FROM sample34
|
||||
WHERE amount >= 2000;
|
||||
```
|
||||
|
||||
### WHERE 구와 SELECT 구의 내부처리 순서
|
||||
- `WHERE` 구에서의 행 선택, `SELECT` 구에서의 열 선택은 데이터베이스 서버 내부에서 `WHERE 구 -> SELECT 구`의 순서로 처리된다.
|
||||
- 표준 SQL에는 내부 처리 순서가 따로 정해져있지 않다. 하지만 `WHERE 구 -> SELECT 구` 순서로 내부처리를 하는 데이터베이스가 많다.
|
||||
- 따라서 `WHERE` 구로 행이 조건에 일치하는지 아닌지를 먼저 조사한 후에 `SELECT` 구에 지정된 열을 선택해 결과로 반환하는 식으로 처리한다.
|
||||
- 별명은 `SELECT` 구문을 내부 처리할 때 비로소 붙여진다.
|
||||
- 즉, `WHERE` 구의 처리는 `SELECT` 구보다 선행되므로 `WHERE` 구에서 사용한 별칭은 아직 내부적으로 지정되지 않은 상태가 되어 에러가 발생하는 것이다.
|
||||
|
||||
##### SELECT 구에서 지정한 별명은 WHERE 구 안에서 사용할 수 없다!
|
||||
|
||||
---
|
||||
|
||||
## 5. NULL 값의 연산
|
||||
- `NULL` 값을 이용해 `NULL + 1`과 같은 연산을 하면 어떻게 될까요?
|
||||
- SQL에서는 `NULL` 값이 0으로 처리되지 않는다.
|
||||
- 즉, `NULL + 1`의 결괏값은 1이 아닌 `NULL`이다.
|
||||
- 나눗셈을 할때도 `NULL`이 0으로 처리되지 않는다는 것을 알 수 있다.
|
||||
- 따라서 `1 / NULL`을 계산해도 `NULL`이 0으로 처리되지 않아 에러가 발생하지 않고 결과는 `NULL`이 된다.
|
||||
|
||||
##### NULL로 연산하면 결과는 NULL이 된다!
|
||||
|
||||
---
|
||||
|
||||
## 6. ORDER BY 구에서 연산하기
|
||||
- `ORDER BY` 구에서도 연산할 수 있고 그 결괏값들을 정렬할 수 있다.
|
||||
|
||||
```
|
||||
SELECT *, price * quantity AS amount FROM sample34 ORDER BY price * quantity DESC;
|
||||
```
|
||||
|
||||
- 위 명령어를 실행하면 `amount` 값이 내림차순으로 정렬된다.
|
||||
- `ORDER BY`는 서버에서 내부적으로 가장 나중에 처리된다.
|
||||
- 즉, `SELECT` 구보다 나중에 처리되기 때문에 `SELECT` 구에서 지정한 별명을 `ORDER BY`에서도 사용할 수 있다.
|
||||
|
||||
```
|
||||
WHERE 구 -> SELECT 구 -> ORDER BY 구
|
||||
```
|
||||
|
||||
##### ORDER BY 구에서는 SELECT 구에서 지정한 별명을 사용할 수 있다!
|
||||
|
||||
---
|
||||
|
||||
## 7. 함수
|
||||
- 연산자 외에 함수를 사용해 연산할 수도 있다.
|
||||
- 함수는 다음과 같은 문법으로 표기한다.
|
||||
|
||||
**`함수`**
|
||||
```
|
||||
함수명 (인수1, 인수2 ...)
|
||||
```
|
||||
|
||||
- 연산자는 기호에 따라 연산 방법이 결정된다. 한편 함수는 함수명에 따라 연산 방법이 결정된다.
|
||||
- 연산자는 좌우의 항목이 연산 대상이 된다.
|
||||
- 함수는 계산 대상을 인수로 지정한다.
|
||||
- 이때 인수는 함수명 뒤에 괄호로 묶어 표기한다.
|
||||
- 인수의 수나 구분 방법은 함수에 따라 다르며, 대부분의 함수는 1개 이상의 인수를 가진다.
|
||||
- 인수는 파라미터라고도 부르며, 연산자가 그러하듯 함수 역시 결괏값을 반환한다.
|
||||
- 이를 `함수의 반환값`이라고 부른다.
|
||||
|
||||
```
|
||||
10 % 3 -> 1
|
||||
MOD(10, 3) -> 1
|
||||
```
|
||||
|
||||
##### 함수도 연산자도 표기 방법이 다를 뿐, 같은 것이다!
|
||||
|
||||
---
|
||||
|
||||
## 8. ROUND 함수
|
||||
- 반올림을 하는데 이때 사용되는 것이 `ROUND` 함수이다.
|
||||
|
||||
**`ROUND로 반올림하기`**
|
||||
```
|
||||
SELECT amount, ROUND(amount) FROM sample34;
|
||||
```
|
||||
|
||||
- `INTEGER` 형의 경우는 정수밖에 저장할 수 없기 때문에 소수점이 포함되는 열은 `DECIMAL` 형으로 정의한다.
|
||||
- `DECIMAL` 형은 열을 정의할 때 정수부와 소수부의 자릿수를 지정할 수 있는 자료형이다. 다시 말해 소수점을 포함하는 수치를 저장하는 자료형이다.
|
||||
|
||||
### 반올림 자릿수 지정
|
||||
- `ROUND` 함수는 기본적으로 소수점 첫째 자리를 기준으로 반올림한 값을 반환한다.
|
||||
- 이때 `ROUND` 함수의 두 번째 인수로 반올림할 자릿수를 지정할 수 있다.
|
||||
- 해당 인수를 생략하는 경우는 0으로 간주되어, 소수점 첫째 자리를 반올림한다. 1을 지정하면 소수점 둘째 자리를 반올림한다.
|
||||
|
||||
```
|
||||
SELECT amount, ROUND(amount, 1) FROM sample341;
|
||||
```
|
||||
|
||||
- 음수로 지정해 정수부의 반올림할 자릿수도 지정할 수 있다.
|
||||
- `-1`을 지정하면 1단위, `-2`를 지정하면 10단위를 반올림할 수 있다.
|
||||
- 그 밖에도 반올림 외에 `버림`을 하는 경우도 있는데 이는 `TRUNCATE` 함수로 계산할 수 있다.
|
||||
- 이 외에도 다양한 함수가 존재한다(`SIN`, `COS`, `SQRT`, `LOG`, `SUM` 등).
|
||||
|
||||
---
|
||||
105
도서/SQL첫걸음/Lecture13.md
Normal file
@@ -0,0 +1,105 @@
|
||||
# 13강. 문자열 연산
|
||||
|
||||
**`문자열 연산`**
|
||||
```
|
||||
+ || CONCAT SUBSTRING TRIM CHARACTER_LENGTH
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 1. 문자열 결합
|
||||
- 문자열 결합이란 다음과 같이 문자열 데이터를 결합하는 연산이다.
|
||||
|
||||
**`문자열 결합 사례`**
|
||||
```
|
||||
'ABC' || '1234' -> 'ABC1234'
|
||||
```
|
||||
|
||||
- 문자열을 결합하는 연산자에는 데이터베이스 제품마다 방언이 있으며 다음과 같은 차이를 가진다.
|
||||
|
||||
|연산자/함수|연산|데이터베이스|
|
||||
|-|-|-|
|
||||
|+|문자열 결합|SQL Server|
|
||||
|\|\||문자열 결합|Oracle, DB2, PostgreSQL|
|
||||
|CONCAT|문자열 결합|MySQL|
|
||||
|
||||
- `SQL Server`는 문자열 결합에 `+` 연산자를 사용한다.
|
||||
- `Oracle`이나 `DB2`, `PostgreSQL`에서는 `||` 연산자를 사용해서 문자열을 결합한다.
|
||||
- `MySQL`에서는 `CONCAT` 함수로 문자열을 결합한다.
|
||||
|
||||
##### + 연산자, || 연산자, CONCAT 함수로 문자열을 결합할 수 있다!
|
||||
|
||||
- 문자열 결합은 `2개의 열 데이터를 모아서 1개의 열로 처리하고 싶은` 경우에 자주 사용한다.
|
||||
|
||||
```
|
||||
SELECT CONCAT(quantity, unit) FROM sample35;
|
||||
```
|
||||
|
||||
- `sample35`의 `unit` 열은 문자열형이고 `quantity` 열은 `INTEGER` 형의 열이다.
|
||||
- 문자열 결합이지만 수치 데이터도 문제없이 연산할 수 있다.
|
||||
- 단, 문자열로 결합한 결과는 문자열형이 된다.
|
||||
|
||||
---
|
||||
|
||||
## 2. SUBSTRING 함수
|
||||
- `SUBSTRING` 함수는 문자열의 일부분을 계산해서 반환해주는 함수이다. 데이터베이스에 따라서는 함수명이 `SUBSTR`인 경우도 있다.
|
||||
|
||||
```
|
||||
앞 4자리(년) 추출
|
||||
SUBSTRING('20140125001', 1, 4) -> '2014'
|
||||
|
||||
5째 자리부터 2자리(월) 추출
|
||||
SUBSTRING('20140125001', 5, 2) -> '01'
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 3. TRIM 함수
|
||||
- `TRIM` 함수는 문자열의 앞뒤로 여분의 스페이스가 있을 때 이를 제거해주는 함수로 문자열 도중에 존재하는 스페이스는 제거되지 않는다.
|
||||
- 고정길이 문자열형에 대해 많이 사용하는 함수이다.
|
||||
- `CHAR` 형의 문자열형에서는 문자열의 길이가 고정되며 남은 공간은 스페이스로 채워진다.
|
||||
- 이처럼 빈 공간을 채우기 위해 사용한 스페이스를 제거하는 데 `TRIM` 함수를 사용할 수 있다.
|
||||
- 한편, 인수를 지정하는 것으로 스페이스 이외의 문자를 제거할 수도 있다.
|
||||
|
||||
**`TRIM으로 스페이스 제거하기`**
|
||||
```
|
||||
TRIM('ABC ) -> 'ABC
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 4. CHARACTER_LENGTH 함수
|
||||
- `CHARACTER_LENGTH` 함수는 문자열의 길이를 계산해 돌려주는 함수이다.
|
||||
- `VARCHAR` 형의 문자열은 가변 길이이므로 길이가 서로 다르다.
|
||||
- `CHARACTER_LENGTH` 함수를 사용하면 문자열의 길이를 계산할 수 있다.
|
||||
- 문자열의 길이는 문자 단위로 계산되어 수치로 반환된다.
|
||||
- 또한 함수형은 `CHARACTER_LENGTH`로 줄여서 사용할 수 있다.
|
||||
- 한편 `OCTET_LENGTH` 함수는 문자열의 길이를 바이트 단위로 계산해 돌려주는 함수이다.
|
||||
- 데이터 단위로 `바이트`라는 것이 있다. `SQL`의 `OCTET_LENGTH` 함수를 잘 사용하는 동시에 중요한 것은 문자 하나의 데이터가 몇 바이트의 저장공간을 필요로 하는지 `인코드 방식`에 따라 결정된다는 점이다.
|
||||
- 문자를 수치화(인코드) 하는 방식에 따라 필요한 저장공간의 크기가 달라진다.
|
||||
- `VARCHAR` 형의 최대 길이 역시 바이트 단위로 지정한다. 하지만 `문자세트`에 따라 길이가 문자 수로 간주되기도 하니 주의해야 한다.
|
||||
|
||||
### 문자세트(character set)
|
||||
- 알파벳의 경우는 반각문자, 한글은 전각문자라고 할 수 있다.
|
||||
- 반각문자는 전각문자 폭의 절반밖에 안 되며 저장용량 또한 전각문자 쪽이 더 크다.
|
||||
- 반각의 알파벳이나 숫자, 기호는 `ASCII 문자`라고 불린다.
|
||||
- 한글의 경우 `EUC-KR`, `UTF-8` 등의 인코드 방식을 주로 사용한다. 인코드 방식은 데이터베이스나 테이블을 정의할 때 변경할 수 있다.
|
||||
- 이를 `RDBMS`에서는 `문자세트`라고 부른다.
|
||||
- `한 문자가 몇 바이트인지는 쓰이는 문자세트에 따라 다르다`
|
||||
- `CHAR_LENGTH` 함수를 사용하는 경우에는 아무런 문제가 되지 않는다. 한글이든 `ASCII` 문자든 문자 수로 계산되기 때문이다.
|
||||
- 하지만 `OCTET_LENGTH` 함수의 경우는 문자 수가 아닌 바이트 단위로 길이를 계산하므로 주의해야 한다.
|
||||
|
||||
`표 3-4. 문자세트 별 문자 수와 바이트 수`
|
||||
|문자세트|문자 수|바이트 수|
|
||||
|-|-|-|
|
||||
|EUC-KR|12|19
|
||||
|UTF-8|12|26|
|
||||
|
||||
- `EUC-KR`에서 `ASCII` 문자는 1바이트, 한글은 2바이트의 용량을 가진다.
|
||||
- 한편 `UTF-8`에서 `ASCII` 문자는 1아티으, 한글은 3바이트의 용량을 가진다.
|
||||
- 즉, 문자세트에 따라 한 문자의 크기는 달라진다.
|
||||
- 문자열 조작 함수로 문자 단위가 아닌 바이트 단위로 지정할 경우에는 문자세트에 주의해야 한다.
|
||||
|
||||
##### 문자열 데이터의 길이는 문자세트에 따라 다르다!
|
||||
|
||||
---
|
||||
73
도서/SQL첫걸음/Lecture14.md
Normal file
@@ -0,0 +1,73 @@
|
||||
# 14강. 날짜 연산
|
||||
|
||||
**`날짜 연산`**
|
||||
```
|
||||
CURRENT_TIMESTAMP CURRENT_DATE INTERVAL
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 1. SQL에서의 날짜
|
||||
- 날짜나 시간 데이터는 수치 데이터와 같이 사칙 연산을 할 수 있다.
|
||||
- 날짜시간 데이터를 연산하면 결괏값으로 동일한 날짜시간 유형의 데이터를 변환하는 경우도 있으며 기간(간격)의 차를 나타내는 `기간형(interval)` 데이터를 반환하는 경우도 있다.
|
||||
- 기간형은 `10일간`, `2시간10분`과 같이 시간의 간격을 표현할 수 있다.
|
||||
|
||||
### 시스템 날짜
|
||||
- `시스템 날짜`란 이 같은 하드웨어 상의 시계로부터 실시간으로 얻을 수 있는 일시적인 데이터를 말한다. `RDBMS`에서도 시스템 날짜와 시간을 확인하는 함수를 제공한다.
|
||||
- 표준 SQL에서는 `CURRENT_TIMESTAMP`라는 긴 이름의 함수로 실행했을 때를 기준으로 시간을 표시한다.
|
||||
- `CURRENT_TIMESTAMP`는 함수임에도 인수를 필요로 하지 않는다.
|
||||
- 일반적인 함수와는 달리 인수를 지정할 필요가 없으므로 괄호를 사용하지 않는 특수한 함수이다.
|
||||
|
||||
**`시스템 날짜 확인하기`**
|
||||
```
|
||||
SELECT CURRENT_TIMESTAMP;
|
||||
```
|
||||
|
||||
- 위의 예에서는 `FROM` 구를 생략했다. `SELECT` 구현만으로도 `SELECT` 명령은 실행됩니다만 `Oracle`과 같은 전통적인 데이터베이스에서는 `FROM` 구를 생략할 수 없으므로 주의해야 한다.
|
||||
- `CURRENT_TIMESTAMP`는 표준 SQL로 규정되어 있는 함수이다.
|
||||
- `Oracle`에서는 `SYSDATE` 함수, `SQL Server`에서는 `GETDATE` 함수를 사용해도 시스템 날짜를 확인할 수 있다. 그러나 이들은 표준화되기 전에 구현된 함수인 만큼 사용하지 않는 편이 낫다.
|
||||
|
||||
### 날짜 서식
|
||||
- 날짜 데이터를 데이터베이스에 저장할 경우 `CURRENT_TIMESTAMP`를 사용해 시스템 상의 날짜를 저장할 수 있다.
|
||||
- 다만 임의의 날짜를 저장하고 싶을 경우에는 직접 날짜 데이터를 지정해야 한다.
|
||||
- 날짜 서식은 국가별로 다르다. 한국과 일본에서는 연월일을 슬래시나 하이픈으로 구분해 표기하는 경우가 많다.
|
||||
- 한편 미국에서는 월의 경우 숫자를 대신해 `Jan`, `Feb` 등으로 표기하며 일반적으로 일월년의 순으로 표기한다.
|
||||
- 0214/01/25
|
||||
- 2014-01-25
|
||||
- 25 Jan 2014
|
||||
- 데이터베이스 제품은 날짜 데이터의 서식을 임의로 지정, 변환할 수 있는 함수를 지원한다.
|
||||
- `Oracle`의 경우 `TO_DATE` 함수를 사용해 문자열 데이터를 날짜형 데이터로 변환할 수 있으며 서식 또한 별도로 지정할 수 있다.
|
||||
|
||||
```
|
||||
TO_DATE('2014/01/25', 'YYYY/MM/DD')
|
||||
```
|
||||
|
||||
- 여기서 `'YYYY/MM/DD'`가 서식 부분이다.
|
||||
- `YYYY`가 년, `MM`이 월, `DD가 날`을 의미한다.
|
||||
- 반대로 날짜형 데이터를 서식에 맞춰 변환해 문자열 데이터로 출력하는 함수도 존재한다.
|
||||
- `Oracle`의 경우 `TO_CHAR` 함수가 그에 해당한다.
|
||||
|
||||
##### 날짜 데이터는 서식을 지정할 수 있다!
|
||||
|
||||
---
|
||||
|
||||
## 2. 날짜의 덧셈과 뺄셈
|
||||
- 날짜시간형 데이터는 기간형 수치데이터와 덧셈 및 뺄셈을 할 수 있다.
|
||||
- 날짜시간형 데이터에 기간형 수치데이터를 더하거나 빼면 날짜시간형 데이터가 반환된다.
|
||||
- 예를 들어 특정일로부터 1일 후를 계산하고 싶다면 `a + 1 DAY` 라는 식으로 계산할 수 있다. 1일 전이라면 `a - 1 DAY`로 하면 된다.
|
||||
|
||||
**`날짜를 연산해 시스템 날짜의 1일 후를 검색`**
|
||||
```
|
||||
SELECT CURRENT_DATE + INTERVAL 1 DAY;
|
||||
```
|
||||
|
||||
- `CURRENT_DATE`는 시스템 날짜의 날짜만 확인하는 함수이다.
|
||||
- `INTERVAL 1 DAY`는 `1일 후`라는 의미의 기간형 상수이다.
|
||||
- 기간형 상수의 기술방법은 데이터베이스마다 조금씩 다르며 세세한 부분까지 표준화가 이루어지지는 않았다. 따라서 데이터베이스의 메뉴얼을 참고해야 한다.
|
||||
|
||||
### 날짜형 간의 뺄셈
|
||||
- 날짜시간형 데이터 간에 뺄셈을 할 수 있다(덧셈도 할 수 있지만 별 의미가 없다).
|
||||
- 예를 들면 `Oracle`에서는 `2014-02-28 - 2014-01-01`이라고 한다면 두 날짜 사이에 차이가 얼마나 발생하는지 계산할 수 있다.
|
||||
- 한편 `MySQL`에서는 `DATEDIFF('2014-02-28', '2014-01-01')`로 계산할 수 있다.
|
||||
|
||||
---
|
||||
158
도서/SQL첫걸음/Lecture15.md
Normal file
@@ -0,0 +1,158 @@
|
||||
# 15강. CASE 문으로 데이터 변환하기
|
||||
- `CASE` 문을 이용해 데이터를 변환할 수 있다.
|
||||
|
||||
**`CASE 문`**
|
||||
```
|
||||
CASE WHEN 조건식1 THEN 식1
|
||||
[WHEN 조건식2 THEN 식2]
|
||||
[ELSE 식3]
|
||||
END
|
||||
```
|
||||
|
||||
- 임의의 조건에 따라 독자적으로 변환 처리를 지정해 데이터로 변환하고 싶은 경우에 `CASE` 문을 이용할 수 있다.
|
||||
|
||||
---
|
||||
|
||||
## 1. CASE 문
|
||||
- `RDBMS`에 갖추어져 있는 기존의 연산자나 함수만으로는 처리할 수 없는 것들이 있다.
|
||||
- 예를 들면 `NULL` 값을 0으로 간주하여 계산하고 싶은 경우라던가.
|
||||
- 하지만 `NULL` 값으로 계산한 결과는 모두 `NULL`이 된다.
|
||||
- `RDBMS`에서는 사용자가 함수를 작성할 수 있다.
|
||||
- 하지만 간단한 처리의 경우에는 사용자 정의 함수를 작성하지 않고도 `CASE` 문으로 처리할 수 있다.
|
||||
|
||||
**`CASE 문`**
|
||||
```
|
||||
CASE WHEN 조건식1 THEN 식1
|
||||
[WHEN 조건식2 THEN 식2]
|
||||
[ELSE 식3]
|
||||
END
|
||||
```
|
||||
|
||||
- 먼저 `WHEN` 절에는 참과 거짓을 반환하는 조건식을 기술한다.
|
||||
- 해당 조건을 만족하여 참이 되는 경우는 `THEN` 절에 기술한 식이 처리된다.
|
||||
- 이때 `WHEN`과 `THEN`을 한데 조합해 사용할 수 있다.
|
||||
- `WHEN` 절의 조건식을 차례로 평가해 나가다가 가장 먼저 조건을 만족한 `WHEN` 절과 대응하는 `THEN` 절 식의 처리결과를 `CASE` 문의 결괏값으로 반환한다.
|
||||
- 그 어떤 조건식도 만족하지 못한 경우에는 `ELSE` 절에 기술한 식이 채택된다.
|
||||
- `ELSE`는 생략 가능하며 생략했을 경우 `ELSE NULL`로 간주된다.
|
||||
|
||||
**`CASE로 NULL 값을 0으로 변환하기`**
|
||||
```
|
||||
SELECT a, CASE WHEN a IS NULL THEN 0 ELSE a END "a(null=0)" FROM sample37;
|
||||
```
|
||||
|
||||
- a 열 값이 `NULL`일 때 `WHEN a IS NULL`은 참이 되므로 `CASE` 문은 `THEN` 절의 '0'을 반환한다.
|
||||
- `NULL`이 아닌 경우에는 `ELSE` 절의 'a', 즉 a 열의 값을 반환한다.
|
||||
|
||||
### COALESCE
|
||||
- 사실 `NULL` 값을 변환하는 경우라면 `COALESCE` 함수를 사용하는 편이 더 쉽다.
|
||||
- 앞의 예제에 `COALESCE` 함수를 사용해 구현하면 다음과 같다.
|
||||
|
||||
```
|
||||
SELECT a, COALESCE(a, 0) FROM sample37;
|
||||
```
|
||||
|
||||
- `COALESCE` 함수는 여러 개의 인수를 지정할 수 있다.
|
||||
- 주어진 인수 가운데 `NULL`이 아닌 값에 대해서는 가장 먼저 지정된 인수의 값을 반환한다.
|
||||
- 앞의 예문은 a가 `NULL`이 아니면 a값을 그대로 출력하고, 그렇지 않으면(a가 `NULL`이면) 0을 출력한다.
|
||||
|
||||
---
|
||||
|
||||
## 2. 또 하나의 CASE 문
|
||||
- 숫자로 이루어진 코드를 알아보기 더 쉽게 문자열로 변환하고 싶은 경우 `CASE` 문을 많이 사용한다.
|
||||
- 이와 같이 문자화하는 것을 `디코드`라 부르고 반대로 수치화하는 것을 `인코드`라 부른다.
|
||||
- 이와 같은 인코드를 `CASE` 문으로 처리할 수 있다.
|
||||
|
||||
```
|
||||
WHEN a = 1 THEN '남자'
|
||||
WHEN a = 2 THEN '여자'
|
||||
```
|
||||
|
||||
##### CASE 문에는 2개의 구문이 있다!
|
||||
|
||||
- `CASE` 문은 `검색 CASE`와 `단순 CASE`의 두 개 구문으로 나눌 수 있다.
|
||||
- `검색 CASE`는 앞서 설명한 `CASE WHEN 조건식 THEN 식 ...` 구문이다.
|
||||
- 한편 `단순 CASE`는 `CASE 식 WHEN 식 THEN 식 ...` 구문이다.
|
||||
- `단순 CASE`에서는 `CASE` 뒤에 식을 기술하고 `WHEN` 뒤에 (조건식이 아닌) 식을 기술한다.
|
||||
|
||||
**`단순 CASE 식`**
|
||||
```
|
||||
CASE 식1
|
||||
WHEN 식2 THEN 식3
|
||||
[WHEN 식4 THEN 식5 ...]
|
||||
[ELSE 식6]
|
||||
END
|
||||
```
|
||||
|
||||
- 식1의 값이 `WHEN`의 식2의 값과 동일한지 비교하고, 값이 같다면 식3의 값이 `CASE` 문 전체의 결괏값이 된다.
|
||||
- 값이 같지 않으면 그 뒤에 기술한 `WHEN` 절과 비교하는 식으로 진행된다.
|
||||
- 즉, 식1의 값과 식4의 값이 같은지를 비교하고 같다면 식5의 값이 `CASE` 문의 결괏값이 되는 것이다.
|
||||
- 비교 결과 일치하는 `WHEN` 절이 하나도 없는 경우에는 `ELSE` 절이 적용된다.
|
||||
|
||||
**`성별 코드 변환하기(검색 CASE)`**
|
||||
```
|
||||
SELECT a AS "코드",
|
||||
CASE
|
||||
WHEN a = 1 THEN '남자'
|
||||
WHEN a = 2 THEN '여자'
|
||||
ELSE '미지정'
|
||||
END AS "성별" FROM sample37;
|
||||
```
|
||||
|
||||
- `검색 CASE`의 경우에는 `WHEN`에 `a = 1`, `a = 2`처럼 식을 상세하게 기술해야 하지만 `단순 CASE`에서는 `CASE` 문에서 비교할 항목인 'a'를 따로 지정하므로 `WHEN`에는 1, 2처럼 비교할 값만 기술하면 된다.
|
||||
|
||||
**`성별 코드 변환하기(단순 CASE)`**
|
||||
```
|
||||
SELECT a AS "코드",
|
||||
CASE a
|
||||
WHEN 1 THEN '남자'
|
||||
WHEN 2 THEN '여자'
|
||||
ELSE '미지정'
|
||||
END AS "성별" FROM sample37;
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 3. CASE를 사용할 경우 주의사항
|
||||
- `CASE` 문은 어디에나 사용할 수 있다.
|
||||
- `WHERE` 구에서 조건식의 일부로 사용될 수도 있고 `ORDER BY` 구나 `SELECT` 구에서도 사용할 수 있다.
|
||||
|
||||
### ELSE 생략
|
||||
- `ELSE`를 생략하면 `ELSE NULL`이 되는 것에 주의해야 한다.
|
||||
- 상정한 것 이외의 데이터가 들어오는 경우도 많다.
|
||||
- 이때 대응하는 `WHEN`이 하나도 없으면 `ELSE` 절이 사용된다.
|
||||
- 이때 `ELSE`를 생략하면 상정한 것 이외의 데이터가 왔을 때 `NULL`이 반환된다.
|
||||
- 따라서 `ELSE`를 생략하지 않고 지정하는 편이 낫다.
|
||||
|
||||
##### CASE 문의 ELSE는 생략하지 않는 편이 낫다!
|
||||
|
||||
### WHEN에 NULL 지정하기
|
||||
- `단순 CASE`에서는 `WHEN` 뒤에 1개의 상수값을 지정하는 경우가 많다.
|
||||
- 만약 데이터가 `NULL`인 경우를 고려해 `WHEN NULL THEN '데이터 없음'`과 같이 지정해도 문법적으로는 문제가 없지만 정상적으로 처리되지 않는다.
|
||||
- 비교 연산자 `=` 로는 `NULL` 값과 같은지 아닌지를 비교할 수 없다.
|
||||
- 따라서 a열의 값이 `NULL`이라 해도 `a = NULL`은 참이 되지 않는다.
|
||||
- 즉, '데이터 없음' 대신 '미지정'이라는 결괏값이 나온다.
|
||||
- `단순 CASE` 문으로는 `NULL`을 비교할 수 없다는 문제점이 있다.
|
||||
- 이때 `NULL 값인지 아닌지를 판정하기 위해서는 IS NULL을 사용`한다.
|
||||
- 다만 `단순 CASE` 문은 특성상 `=` 연산자로 비교하는 만큼, `NULL` 값인지를 판정하려면 `검색 CASE` 문을 사용해야 한다.
|
||||
|
||||
**`검색 CASE 문으로 NULL 판정하기`**
|
||||
```
|
||||
CASE
|
||||
WHEN a = 1 THEN '남자'
|
||||
WHEN a = 2 THEN '여자'
|
||||
WHEN a IS NULL THEN '데이터 없음'
|
||||
ELSE '미지정'
|
||||
END
|
||||
```
|
||||
|
||||
##### 단순 CASE 문으로는 NULL 값을 비교할 수 없다!
|
||||
|
||||
### DECODE NVL
|
||||
- `Oracle`에는 이 같은 디코드를 수행하는 `DECODE` 함수가 내장되어 있다.
|
||||
- `DECODE` 함수는 `CASE` 문과 같은 용도로 사용할 수 있다.
|
||||
- 다만 `DECODE` 함수는 `Oracle`에서만 지원하는 함수인 만큼 다른 데이터베이스 제품에서는 사용할 수 없다.
|
||||
- 그에 비해 `CASE` 문은 표준 SQL로 규정된 덕분에 많은 데이터베이스 제품이 지원한다.
|
||||
- 또한 `NULL` 값을 변환하는 함수도 있는데 `Oracle`에서는 `NVL` 함수, `SQL Server`에서는 `ISNULL` 함수가 이에 해당한다.
|
||||
- 다만 이 함수들은 특정 데이터베이스에 국한된 함수인 만큼 `NULL` 값을 변환할 때는 표준 SQL로 규정되어 있는 `COALESCE` 함수를 사용하자.
|
||||
|
||||
---
|
||||
94
도서/SQL첫걸음/Lecture16.md
Normal file
@@ -0,0 +1,94 @@
|
||||
# 행 추가하기 - INSERT
|
||||
**`INSERT 명령`**
|
||||
```
|
||||
INSERT INTO 테이블명 VALUES(값 1, 값 2, ...)
|
||||
```
|
||||
- `SELECT` 명령은 데이터 검색을 위한 것으로, 질의를 하면 데이터베이스 서버가 클라이언트로 결과를 반환하는 형식으로 처리된다.
|
||||
- 데이터를 추가할 경우에는 이와 반대로 클라이언트에서 서버로 데이터를 전송하는 형식을 취한며 서버 측은 전송받은 데이터를 데이터베이스에 저장한다.
|
||||
|
||||
---
|
||||
|
||||
## 1. INSERT로 행 추가하기
|
||||
- `RDBMS`에서는 `INSERT` 명령을 사용해 테이블의 행 단위로 데이터를 추가한다.
|
||||
- `INSERT` 명령을 통해 행을 추가하려면 각 열의 값을 지정해야 한다.
|
||||
- 먼저 `INSERT INTO` 뒤에 행을 추가할 테이블을 지정한다.
|
||||
|
||||
```
|
||||
INSERT INTO sample41
|
||||
```
|
||||
|
||||
- 저장할 데이터를 지정하지 않았기 때문에 아직은 `INSERT` 명령문이 완성되지 않은 상태이다.
|
||||
- 행의 데이터는 `VALUES` 구를 사용해 지정한다.
|
||||
|
||||
```
|
||||
INSERT INTO sample41 VALUES(1, 'ABC', '2014-01-25');
|
||||
```
|
||||
|
||||
- 값을 지정할 때는 해당 열의 데이터 형식에 맞도록 지정해야 한다.
|
||||
- 다만, `INSERT` 명령을 실행해도 처리상태만 표시될 뿐 `SELECT` 명령을 실행했을 때처럼 결과를 출력하지는 않는다.
|
||||
- `SELECT` 명령의 경우 실행하면 그 결과가 클라이언트에게 반환되지만, `INSERT` 명령은 데이터가 클라이언트에서 서버로 전송되므로 반환되는 결과가 없는 것이다.
|
||||
|
||||
##### INSERT 명령으로 테이블에 행을 추가할 수 있다!
|
||||
|
||||
---
|
||||
|
||||
## 2. 값을 저장할 열 지정하기
|
||||
- `INSERT` 명령으로 행을 추가할 경우 값을 저장할 열을 지정할 수 있다.
|
||||
- 열을 지정할 경우에는 테이블명 뒤에 괄호로 묶어 열명을 나열하고 `VALUES` 구로 값을 지정한다.
|
||||
- `VALUES` 구에 값을 지정할 경우에는 지정한 열과 동일한 개수로 값을 지정해야 한다.
|
||||
|
||||
**`INSERT의 열 지정`**
|
||||
```
|
||||
INSERT INTO 테이블명 (열1, 열2, ...) VALUES(값1, 값2, ...)
|
||||
```
|
||||
|
||||
- 위의 문법을 적용하면 지정한 열에 값을 넣어 행을 추가할 수 있다.
|
||||
|
||||
---
|
||||
|
||||
## 3. NOT NULL 제약
|
||||
- 행을 추가할 때 유효한 값이 없는 상태(`NULL`)로 두고 싶을 경우에는 `VALUES` 구에서 `NULL`로 값을 지정할 수 있다.
|
||||
- 하지만 `NULL` 값을 허용하지 않는 `NOT NULL 제약`이 걸려있으면 에러가 발생한다.
|
||||
- 이와 같이 테이블에 저장하는 데이터를 성정으로 제한하는 것을 통틀어 `제약`이라 부른다.
|
||||
- `NOT NULL 제약`은 그중 하나로 이 외에도 다양한 제약이 있다.
|
||||
|
||||
##### NOT NULL 제약이 걸려있는 열은 NULL 값을 허용하지 않는다!
|
||||
|
||||
- `NULL`은 여러 측면에서 주의해야 한다.
|
||||
- `NULL`의 조건을 비교할 때는 `IS NULL`을 이용해야 하며 `NULL`을 포함한 연산 결과는 모두 `NULL`이 되어버리기도 한다.
|
||||
- `NULL`을 허용하고 싶지 않다면 `NOT NULL` 제약을 걸어두는 편이 좋다.
|
||||
|
||||
---
|
||||
|
||||
## 4. DEFAULT
|
||||
- `DESC` 명령으로 열 구성을 살펴보면 `Default`라는 항목을 찾을 수 있다.
|
||||
- `Default`는 명시적으로 값을 지정하지 않았을 경우 사용하는 초깃값을 말한다.
|
||||
- `Default` 값은 테이블을 정의할 때 지정할 수 있다. 열을 지정해 행을 추가할 때 지정하지 않은 열은 `Default` 값을 사용하여 저장된다.
|
||||
- 즉, 값을 생략하면 초깃값으로 지정된 `Default` 값으로 저장된다.
|
||||
|
||||
**`값을 생략하지 않고 행 추가하기`**
|
||||
```
|
||||
INSERT INTO sample411(no, d) VALUES(1, 1);
|
||||
```
|
||||
|
||||
- `VALUES` 구에서 `DEFAULT` 키워드를 사용하면 디폴트값이 저장된다.
|
||||
- 아래 예시처럼 디폴트값을 지정하는 것을 `DEFAULT`를 명시적으로 지정하는 방법이라고 한다.
|
||||
|
||||
**`DEFAULT로 값을 지정해 행 추가하기`**
|
||||
```
|
||||
INSERT INTO sample411(no, d) VALUES(2, DEFAULT);
|
||||
```
|
||||
|
||||
### 암묵적으로 디폴트 저장
|
||||
- 암묵적으로 지정하는 방법도 있다.
|
||||
- 여기서 암묵적인 방법이란 디폴트값으로 저장할 열을 `INSERT` 명령문에서 별도 지정하지 않는 것을 말한다.
|
||||
- 그 결과, 명시적 방법과 암묵적 방법 중 어떤 것을 사용해도 지정하지 않은 열의 값이 디폴트로 저장됨을 확인할 수 있다.
|
||||
|
||||
**`암묵적으로 디폴트값을 가지는 행 추가하기`**
|
||||
```
|
||||
INSERT INTO sample411(no) VALUES(3);
|
||||
```
|
||||
|
||||
##### 열을 지정하지 않으면 디폴트값으로 행이 추가된다!
|
||||
|
||||
---
|
||||
41
도서/SQL첫걸음/Lecture17.md
Normal file
@@ -0,0 +1,41 @@
|
||||
# 17강. 삭제하기 - DELETE
|
||||
데이터베이스의 테이블에서 행을 삭제하기 위해서는 `DELETE` 명령을 사용한다.
|
||||
|
||||
**`DELETE 명령`**
|
||||
```
|
||||
DELETE FROM 테이블명 WHERE 조건식
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 1. DELETE로 행 삭제하기
|
||||
- `RDBMS`에서 데이터를 삭제할 경우에는 행 단위로 `DELETE` 명령을 수행한다.
|
||||
|
||||
**`DELETE 명령`**
|
||||
```
|
||||
DELETE FROM 테이블명 WHERE 조건식
|
||||
```
|
||||
|
||||
- `DELETE FROM sample41;` 으로 `DELETE` 명령을 실행하면 `sample41` 테이블의 모든 데이터가 삭제된다.
|
||||
- `DELETE` 명령에는 `WHERE` 구를 지정할 수 있으나 `SELECT` 명령처럼 `WHERE` 구를 생략할 경우에는 모든 행을 대상으로 동작하기 때문이다.
|
||||
- 한편 `WHERE` 구를 지정한 경우에는 해당 조건식에 맞는 행만 삭제 대상이 된다.
|
||||
|
||||
##### DELETE 명령으로 행을 삭제할 수 있다!
|
||||
|
||||
- 삭제는 행 단위로 수행된다.
|
||||
- `SELECT` 명령과 같이 열을 지정할 수는 없다.
|
||||
- 즉, `DELETE no FROM sample41`과 같이 열을 지정하여 그 열만 삭제할 수는 없다.
|
||||
- `DELETE` 명령을 실행할 때는 재확인을 위한 대화창 같은 것은 표시되지 않는다.
|
||||
- 즉, `WHERE` 구에서 조건식을 잘못 지정하면 의도하지 않은 데이터마저 삭제된다.
|
||||
- 따라서 `DELETE` 명령을 실행할 때는 주의를 기울여야 한다.
|
||||
|
||||
##### DELETE 명령은 WHERE 조건에 일치하는 '모든 행'을 삭제한다!
|
||||
|
||||
---
|
||||
|
||||
## 2. DELETE 명령 구
|
||||
- `WHERE` 구에서 대상이 되는 행을 검색하는 것은 `SELECT` 명령에서도 `DELETE` 명령에서도 똑같다.
|
||||
- 단지 `SELECT` 명령에서는 조건에 맞는 행의 결괏값이 클라이언트로 반환되지만, `DELETE` 명령에서는 조건에 맞는 행이 삭제된다는 점만 다르다.
|
||||
- `DELETE` 명령에서도 `SELECT` 명령처럼 `WHERE` 구를 지정할 수 있지만 `ORDER BY` 구는 사용할 수 없다. 어떤 행부터 삭제할 것인지는 중요하지 않으며 의미가 없기 때문이다.
|
||||
|
||||
---
|
||||
119
도서/SQL첫걸음/Lecture18.md
Normal file
@@ -0,0 +1,119 @@
|
||||
# 18강. 데이터 갱신하기 - UPDATE
|
||||
테이블의 셀에 저장되어 있는 값을 갱신하려면 UPDATE 명령을 사용합니다.
|
||||
|
||||
**`UPDATE 명령`**
|
||||
```
|
||||
UPDATE 테이블명 SET 열1 = 값1, 열2= 값2, ... WHERE 조건식
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 1. UPDATE로 데이터 갱신하기
|
||||
- `RDBMS`에서는 `UPDATE` 명령으로 데이터를 갱신할 수 있다.
|
||||
- `UPDATE` 명령을 테이블의 셀 값을 갱신하는 명령이다.
|
||||
|
||||
**`UPDATE 명령`**
|
||||
```
|
||||
UPDATE 테이블명 SET 열명 = 값 WHERE 조건식
|
||||
```
|
||||
|
||||
- `DELETE`와 달리 `UPDATE`는 셀 단위로 데이터를 갱신할 수 있다.
|
||||
- `WHERE` 구에 조건을 지정하면 그에 일치하는 행을 갱신할 수 있다.
|
||||
- `WHERE` 구를 생략한 경우에는 `DELETE`의 경우와 마찬가지로 테이블의 모든 행이 갱신된다.
|
||||
- `UPDATE` 명령에서는 `SET` 구를 사용하여 갱신할 열과 값을 지정한다.
|
||||
- 문법은 `SET 열명 = 값`이다. 이때 `=`은 비교 연산자가 아닌, 값을 대입하는 대입 연산자이다.
|
||||
- 또한 테이블에 존재하지 않는 열을 지정하면 에러가 발생하여 `UPDATE` 명령은 실행되지 않는다.
|
||||
- 값은 상수로 표기한다. `INSERT` 명령과 마찬가지로 자료형에 맞는 값을 지정해야 한다.
|
||||
- 갱신해야 할 열과 값이 복수인 경우에는 `열 = 값`을 `콤마(,)`로 구분하여 리스트 형식으로 지정할 수 있다.
|
||||
- `SET` 구에 지정한 갱신내용은 처리 대상이 되는 모든 행에 적용된다.
|
||||
|
||||
```
|
||||
UPDATE sample41 SET b = '2014-09-07' WHERE no = 2;
|
||||
```
|
||||
- 날짜형의 값을 갖는 열은 날짜의 리터럴로 값을 표기한다.
|
||||
|
||||
##### UPDATE 명령으로 행의 셀 값을 갱신할 수 있다!
|
||||
|
||||
- `UPDATE` 명령의 `WHERE` 조건문 역시 `DELETE` 명령과 마찬가지로 조건에 일치하는 모든 행이 그 대상이 된다.
|
||||
- 그리고 `WHERE` 구를 생략하면 테이블의 모든 행이 갱신 대상이 된다.
|
||||
- 즉, `WHERE` 구를 생략하거나 잘못 지정할 경우 `DELETE` 명령에서 언급한 것처럼 의도하지 않은 처리가 발생할 수 있으므로 주의해야 한다.
|
||||
|
||||
##### UPDATE 명령에서는 WHERE 조건에 일치하는 '모든 행'이 갱신된다!
|
||||
|
||||
---
|
||||
|
||||
## 2. UPDATE로 갱신할 경우 주의사항
|
||||
- `SET` 구에서 `=`은 대입 연산자이다.
|
||||
- `UPDATE` 명령은 이미 존재하는 행에 대해 값을 갱신하므로 이전의 값과 이후의 값의 두 가지 상태를 생각할 수 있다.
|
||||
|
||||
여기에서 다음과 같은 `UPDATE` 명령을 실행하면 어떻게 될까?
|
||||
```
|
||||
UPDATE sample41 SET no = no + 1;
|
||||
```
|
||||
|
||||
- 이 명령문에는 `WHERE` 구가 지정되어 있지 않으므로 갱신 대상은 테이블의 모든 행이 된다.
|
||||
- `SET` 구에서는 `no` 열의 값을 갱신하는데, 갱신 후의 값은 본래 값(갱신 전의 값)에서 1을 더한 결과이다.
|
||||
- 실행을 해보면, 모든 행의 `no` 값에 1씩 더해진 것을 알 수 있다.
|
||||
- 이처럼 갱신할 값을 열이 포함된 식으로도 표기할 수 있다.
|
||||
- 이때 해당 열이 갱신 대상이 되는 열이라 해도 상관없다.
|
||||
- 위의 예시를 간단하게 설명하면 `현재의 no 값에 1을 더한 값으로 no 열을 갱신하라`는 의미이다.
|
||||
- 갱신은 행 단위로 처리되므로 `현재의 no 값`은 그 행이 갱신되기 전의 값에 해당한다.
|
||||
|
||||
---
|
||||
|
||||
## 3. 복수열 갱신
|
||||
- `UPDATE` 명령의 `SET` 구에서는 필요에 따라 `콤마(,)`로 구분하여 갱신할 열을 여러 개 지정할 수 있다.
|
||||
|
||||
**`UPDATE 명령`**
|
||||
```
|
||||
UPDATE 테이블명 SET 열명1 = 값1, 열명2 = 값2, .... WHERE 조건식
|
||||
```
|
||||
|
||||
**`두 구문으로 나누어 UPDATE 명령 실행`**
|
||||
```
|
||||
UPDATE sample41 SET a = 'xxx' WHERE no = 2;
|
||||
UPDATE sample41 SET b = '2014-01-01' WHERE no = 2;
|
||||
```
|
||||
|
||||
**`하나로 묶어서 UPDATE 명령 실행`**
|
||||
```
|
||||
UPDATE sample41 SET a = 'xxx', b = '2014-01-01' WHERE no = 2;
|
||||
```
|
||||
|
||||
### SET 구의 실행 순서
|
||||
- 여러 개의 열을 한 번에 갱신할 수 있어 편리하기는 하지만, 그 전에 `SET` 구는 어떤 순서로 갱신 처리를 하는지 알아둘 필요가 있다.
|
||||
- 예를 들어, 다음과 같은 2개의 `UPDATE` 명령이 있을 때 어떤 순서로 처리되는지 알아보자.
|
||||
|
||||
```
|
||||
UPDATE sample41 SET no = no + 1, a = no; ①
|
||||
UPDATE sample41 SET a = no, no = no + 1; ②
|
||||
```
|
||||
|
||||
- 이 두 `UPDATE` 명령은 `콤마(,)`로 구분된 갱신 식의 순서가 서로 다르다.
|
||||
- 이에 대한 결과는 데이터베이스 제품에 따라서 달라진다.
|
||||
- `MySQL`에서는 서로 다른 결괏값이 나오지만 `Oracle`에서는 어느 명령을 실행해도 결과는 같다.
|
||||
- `MySQL`에서 첫 번째 `UPDATE` 명령을 실행하면 `no` 열과 `a` 열의 값이 서로 같아진다.
|
||||
- `no` 열의 값에 1을 더하여 `no` 열에 저장한 뒤, 그 값이 다시 `a` 열에 대입되기 때문이다.
|
||||
- 두 번째 `UPDATE` 명령을 실행하면 `no` 열의 값을 `a` 열에 대입한 후, `no` 열의 값을 + 1 한다. 따라서 `a` 열의 값은 `no - 1`한 값이 된다.
|
||||
- `MySQL`에서 ①을 실행했을 때 `no` 열과 `a` 열의 값은 같아진다. 하지만 ②를 실행하면 `no` 열과 `a` 열의 값은 서로 달라진다. 한편 `Oracle`에서는 ①을 실행해도 ②를 실행해도 `a` 열의 값은 `no - 1` 상태를 유지한다.
|
||||
- 즉, `Oracle`에서는 `SET` 구에 기술한 식의 순서가 처리에 영향을 주지 않는다.
|
||||
- 갱신식의 오른쪽에 위치한 `no` 열의 값이 항상 갱신 이전의 값을 반환하기 때문이다.
|
||||
- 한편 `MySQL`에서는 `SET` 구에 기술된 순서로 갱신 처리가 일어나므로 `no` 열의 값은 갱신 이전의 값이 아닌 갱신된 이후의 값을 반환한다.
|
||||
- 따라서 `MySQL`의 경우, 갱신식 안에서 열을 참조할 때는 처리 순서를 고려할 필요가 있다.
|
||||
|
||||
---
|
||||
|
||||
## 4. NULL로 갱신하기
|
||||
- `UPDATE` 명령으로 셀 값을 `NULL`로 갱신할 수 있다.
|
||||
- `UPDATE sample41 SET b = NULL`과 같이 갱신할 값으로 `NULL`을 지정하면 된다.
|
||||
- 이처럼 `NULL`로 값을 갱신하는 것을 보통 `NULL 초기화`라 부르기도 한다.
|
||||
|
||||
```
|
||||
UPDATE sample41 SET a = NULL;
|
||||
```
|
||||
|
||||
- 다만 `NOT NULL` 제약이 설정되어 있는 열은 `NULL`이 허용되지 않는다.
|
||||
- `UPDATE` 명령에 있어서도 `NOT NULL` 제약은 유효하다. `no` 열에는 `NOT NULL` 제약이 설정되어 있으므로 `no` 열의 셀을 `NULL`로 갱신할 수 없다.
|
||||
- 즉, `UPDATE sample41 SET no = NULL`을 실행하면 `NOT NULL` 제약에 위반되어 에러가 발생한다.
|
||||
|
||||
---
|
||||
34
도서/SQL첫걸음/Lecture19.md
Normal file
@@ -0,0 +1,34 @@
|
||||
# 19강. 물리삭제와 논리삭제
|
||||
데이터 삭제 방법에는 물리삭제와 논리삭제가 있습니다.
|
||||
|
||||
- 데이터베이스에서 데이터를 삭제하는 방법은 용도에 따라 크게 `물리삭제`와 `논리삭제`의 두가지로 나뉜다.
|
||||
- 하지만 물리삭제와 논리삭제는 전용 SQL 명령이 따로 존재하지 않는다.
|
||||
- 지금부터 설명할 내용은 SQL 명령에 관한 해설이라기보다는 시스템 설계 분야에 관한 것으로, 시스템을 구축할 때 자주 사용한느 말이기도 하다.
|
||||
|
||||
---
|
||||
|
||||
## 1. 두 종류의 삭제방법
|
||||
- 데이터베이스에서 데이터를 삭제할 때는 물리삭제와 논리삭제의 두 가지 방법을 고려할 수 있다.
|
||||
- 단, 이는 SQL 명령이 두 가지 존재한다는 의미가 아니다. 데이터를 삭제하는 데에 두 가지 사고 방식이 있다고 이해하면 쉽다.
|
||||
- 먼저, 물리삭제는 SQL의 `DELETE` 명령을 사용해 직접 데이터를 삭제하자는 사고 방식이다.
|
||||
- 삭제 대상 데이터는 필요없는 데이터이므로 `DELETE` 명령을 실행해서 테이블에서 삭제해버리자, 라는 지극히 자연스러운 발상에 의한 삭제방법을 말한다.
|
||||
- 한편 논리삭제의 경우, 테이블에 `삭제플래그`와 같은 열을 미리 준비해 둔다.
|
||||
- 즉, 테이블에서 실제로 행을 삭제하는 대신, `UPDATE` 명령을 이용해 `삭제플래그`의 값을 유효하게 갱신해두자는 발상에 의한 삭제방법을 말한다.
|
||||
- 실제 테이블 안에 데이터는 남아있지만, 참조할 때에는 `삭제플래기`가 삭제로 설정된 행을 제외하는 `SELECT` 명령을 실행한다. 결과적으로는 해당 행이 삭제된 것처럼 보인다.
|
||||
- 논리삭제는 삭제플래그를 사용하는 방법 이외에도 여러 가지 방법이 있다. 하지만 일반적으로는 삭제플래그를 사용해서 논리삭제를 구현한다.
|
||||
- 논리삭제의 장점으로는 데이터를 삭제하지 않기 때문에 삭제되기 전의 상태로 간단히 되돌릴 수 있다는 것을 꼽을 수 있다.
|
||||
- 한편 단점으로는 삭제해도 데이터베이스의 저장공간이 늘어나지 않는 점, 그리고 데이터베이스의 크기가 증가함에 따라 검색속도가 떨어지는 점을 들 수 있다.
|
||||
- 뿐만 아니라 애플리케이션 측 프로그램에서는 삭제임에도 불구하고 `UPDATE` 명령을 실행하므로 혼란을 야기하기도 한다.
|
||||
|
||||
---
|
||||
|
||||
## 2. 삭제방법 선택하기
|
||||
- 시스템의 특성이나 테이블에 저장되어 있는 데이터의 특성에 따라 다르기 때문에 단정지어 삭제방법을 말할 수는 없다.
|
||||
- 예를 들어 SNS 서비스처럼 사용자의 개인정보를 다루는 시스템에서는 사용자가 탈퇴한 경우 데이터를 삭제한다. 이때 개인정보를 취급하는 마스터 테이블에서 삭제할 경우에는 물리삭제를 하는 편이 안전할 것이다. 개인정보의 유출을 미연에 방지하는 측면에서도 좋은 선택이라 할 수 있다.
|
||||
- 반면, 쇼핑 사이트의 경우는 사용자가 주문을 취소할 경우에도 데이터를 삭제한다. 이러한 경우에는 논리삭제 방법을 많이 사용한다. 주문이 취소되었다고 해도 발주는 된 것으로, 해당 정보가 완전히 불필요한 것이라고는 말할 수 없다. 이러한 데이터는 특히 주문 관련 통계를 낼 때 유용하게 사용할 수 있기 때문이다.
|
||||
- 한편으로는 하드웨어의 제한으로 인해 물리삭제를 할 수밖에 없는 경우도 있다. 논리삭제로는 실제로 데이터가 삭제되지 않기 때문에 데이터베이스의 사용량은 줄어들지 않으며, 오히려 일방적으로 늘어난다. 이때 저장공간이 작다면 가능한 한 용량이 모자라지 않도록 운용할 필요가 있고 결국, 물리삭제 방법으로 데이터를 지운다.
|
||||
- 물리삭제와 논리삭제는 어느 쪽이 좋은지 따지기보다는 상황에 따라 용도에 맞게 데이터 삭제 방법을 선택하는 것이 중요하다.
|
||||
|
||||
##### 물리삭제와 논리삭제는 용도에 맞게 선택한다!
|
||||
|
||||
---
|
||||
114
도서/SQL첫걸음/Lecture20.md
Normal file
@@ -0,0 +1,114 @@
|
||||
# 20강. 행 개수 구하기 - COUNT
|
||||
대표적인 집계함수는 다음과 같은 5개를 꼽을 수 있다.
|
||||
**`집계함수`**
|
||||
```
|
||||
COUNT(집합)
|
||||
SUM(집합)
|
||||
AVG(집합)
|
||||
MIN(집합)
|
||||
MAX(집합)
|
||||
```
|
||||
|
||||
- SQL은 데이터베이스라 불리는 '데이터 집합'을 다루는 언어이다.
|
||||
- 집합의 개수나 합계가 궁금하다면 SQL이 제공하는 집계함수를 사용하여 간단하게 구할 수 있다.
|
||||
|
||||
---
|
||||
|
||||
## 1. COUNT로 행 개수 구하기
|
||||
- SQL은 집합을 다루는 `집계함수`를 제공한다.
|
||||
- 일반적인 함수는 인수로 하나의 값을 지정하는 데 비해 집계함수는 인수로 집합을 지정한다.
|
||||
- 이 때문에 집합함수라고 부르기도 한다.
|
||||
- 즉, 집합을 특정 방법으로 계산하여 그 결과를 반환한다.
|
||||
- `COUNT` 함수는 인수로 주어진 집합의 개수를 구해 반환한다.
|
||||
|
||||
**`COUNT`**
|
||||
```
|
||||
COUNT(집합)
|
||||
```
|
||||
|
||||
**`COUNT로 행 개수 계산`**
|
||||
```
|
||||
SELECT COUNT(*) FROM sample51;
|
||||
```
|
||||
|
||||
- 인수로 `*`가 지정되어 있는데 이는 `SELECT` 구에서 '모든 열`을 나타낼 때 사용하는 메타문자와 같다.
|
||||
- 다만 이때 `COUNT` 집계함수에서는 '모든 열 = 테이블 전체'라는 의미로 사용한다.
|
||||
- 즉, `COUNT`는 인수로 지정된 집합(이 경우는 테이블 전체)의 개수를 계산하는 것이다.
|
||||
|
||||
##### COUNT 집계함수로 행 개수를 구할 수 있다!
|
||||
|
||||
- 집계함수의 특징은 복수의 값(집합)에서 하나의 값을 계산해내는 것이다.
|
||||
- 일반적인 함수는 하나의 행에 대하여 하나의 값을 반환한다.
|
||||
- 한편 집계함수는 집합으로부터 하나의 값을 반환한다.
|
||||
- 이렇게 집합으로부터 하나의 값을 계산하는 것을 '집계'라 부른다.
|
||||
- 이러한 이유로 집계함수를 `SELECT` 구에 쓰면 `WHERE` 구의 유무와 관계없이 결괏값으로 하나의 행을 반환한다.
|
||||
|
||||
### WHERE 구 지정하기
|
||||
- `SELECT` 구는 `WHERE` 구보다 나중에 내부적으로 처리된다.
|
||||
- 따라서 `WHERE` 구로 조건을 지정하면 테이블 전체가 아닌, 검색된 행이 `COUNT`로 넘겨진다.
|
||||
- 즉, `WHERE` 구의 조건에 맞는 행의 개수를 구할 수 있다.
|
||||
- 검색된 행은 `WHERE` 구의 조건에 맞는 개수가 나오지만, 최종적으로 결과는 하나의 행이 된다.
|
||||
|
||||
---
|
||||
|
||||
## 2. 집계함수와 NULL값
|
||||
- `COUNT`의 인수로 열명을 지정할 수 있다.
|
||||
- 열명을 지정하면 그 열에 한해서 행의 개수를 구할 수 있다.
|
||||
- `*`을 인수로 사용할 수 있는 것은 `COUNT` 함수뿐이다.
|
||||
- 다른 집계함수에서는 열명이나 식을 인수로 지정한다.
|
||||
- 집계함수는 집합 안에 `NULL` 값이 있을 경우 이를 제외하고 처리한다.
|
||||
|
||||
```
|
||||
SELECT COUNT(no), COUNT(name) FROM sample51;
|
||||
```
|
||||
- no 열에는 `NULL` 값을 가지는 행이 존재하지 않으므로 no 열의 행 개수는 5로 나타난다.
|
||||
- name 열에는 `NULL` 값을 가지는 행이 하나 존재하므로, 이를 제외한 name 열의 행 개수는 4로 나타난다.
|
||||
- 다만 `COUNT(*)`의 경우 모든 열의 행수를 카운트하기 때문에 `NULL` 값이 있어도 해당 정보가 무시되지 않는다.
|
||||
|
||||
##### 집계함수는 집합 안에 NULL 값이 있을 경우 무시한다!
|
||||
|
||||
---
|
||||
|
||||
## 3. DISTINCT로 중복 제거
|
||||
- 집합을 다룰 때, 경우에 따라서는 집합 안에 중복된 값이 있는지 여부가 문제될 때도 있다.
|
||||
- 데이터가 서로 중복되지 않는 경우에는 `'유일한 값을 가진다'`라는가 `'값이 중복되지 않는다'`라는 표현을 자주 한다.
|
||||
- SQL의 `SELECT` 명령은 이러한 중복된 값을 제거하는 함수를 제공한다. 이때 사용하는 키워드가 바로 `DISTINCT`이다.
|
||||
|
||||
```
|
||||
SELECT ALL name FROM sample51;
|
||||
```
|
||||
|
||||
**`DISTINCT를 지정. 콤마는 붙이지 않는다.`**
|
||||
```
|
||||
SELECT DISTINCT name FROM sample51;
|
||||
```
|
||||
|
||||
- `DISTINCT`는 예약어로 열명이 아니다.
|
||||
- `SELECT` 구에서 `DISTINCT`를 지정하면 중복된 데이터를 제외한 결과를 클라이언트로 반환한다.
|
||||
- 중복 여부는 `SELECT` 구에 지정된 모든 열을 비교해 판단한다.
|
||||
- 앞의 예제에서 첫 번째 `SELECT` 명령에서는 `DISTINCT`가 아닌 `ALL`을 지정했는데, 이렇게하면 중복 유무와 관계없이 문자 그대로 모든 행을 반환한다.
|
||||
- 즉, `SELECT` 구에 지정하는 `ALL` 또는 `DISTINCT`는 중복된 값을 제거할 것인지 설정하는 스위치와 같은 역할을 한다.
|
||||
- 이때 `ALL`과 `DISTINCT` 중 어느 것도 지정하지 않은 경우에는 중복된 값은 제거되지 않는다.
|
||||
- 즉, 생략할 경우에는 `ALL`로 간주된다.
|
||||
|
||||
##### DISTINCT로 중복값을 제거할 수 있다!
|
||||
|
||||
---
|
||||
|
||||
## 4. 집계함수에서 DISTINCT
|
||||
- `NULL` 값을 제외하고, 중복하지 않는 데이터의 개수를 구하는 경우를 생각해봅니다.
|
||||
- `COUNT` 함수, `DISTINCT`, `WHERE` 구의 조건을 지정해 구할 수 있는가? 구할 수 없다.
|
||||
- `WHERE` 구에서는 검색할 조건을 지정하는 것밖에 할 수 없다. 중복된 값인지 아닌지를 알아보는 함수도 없다.
|
||||
- `SELECT DISTINCT COUNT(name)`라는 `SELECT` 명령으로도 안 된다. `COUNT` 쪽이 먼저 계산되어버리기 때문이다.
|
||||
- 이럴때는 집계함수의 인수로 `DISTINCT`를 사용한 수식을 지정하는 방법을 사용한다.
|
||||
- `DISTINCT`는 집계함수의 인수에 수식자로 지정할 수 있다.
|
||||
- `DISTINCT`를 이용해 집합에서 중복을 제거한 뒤 `COUNT`로 개수를 구할 수 있는 것이다.
|
||||
|
||||
```
|
||||
SELECT COUNT(ALL name), COUNT(DISTINCT name) FROM sample51;
|
||||
```
|
||||
|
||||
- `SELECT` 구에서의 중복삭제와 마찬가지로, `DISTINCT`가 아닌 `ALL`을 지정하면 집합 전부가 집계함수에 주어진다.
|
||||
- 이때 `DISTINCT`와 `ALL`은 인수가 아니므로 콤마는 붙이지 않는다.
|
||||
|
||||
---
|
||||
68
도서/SQL첫걸음/Lecture21.md
Normal file
@@ -0,0 +1,68 @@
|
||||
# 21강. COUNT 이외의 집계함수
|
||||
`SUM` 집계함수를 사용해 집합의 합계치를 구할 수 있다.
|
||||
|
||||
**`SUM, AVG, MIN, MAX`**
|
||||
```
|
||||
SUM ([ALL|DISTINCT] 집합)
|
||||
AVG ([ALL|DISTINCT] 집합)
|
||||
MIN ([ALL|DISTINCT] 집합)
|
||||
MAX ([ALL|DISTINCT] 집합)
|
||||
```
|
||||
|
||||
- SQL에서는 `SUM` 함수를 사용해 합계를 구할 수 있습니다.
|
||||
- 또한 집합에서 최솟값, 최댓값을 찾는 경우에도 집계함수를 사용해 처리할 수 있습니다.
|
||||
|
||||
---
|
||||
|
||||
## 1. SUM으로 합계 구하기
|
||||
- 집계함수는 `COUNT`만 있는 것이 아니다.
|
||||
- `SUM 집계함수`를 사용해 집합의 합계를 구할 수 있다.
|
||||
- 예를 들어 1, 2, 3이라는 세 개의 값을 가지는 집합이 있다고 한다면, `SUM` 집계함수의 인수로 이 집합을 지정하면 1+2+3으로 계산하여 6이라는 값을 반환한다.
|
||||
|
||||
**`SUM으로 quantity열의 합계 구하기`**
|
||||
```
|
||||
SELECT SUM(quantity) FROM sample51;
|
||||
```
|
||||
|
||||
- `SUM` 집계함수에 지정되는 집합은 수치형 뿐이다.
|
||||
- 문자열형이나 날짜시간형의 집합에서 합계를 구할 수는 없다.
|
||||
- `name` 열은 문자열형이므로 `SUM(name)`과 같이 지정할 수는 없습니다.
|
||||
- 한편, `SUM` 집계함수도 `COUNT`와 마찬가지로 `NULL` 값을 무시하며, `NULL` 값을 제거한 뒤 합계를 낸다.
|
||||
|
||||
##### 집계함수로 집합의 합계를 구할 수 있다!
|
||||
|
||||
---
|
||||
|
||||
## 2. AVG로 평균내기
|
||||
- `SUM` 집계함수를 사용하여 집합의 합계를 구할 수 있다.
|
||||
- 이때 합한 값을 개수로 나누면 `평균값`을 구할 수 있다.
|
||||
- 집계함수가 반환한 값을 연산할 수도 있는데 `SUM(quantity) / COUNT(quantity)`와 같이 지정하면 된다.
|
||||
|
||||
**`AVG 평균값 구하기`**
|
||||
```
|
||||
SELECT AVG(quantity), SUM(quantity)/COUNT(quantity) FROM sample51;
|
||||
```
|
||||
|
||||
##### AVG 집계함수로 집합의 평균값을 구할 수 있다!
|
||||
|
||||
- `AVG` 집계함수도 `NULL` 값은 무시한다.
|
||||
- 즉, `NULL` 값을 제거한 뒤에 평균값을 계산한다.
|
||||
- 만약 `NULL`을 0으로 간주해서 평균을 내고 싶다면 `CASE`를 사용해 `NULL`을 0으로 변환한 뒤에 `AVG` 함수로 계산하면 된다.
|
||||
|
||||
```
|
||||
SELECT AVG(CASE WHEN quantity IS NULL THEN 0 ELSE quantity END) AS avgnull0 FROM sample51;
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 3. MIN - MAX로 최솟값, 최댓값 구하기
|
||||
- `MIN 집계함수`, `MAX 집계함수`를 사용해 집합에서 최솟값과 최댓값을 구할 수 있다.
|
||||
- 이들 함수는 문자열형과 날짜시간형에도 사용할 수 있다.
|
||||
- 다만 `NULL` 값을 무시하는 기본규칙은 다른 집계함수와 같다.
|
||||
|
||||
**`MIN, MAX로 최솟값, 최댓값 구하기`**
|
||||
```
|
||||
SELECT MIN(quantity), MAX(quantity), MIN(name), MAX(name) FROM sample51;
|
||||
```
|
||||
|
||||
---
|
||||
147
도서/SQL첫걸음/Lecture22.md
Normal file
@@ -0,0 +1,147 @@
|
||||
# 22강. 그룹화 - GROUP BY
|
||||
`GROUP BY` 구를 사용해 그룹화하는 방법에 대해서 알아본다.
|
||||
|
||||
**`GROUP BY`**
|
||||
```
|
||||
SELECT * FROM 테이블명 GROUP BY 열1, 열2 ...
|
||||
```
|
||||
|
||||
- `COUNT`의 인수로는 집합을 지정하는데, 테이블 전체 혹은 `WHERE` 구로 검색한 행이 그 대상이된다.
|
||||
- `GROUP BY` 구를 사용해 집계함수로 넘겨줄 집합을 `그룹`으로 나눌 수 있다.
|
||||
|
||||
---
|
||||
|
||||
## 1. GROUP BY로 그룹화
|
||||
- 같은 값을 가진 행끼리 묶어 그룹화한 집합을 집계함수로 넘겨줄 수 있다.
|
||||
- 그룹으로 나눌 때에는 `GROUP BY` 구를 사용한다.
|
||||
- 이때 `GROUP BY` 구에는 그룹화할 열을 지정하며, 복수로도 지정할 수 있다.
|
||||
|
||||
```
|
||||
SELECT name FROM sample51 GROUP BY name;
|
||||
```
|
||||
|
||||
- 결과는 `DISTINCT`를 지정했을 때와 같다.
|
||||
- `GROUP BY` 구에 열을 지정하여 그룹화하면 `지정된 열의 값이 같은 행이 하나의 그룹으로 묶인다`
|
||||
- `SELECT` 구에서 `name` 열을 지정하였으므로 그룹화된 `name` 열의 데이터가 클라이언트로 반환된다.
|
||||
- 각 그룹으로 묶인 값들은 서로 동일하다. 즉, 결과적으로는 각각의 그룹 값이 반환된다.
|
||||
- 따라서 `GROUP BY`를 지정해 그룹화하면 `DISTINCT`와 같이 중복을 제거하는 효과가 있다.
|
||||
|
||||
##### GROUP BY 구로 그룹화 할 수 있다!
|
||||
|
||||
- 사실 `GROUP BY`는 집계함수와 함께 사용하지 않으면 별 의미가 없다.
|
||||
- `GROUP BY` 구로 그룹화된 각각의 그룹이 하나의 집합으로서 집계함수의 인수로 넘겨지기 때문이다.
|
||||
|
||||
**`GROUP BY 구와 집계함수를 조합`**
|
||||
```
|
||||
SELECT name, COUNT(name), SUM(quantity) FROM sample51 GROUP BY name;
|
||||
```
|
||||
|
||||
- 예를 들면 각 점포의 일별 매출 데이터가 중앙 판매 관리시스템에 전송되어 점포별 매출실적을 집계해 어떤 점포가 매출이 올라가는지, 어떤 상품이 인기가 있는지 등을 분석할 때 사용한다.
|
||||
- 여기에서 점포별, 상품별, 월별, 일별 등 특정 단위로 집계할 때 `GROUP BY`를 자주 사용한다.
|
||||
- 매출실적을 조사하는 동시에 `SUM` 집계함수로 합계를 낼 수 있으며, `COUNT`로 건수를 집계하는 경우도 있다.
|
||||
|
||||
---
|
||||
|
||||
## 2. HAVING 구로 조건 지정
|
||||
- 집계함수는 `WHERE` 구의 조건식에서는 사용할 수 없다.
|
||||
|
||||
```
|
||||
SELECT name, COUNT(name) FROM sample51
|
||||
WHERE COUNT(name) = 1 GROUP BY name;
|
||||
```
|
||||
|
||||
- `name` 열을 그룹화하여 행 개수가 하나만 존재하는 그룹을 검색하고 싶었지만 에러가 발생하여 실행할 수 없다.
|
||||
- 에러가 발생한 이유는 `GROUP BY`와 `WHERE` 구의 내부처리 순서와 관계있다.
|
||||
- 즉, `WHERE` 구로 행을 검색하는 처리가 `GROUP BY`로 그룹화하는 처리보다 순서상 앞서기 때문이다.
|
||||
- `SELECT` 구에서 지정한 별명을 `WHERE` 구에서 사용할 수 없었던 것과 같은 이유로, 그룹화가 필요한 집계함수는 `WHERE` 구에서 지정할 수 없다.
|
||||
|
||||
**`내부처리 순서`**
|
||||
```
|
||||
WHERE 구 -> GROUP BY 구 -> SELECT 구 -> ORDER BY 구
|
||||
```
|
||||
|
||||
##### WHERE 구에서는 집계함수를 사용할 수 없다!
|
||||
|
||||
- 집계한 결과에서 조건에 맞는 값을 걸러내려면 `HAVING` 구를 사용한다.
|
||||
- `SELECT` 명령에는 `HAVING` 구가 있다. `HAVING` 구를 사용하면 집계함수를 사용해서 조건식을 지정할 수 있다.
|
||||
- `HAVING` 구는 `GROUP BY` 구의 뒤에 기술하며 `WHERE` 구와 동일하게 조건식을 지정할 수 있다.
|
||||
- 조건식에는 그룹별로 집계된 열의 값이나 집계함수의 계산결과가 전달된다고 생각하면 이해하기 쉽다.
|
||||
- 이때 조건식이 참인 그룹값만 클라이언트에 반환된다.
|
||||
- 결과적으로 `WHERE` 구와 `HAVING` 구에 지정된 조건으로 검색하는 2단 구조가 된다.
|
||||
|
||||
```
|
||||
1. WHERE로 검색
|
||||
2. 검색한 뒤 그룹화
|
||||
3. HAVING으로 검색
|
||||
```
|
||||
|
||||
**`HAVING 구로 걸러내기`**
|
||||
```
|
||||
SELECT name, COUNT(name) FROM sample51 GROUP BY name HAVING COUNT(name) = 1;
|
||||
```
|
||||
|
||||
##### 집계함수를 사용할 경우 HAVING 구로 검색조건을 지정한다!
|
||||
|
||||
- 그룹화보다도 나중에 처리되는 `ORDER BY` 구에서는 문제없이 집계함수를 사용할 수 있다.
|
||||
- 즉, `ORDER BY COUNT(name)`과 같이 지정할 수 있다.
|
||||
- `HAVING` 구는 `GROUP BY` 구 다음으로 처리된다.
|
||||
|
||||
**`내부처리 순서`**
|
||||
```
|
||||
WHERE 구 -> GROUP BY 구 -> HAVING 구 -> SELECT 구 -> ORDER BY 구
|
||||
```
|
||||
|
||||
- 다만, `SELECT` 구보다도 먼저 처리되므로 별명을 사용할 수는 없다.
|
||||
- 예를 들어 `COUNT(name)`에 `cn`이라는 별명을 붙이면, `ORDER BY` 구에서는 사용할 수 있지만 `GROUP BY` 구나 `HAVING` 구에서는 사용할 수 없다. 즉, 다음과 같은 명령은 실행할 수 없다.
|
||||
|
||||
```
|
||||
SELECT name AS n, COUNT(name) AS cn
|
||||
FROM sample51 GROUP BY n HAVING cn = 1;
|
||||
```
|
||||
|
||||
- 단, `MySQL`과 같이 융통성 있게 별명을 사용할 수 있는 데이터베이스 제품도 있다.
|
||||
- 실제로, 앞의 `SELECT` 명령은 `MySQL`에서는 실행 가능하지만 `Oracle`등에서는 에러가 발생한다.
|
||||
|
||||
---
|
||||
|
||||
## 3. 복수열의 그룹화
|
||||
- `GROUP BY`를 사용할 때 주의할 점이 있다.
|
||||
- `GROUP BY`에 지정한 열 이외의 열은 집계함수를 사용하지 않은 채 `SELECT` 구에 기술하면 안된다는 것이다.
|
||||
- `GROUP BY name`으로 `name` 열을 그룹화 했을 때, 이 경우 `SELECT` 구에 `name`을 지정하는 것은 문제없지만, `no` 열이나 `quantity` 열을 `SELECT` 구에 그대로 지정하면 데이터베이스 제품에 따라 에러가 발생한다.
|
||||
- `GROUP BY`로 그룹화하면 클라이언트로 반환되는 결과는 그룹당 하나의 행이 된다.
|
||||
- 하지만 `name` 열 값이 A인 그룹의 `quantity` 열 값은 1과 2로 두 개이다.
|
||||
- 이때 그룹마다 하나의 값만을 반환해야 하므로 어느 것을 반환하면 좋을지 몰라 에러가 발생한다.
|
||||
- 이때 집계함수를 사용하면 집합은 하나의 값으로 계산되므로, 그룹마다 하나의 행을 출력할 수 있다.
|
||||
- 즉 다음과 같이 쿼리를 작성하면 문제없이 실행할 수 있다.
|
||||
|
||||
```
|
||||
SELECT MIN(no), name, SUM(quantity) FROM sample51 GROUP BY name;
|
||||
```
|
||||
|
||||
##### GROUP BY에서 지정한 열 이외의 열은 집계함수를 사용하지 않은 채 SELECT 구에 지정할 수 없다!
|
||||
|
||||
- 만약 `no`와 `quantity`로 그룹화한다면 `GROUP BY no, quantity`로 지정한다.
|
||||
- 이처럼 `GROUP BY`에서 지정한 열이라면 `SELECT` 구에 그대로 지정해도 된다.
|
||||
|
||||
```
|
||||
SELECT name, quantity FROM sample51 GROUP BY name, quantity;
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 4. 결괏값 정렬
|
||||
- `GROUP BY`로 그룹화해도 실행결과 순서롤 정렬할 수는 없다.
|
||||
- 데이터베이스 내부 처리에서 같은 값을 그룹으로 나누는 과정에서 순서가 서로 바뀌는 부작용이 일어날 수도 있다.
|
||||
- 하지만 이는 데이터베이스 내부처리의 문제로 데이터베이스 제품에 따라 다르다.
|
||||
- 확실한 것은 `GROUP BY` 지정을 해도 정렬되지는 않는다는 점이다.
|
||||
- 이럴 때는 `ORDER BY` 구를 사용해 결과를 정렬할 수 있다.
|
||||
- `GROUP BY` 구로 그룹화한 경우도 `ORDER BY` 구를 사용해 정렬할 수 있다.
|
||||
- 결괏값을 순서대로 정렬해야 한다면 `ORDER BY` 구를 지정해주면 된다.
|
||||
|
||||
**`name 열로 그룹화해 합계를 구하고 내림차순으로 정렬`**
|
||||
```
|
||||
SELECT name, COUNT(name), SUM(quantity)
|
||||
FROM sample51 GROUP BY name ORDER BY SUM(quantity) DESC;
|
||||
```
|
||||
|
||||
---
|
||||
233
도서/SQL첫걸음/Lecture23.md
Normal file
@@ -0,0 +1,233 @@
|
||||
# 23강. 서브쿼리
|
||||
서브쿼리는 `SELECT` 명령에 의한 데이터 질의로, 상부가 아닌 하부의 부수적인 질의를 의미한다.
|
||||
|
||||
**`서브쿼리`**
|
||||
```
|
||||
(SELECT 명령)
|
||||
```
|
||||
|
||||
- 서브쿼리는 SQL 명령문 안에 지정하는 하부 `SELECT` 명령으로 괄호로 묶어 지정한다.
|
||||
- 문법에는 간단하게 `SELECT 명령`이라고 적었지만 `SELECT 구`, `FROM 구`, `WHERE 구` 등 `SELECT` 명령의 각 구를 기술할 수 있다.
|
||||
- 특히 서브쿼리는 SQL 명령의 WHERE 구에서 주로 사용된다.
|
||||
- `WHERE` 구는 `SELECT`, `DELETE`, `UPDATE` 구에서 사용할 수 있는데 이들 중 어떤 명령에서든 서브쿼리를 사용할 수 있다.
|
||||
|
||||
---
|
||||
|
||||
## 1. DELETE의 WHERE 구에서 서브쿼리 사용하기
|
||||
- 만약 `a`열의 값이 가장 작은 행을 제거하고 싶다면 `DELETE` 명령과 `SELECT` 명령을 결합시켜서 제거할 수 있다.
|
||||
|
||||
**`최솟값을 가지는 행 삭제하기`**
|
||||
```
|
||||
DELETE FROM sample54 WHERE a = (SELECT MIN(a) FROM sample54);
|
||||
```
|
||||
|
||||
- 서브쿼리를 사용하면 이렇게 `DELETE`와 `SELECT`를 결합시킬 수 있다.
|
||||
- 괄호로 둘러싼 서브쿼리 부분을 먼저 실행한 후 `DELETE` 명령을 실행한다고 생각하면 이해하기 쉬울 것이다.
|
||||
- 단, `MySQL`에서는 위 예제 쿼리를 실행할 수 없음에 주의해야 한다.
|
||||
- 대신 `DELETE` 명령을 `SELECT` 명령으로 바꾸면 실행할 수 있다.
|
||||
- `MySQL`에서 예제를 실행하면 `You can't specify target table 'sample54' for update in FROM clause`라는 에러가 발생한다. 데이터를 추가하거나 갱신할 경우 동일한 테이블을 서브쿼리에서 사용할 수 없도록 되어있기 때문이다.
|
||||
- 에러를 발생하지 않고 실행하려면 다음과 같이 인라인 뷰로 임시 테이블을 만들도록 처리하면 된다.
|
||||
- `DELETE FROM sample54 WHERE a = (SELECT a FROM (SELECT MIN(a) AS a FROM sample54) AS x);`
|
||||
|
||||
- 한편 SQL에는 순차형 언어에서처럼 변수가 존재하지 않는다. 만약 변수를 사용할 수 있다고 한다면, 다음과 같이 정리해 표현할 수 있을 것이다.
|
||||
|
||||
```
|
||||
변수 = (SELECT MIN(a) FROM sample54);
|
||||
DELETE FROM sample54 WHERE a = 변수;
|
||||
```
|
||||
|
||||
- 사실 이렇게 변수를 사용하는 것은 가능하다.
|
||||
- 구현방법에는 여러 가지가 있으므로 자세히 설명할 수는 없지만 변수를 사용할 수 있다는 것은 알아두자.
|
||||
|
||||
**`클라이언트 변수`**
|
||||
```
|
||||
앞서 언급한 변수에 관한 것으로, mysql 클라이언트에 한해 다음과 같이 구현할 수 있다.
|
||||
이때 @a가 변수가 되고 set이 변수에 대입하는 명령이 된다.
|
||||
mysql> set @a = (SELECT MIN(a) FROM sample54);
|
||||
mysql> DELETE FROM sample54 WHERE a = @a;
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 2. 스칼라 값
|
||||
- 서브쿼리를 사용할 때는 그 `SELECT` 명령이 어떤 값을 반환하는지 주의할 필요가 있다.
|
||||
- 여러 가지 패턴 중에서도 다음과 같은 네 가지가 일반적인 서브쿼리의 패턴이다.
|
||||
|
||||
**`서브쿼리의 패턴`**
|
||||
```
|
||||
패턴 1. 하나의 행과 하나의 값을 반환하는 패턴
|
||||
SELECT MIN(a) FROM sample54;
|
||||
|
||||
패턴 2. 복수의 행이 반환되지만 열은 하나인 패턴
|
||||
SELECT no FROM sample54;
|
||||
|
||||
패턴 3. 하나의 행이 반환되지만 열이 복수인 패턴
|
||||
SELECT MIN(a), MAX(no) FROM sample54;
|
||||
|
||||
패턴 4. 복수의 행, 복수의 열이 반환되는 패턴
|
||||
SELECT no, a FROM sample54;
|
||||
```
|
||||
|
||||
- 이때 패턴1만 다른 패턴과 다르다. 이는 다른 패턴과 달리 하나의 값을 반환하기 때문이다.
|
||||
- `단일 값`으로 통용되지만 데이터베이스 업계에서는 `스칼라 값`이라 불리는 경우가 많으므로 기억해 두자.
|
||||
|
||||
##### SELECT 명령이 하나의 값만 반환하는 것을 '스칼라 값을 반환한다'고 한다!
|
||||
|
||||
- 스칼라 값을 반환하는 `SELECT` 명령을 특별 취급하는 이유는 서브쿼리로서 사용하기 쉽기 때문이다.
|
||||
- 이처럼 스칼라 값을 반환하도록 `SELECT` 명령을 작성하고자 한다면 `SELECT` 구에서 단일 열을 지정한다.
|
||||
- 복수 열을 반환하도록 하면 패턴 3이나 4가 되어버리기 때문이다.
|
||||
- `SELECT` 구에서 하나의 열을 지정하고, `GROUP BY`를 지정하지 않은 채 집계함수를 사용하면 결과는 단일한 값이 된다.
|
||||
- 만약 `GROUP BY`로 그룹화를 하면 몇 가지의 그룹으로 나뉘어져 버릴 가능성이 있기 때문에 결과적으로 단일한 값이 반환되지 않을 수 있다.
|
||||
- 또한, `WHERE` 조건으로 하나의 행만 검색할 수 있다면 단일 값이 되므로 스칼라 값을 반환하는 `SELECT` 명령이 된다.
|
||||
- 통상적으로 특정한 두 가지가 서로 동일한지 여부를 비교할 때는 서로 단일한 값으로 비교한다.
|
||||
- 즉, `WHERE` 구에서 스칼라 값을 반환하는 서브쿼리는 `=` 연산자로 비교할 수 있다는 뜻이다.
|
||||
|
||||
```
|
||||
DELETE FROM sample54 WHERE a = (SELECT MIN(a) FROM sample54);
|
||||
```
|
||||
|
||||
- 여기에서 서브쿼리 부분은 스칼라 값을 반환하는 `SELECT` 명령으로 되어있으므로 `=` 연산자를 사용해 열 `a`의 값과 비교할 수 있다.
|
||||
- 반대로 스칼라 값을 반환하지 않도록 만들기란 간단하다. 서브쿼리 부분을 변경하면 스칼라 값을 반환하지 않도록 할 수 있다.
|
||||
- `SELECT` 구에서 다른 열을 지정하거나 `GROUP BY`를 지정하면 바로 에러가 발생한다.
|
||||
|
||||
##### = 연산자를 사용하여 비교할 경우에는 스칼라 값끼리 비교할 필요가 있다!
|
||||
|
||||
- 스칼라 값을 반환하는 서브쿼리를 특별히 `스칼라 서브쿼리`라 부르기도 한다.
|
||||
- 앞서 `HAVING` 구를 설명할 때 '집계함수는 `WHERE` 구에서는 사용할 수 없다'라고 설명했었다.
|
||||
- 하지만 `스칼라 서브쿼리`라면 `WHERE` 구에 사용할 수 있으므로 집계함수를 사용해 집계한 결과를 조건식으로 사용할 수 있다.
|
||||
- 이와 비슷한 문제로 '`GROUP BY`에서 지정한 열 이외의 열을 `SELECT` 구에 지정하면 에러가 난다'라는 것도 있었다.
|
||||
- 하나의 그룹에 다른 값이 여러 개 존재할 경우는 스칼라 값이라고 할 수 없다.
|
||||
|
||||
---
|
||||
|
||||
## 3. SELECT 구에서 서브쿼리 사용하기
|
||||
- 서브쿼리는 `SELECT` 구, `UPDATE`의 `SET` 구 등 다양한 구 안에서 지정할 수 있다.
|
||||
- 문법적으로 서브쿼리는 `하나의 항목`으로 취급한다.
|
||||
- 단, 문법적으로는 문제없지만 실행하면 에러가 발생하는 경우가 자주 있다. 이는 스칼라 값의 반환여부에 따라 생기는 현상으로, 서브쿼리를 사용할 때는 스칼라 서브쿼리로 되어있는지 확인해야 한다.
|
||||
- `SELECT` 구에서 서브쿼리를 지정할 때는 스칼라 서브쿼리가 필요하다.
|
||||
|
||||
**`SELECT 구에서 서브쿼리 사용하기`**
|
||||
```
|
||||
SELECT
|
||||
(SELECT COUNT(*) sample51) AS sq1,
|
||||
(SELECT COUNT(*) sample54) AS sq2;
|
||||
```
|
||||
|
||||
- sample51 테이블의 행 개수와 sample54 테이블의 행 개수를 각 서브쿼리로 구한다.
|
||||
- 여기서 한 가지 주의할 점이 있는데 서브쿼리가 아닌 상부의 `SELECT` 명령에는 `FROM` 구가 없다는 것이다. `MySQL` 등에서는 실제로 `FROM` 구를 생략할 수 있다.
|
||||
- 하지만 `Oracle` 등 전통적인 데이터베이스 제품에서는 `FROM`를 생략할 수 없다.
|
||||
- 이때 `Oracle`에서는 다음과 같이 `FROM DUAL`로 지정하면 실행할 수 있다.
|
||||
- `DUAL`은 시스템 쪽에서 데이터베이스에 기본으로 작성되는 테이블이다.
|
||||
|
||||
**`SELECT 구에서 서브쿼리 사용하기(Oracle의 경우)`**
|
||||
```
|
||||
SELECT
|
||||
(SELECT COUNT(*) sample51) AS sq1,
|
||||
(SELECT COUNT(*) sample54) AS sq2 FROM DUAL;
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 4. SET 구에서 서브쿼리 사용하기
|
||||
- `UPDATE`의 `SET` 구에서도 서브쿼리를 사용할 수 있다.
|
||||
|
||||
**`SET 구에서 서브쿼리 사용하기`**
|
||||
```
|
||||
UPDATE sample54 SET a = (SELECT MAX(a) FROM sample54);
|
||||
```
|
||||
|
||||
- `SET` 구에서 서브쿼리를 사용할 경우에도 스칼라 값을 반환하도록 스칼라 서브쿼리를 지정할 필요가 있다.
|
||||
- 위 `UPDATE` 명령을 실행하면 a 열 값이 모두 a 열의 최댓값으로 갱신된다.
|
||||
- 사실 이런 경우, 서브쿼리는 상부의 `UPDATE` 명령과 관련이 있는 조건식으로 지정되지 않으면 별 의미가 없다(차차 설명함).
|
||||
|
||||
---
|
||||
|
||||
## 5. FROM 구에서 서브쿼리 사용하기
|
||||
- `FROM` 구에서도 서브쿼리를 사용할 수 있다.
|
||||
- `FROM` 구에 서브쿼리를 지정하는 경우에도 서브쿼리의 기술방법은 같다.
|
||||
- 괄호로 `SELECT` 명령을 묶으면 된다. 다만 `FROM` 구에는 기본적으로 테이블을 지정하는 만큼 다른 구와는 조금 상황이 다르다.
|
||||
- 한편 `SELECT` 구나 `SET` 구에서는 스칼라 서브쿼리를 지정해야 하지만 `FROM` 구에 기술할 경우에는 스칼라 값을 반환하지 않아도 된다. 물론 스칼라 값이라도 상관없다.
|
||||
|
||||
**`FROM 구에서 서브쿼리 사용하기`**
|
||||
```
|
||||
SELECT * FROM (SELECT * FROM sample54) sq;
|
||||
```
|
||||
|
||||
- `SELECT` 명령 안에 `SELECT` 명령이 들어있는 듯 보이는데, 이를 `네스티드(nested) 구조`, 또는 `중첩구조`나 `내포구조`라 부른다.
|
||||
- sq는 테이블의 별명으로, `Sub Query`의 이니셜에서 따온 것이다.
|
||||
- `SELECT` 구에서는 열이나 식에 별명을 붙일 수 있다.
|
||||
- 마찬가지로 `FROM` 구에서는 테이블이나 서브쿼리에 별명을 붙일 수 있다.
|
||||
- 테이블에는 이름이 붙여져 있지만 서브쿼리에는 이렇다 할 이름이 붙여져 있지 않다.
|
||||
- 별명을 붙이는 것으로 비로소 서브쿼리의 이름을 지정한다.
|
||||
- 이 때도 `SELECT` 구에서 별명을 붙일 때처럼 `AS` 키워드를 사용하여 지정한다(단, `Oracle`에서는 `AS`를 붙이면 에러가 발생한다. `Oracle`에서는 `AS`를 붙이지 않는다).
|
||||
- 중첩구조는 몇 단계로든 구성할 수 있다. 다음과 같이 3단계 구조라도 상관없다.
|
||||
|
||||
**`FROM 구에서 서브쿼리 사용하기(3단계)`**
|
||||
```
|
||||
SELECT * FROM (SELECT * FROM (SELECT * FROM sample54) sq1) sq2;
|
||||
```
|
||||
|
||||
- 위의 예제처럼 테이블 한 개를 지정하는 데 3단계 중첩구조로 작성하지는 않는다. 사실 의미가 없기 때문이다.
|
||||
|
||||
### 실제 업무에서 FROM 구에 서브쿼리를 지정하여 사용하는 경우
|
||||
- 앞서 `LIMIT` 구에 관해서 설명할 때 `Oracle`에는 `LIMIT` 구가 없다고 했습니다.
|
||||
- `ROWNUM`으로 행 개수를 제한할 수 있지만, 정렬 후 상위 몇 건을 추출하는 조건은 붙일 수 없었다.
|
||||
- 이는 `ROWNUM`의 경우 `WHERE` 구로 인해 번호가 할당되기 때문이다.
|
||||
- 하지만 `FROM` 구에서 서브쿼리를 사용하는 것으로 `Oracle`에서도 정렬 후 상위 몇 건을 추출한다는 행 제한을 할 수 있다.
|
||||
|
||||
**`Oracle에서 LIMIT 구의 대체 명령`**
|
||||
```
|
||||
SELECT * FROM (
|
||||
SELECT * FROM sample54 ORDER BY a DESC
|
||||
) sq
|
||||
WHERE ROWNUM <= 2;
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 6. INSERT 명령과 서브쿼리
|
||||
- `INSERT` 명령과 서브쿼리를 조합해 사용할 수도 있다.
|
||||
- `INSERT` 명령에는 `VALUES` 구의 일부로 서브쿼리를 사용하는 경우와, `VALUES` 구 대신 `SELECT` 명령을 사용하는 두 가지 방법이 있다.
|
||||
- 먼저, `VALUES` 구의 값으로 서브쿼리를 사용하는 경우 서브쿼리는 스칼라 서브쿼리로 지정할 필요가 있다. 물론 자료형도 일치해야 한다.
|
||||
|
||||
**`VALUES 구에서 서브쿼리 사용하기`**
|
||||
```
|
||||
INSERT INTO sample541 VALUES(
|
||||
(SELECT COUNT(*) FROM sample51),
|
||||
(SELECT COUNT(*) FROM sample54)
|
||||
);
|
||||
```
|
||||
`결과`
|
||||
|a|b|
|
||||
|-|-|
|
||||
|5|3|
|
||||
|
||||
### INSERT SELECT
|
||||
- `VALUES` 구 대신에 `SELECT` 명령을 사용하는 예를 살펴보자.
|
||||
|
||||
**`SELECT 결과를 INSERT하기`**
|
||||
```
|
||||
INSERT INTO sample541 SELECT 1, 2;
|
||||
```
|
||||
|
||||
`결과`
|
||||
|a|b|
|
||||
|-|-|
|
||||
|5|3|
|
||||
|1|2|
|
||||
|
||||
- 흔히 `INSERT SELECT`라 불리는 명령으로 `INSERT`와 `SELECT`를 합친 것과 같은 명령이 되었다.
|
||||
- 위 예제에서는 `SELECT`가 결괏값으로 1과 2라는 상수를 반환하므로, `INSERT INTO sample 541 VALUES (1, 2)`의 경우와 같다.
|
||||
- 이때 `SELECT` 명령이 반환하는 값이 꼭 스칼라 값일 필요는 없다.
|
||||
- `SELECT`가 반환하는 열 수와 자료형이 `INSERT`할 테이블과 일치하기만 하면 된다.
|
||||
- `INSERT SELECT` 명령은 `SELECT` 명령의 결과를 `INSERT INTO`로 지정한 테이블에 전부 추가한다.
|
||||
- `SELECT` 명령의 실행 결과를 클라이언트로 반환하지 않고 지정된 테이블에 추가하는 것이다.
|
||||
- 이 때문에 데이터의 복사나 이동을 할 때 자주 사용하는 명령이다.
|
||||
- 열 구성이 똑같은 테이블 사이에는 다음과 같은 `INSERT SELECT` 명령으로 행을 복사할 수도 있다.
|
||||
|
||||
**`테이블의 행 복사하기`**
|
||||
```
|
||||
INSERT INTO sample542 SELECT * FROM sample543;
|
||||
```
|
||||
|
||||
---
|
||||
184
도서/SQL첫걸음/Lecture24.md
Normal file
@@ -0,0 +1,184 @@
|
||||
# 24강. 상관 서브쿼리
|
||||
서브쿼리를 사용해 `DELETE` 명령과 `SELECT` 명령을 결합할 수 있었다. 스칼라 서브쿼리가 사용하기 쉬운 서브쿼리란 것도 알았다. 여기서는 서브쿼리의 일종인 `상관 서브쿼리`를 `EXISTS` 술어로 조합시켜서 서브쿼리를 사용하는 방법에 관해 알아본다.
|
||||
|
||||
**`EXISTS`**
|
||||
```
|
||||
EXISTS (SELECT 명령)
|
||||
```
|
||||
|
||||
- `EXISTS` 술어를 사용하면 서브쿼리가 반환하는 결괏값이 있는지를 조사할 수 있다.
|
||||
- 특히 `EXISTS`를 사용하는 경우에는 서브쿼리가 반드시 스칼라 값을 반환할 필요는 없다.
|
||||
- `EXISTS`는 단지 반환된 행이 있는지를 확인해보고 값이 있으면 참, 없으면 거짓을 반환하므로 어떤 패턴이라도 상관없다.
|
||||
|
||||
---
|
||||
|
||||
## 1. EXISTS
|
||||
- 서브쿼리를 사용해 검색할 때 `데이터가 존재하는지 아닌지` 판별하기 위해 조건을 지정할 수도 있다.
|
||||
- 이런 경우 `EXISTS` 술어를 이용해 조사할 수 있다.
|
||||
|
||||
`SELECT * FROM sample551;`
|
||||
|no|a|
|
||||
|-|-|
|
||||
|1|NULL|
|
||||
|2|NULL|
|
||||
|3|NULL|
|
||||
|4|NULL|
|
||||
|5|NULL|
|
||||
|
||||
`SELECT * FROM sample552;`
|
||||
|no2|
|
||||
|-|
|
||||
|3|
|
||||
|5|
|
||||
|
||||
지금부터 sample552에 no 열의 값과 같은 행이 있다면 '있음'이라는 값으로, 행이 없으면 '없음'이라는 값으로 갱신하도록 하겠습니다. 몇 가지 갱신 방법이 있지만 여기서는 `WHERE` 구에 조건을 지정해 '있음'으로 갱신하는 경우와 '없음'으로 갱신하는 경우로 나누어 처리한다.
|
||||
|
||||
```
|
||||
UPDATE sample551 SET a = '있음' WHERE ...
|
||||
UPDATE sample551 SET a = '없음' WHERE ...
|
||||
```
|
||||
|
||||
- 앞의 명령에서 `WHERE` 부분을 살펴보자. 여기서 단순하게 `no = 1`처럼 지정하는 방식으로는 처리할 수 없다.
|
||||
- 서브쿼리를 사용해 sample552에 행이 있는지부터 조사해야 한다.
|
||||
- 그리고 '있음'인 경우, 행이 존재하는 경우에 대해 참으로 설정한다.
|
||||
- 즉, 다음과 같이 `EXISTS`를 사용하면 조건에 맞는 행을 갱신할 수 있다.
|
||||
|
||||
**`EXISTS를 사용해 '있음'으로 갱신하기`**
|
||||
```
|
||||
UPDATE sample551 SET a = '있음' WHERE
|
||||
EXISTS (SELECT * FROM sample552 WHERE no2 = no);
|
||||
```
|
||||
|
||||
`결과`
|
||||
|no|a|
|
||||
|-|-|
|
||||
|1|NULL|
|
||||
|2|NULL|
|
||||
|3|있음|
|
||||
|4|NULL|
|
||||
|5|있음|
|
||||
|
||||
- 서브쿼리 부분이 `UPDATE`의 `WHERE` 구로 행을 검색할 때마다 차례로 실행되는 느낌이다.
|
||||
- 서브쿼리의 `WHERE` 구는 `no2 = no`라는 조건식으로 되어 있다.
|
||||
- no2는 sample552의 열이고 no는 sample551의 열이다. 이때 no가 3과 5일 때만 서브쿼리가 행을 반환한다.
|
||||
- `EXISTS` 술어에 서브쿼리를 지정하면 서브쿼리가 행을 반환할 경우에 참을 돌려준다.
|
||||
- 결과가 한 줄이라도 그 이상이라도 참이 된다. 반면 반환되는 행이 없을 경우에는 거짓이 된다.
|
||||
|
||||
---
|
||||
|
||||
## 2. NOT EXISTS
|
||||
- '없음'의 경우, 행이 존재하지 않는 상태가 참이 되므로 이때는 `NOT EXISTS`를 사용한다.
|
||||
- `NOT`을 붙이는 것으로 값을 부정할 수 있다.
|
||||
|
||||
**`NOT EXISTS를 사용해 '없음'으로 갱신하기`**
|
||||
```
|
||||
UPDATE sample551 SET a = '없음' WHERE
|
||||
NOT EXISTS (SELECT * FROM sample552 WHERE no2 = no);
|
||||
```
|
||||
|
||||
- 이처럼 서브쿼리를 이용해 다른 테이블의 상황을 판단하고 `UPDATE`로 갱신할 수 있었다.
|
||||
- `SELECT` 명령이나 `DELETE` 명령으로도 서브쿼리를 사용할 수 있다.
|
||||
|
||||
---
|
||||
|
||||
## 3. 상관 서브쿼리
|
||||
- 서브쿼리에는 명령 안에 중첩구조로 된 `SELECT` 명령이 존재한다.
|
||||
- 지금부터 '있음'으로 갱신하는 `UPDATE` 명령을 다시 살펴본다.
|
||||
|
||||
```
|
||||
UPDATE sample551 SET a = '있음' WHERE
|
||||
EXISTS (SELECT * FROM sample552 WHERE no2 = no);
|
||||
```
|
||||
|
||||
- `UPDATE` 명령(부모)에서 `WHERE` 구에 괄호로 묶은 부분이 서브쿼리(자식)가 된다.
|
||||
- 부모 명령에서는 sample551를 갱신한다.
|
||||
- 자식 서브쿼리에서는 sample552 테이블의 no2 열 값이 부모의 no 열 값과 일치하는 행을 검색한다.
|
||||
- 이처럼 부모 명령과 자식인 서브쿼리가 특정 관계를 맺는 것을 `상관 서브쿼리`라 부른다.
|
||||
- 앞서 23강에서 설명한 `DELETE`의 경우에는 상관 서브쿼리가 아니다. 상관 서브쿼리가 아닌 단순한 서브쿼리는 단독 쿼리로 실행할 수 있다.
|
||||
|
||||
```
|
||||
DELETE FROM sample54 WHERE a = (SELECT MIN(a) FROM sample54);
|
||||
```
|
||||
|
||||
- 하지만 상관 서브쿼리에서는 부모 명령과 연관되어 처리되기 때문에 서브쿼리 부분만을 따로 떼어내어 실행시킬 수 없다.
|
||||
|
||||
```
|
||||
UPDATE sample551 SET a = '있음' WHERE
|
||||
EXISTS (SELECT * FROM sample552 WHERE no2 = no);
|
||||
|
||||
SELECT * FROM sample552 WHERE no2 = no;
|
||||
-> 에러: no2가 불명확하다.
|
||||
```
|
||||
|
||||
### 테이블명 붙이기
|
||||
- 지금은 sample551과 sample552는 각각 열이 no와 no2로 서로 다르기 때문에 no가 sample551의 열, no2가 sample552의 열인 것을 알 수 있다.
|
||||
- 하지만 만약 두 열이 모두 같은 이름을 가진다면? `WHERE no = no`라고 조건을 지정하면 제대로 동작할까?
|
||||
|
||||
- 사실은 양쪽 테이블 모두 no라는 열로 되어있다면 잘 동작하지 않는다(대부분은 열이 애매하다는 내용의 에러가 발생한다).
|
||||
- 다만 `MySQL`에서는 서브쿼리의 `WHERE no = no`는 `WHERE sample552.no = sample552.no`가 되어 조건식은 항상 참이 된다. 결과적으로 `sample551`의 모든 행은 a열 값이 '있다'로 갱신된다.
|
||||
- 방금 언급한 사례가 정상적으로 처리되도록 하려면 열이 어느 테이블의 것인지 명시적으로 나타낼 필요가 있다.
|
||||
- 테이블 지정은 간단하다. 열명 앞에 `테이블명.`을 붙이기만 하면 된다.
|
||||
- 예를 들어 no 열이 sample551의 것이라면 `sample551.no`라고 지정한다.
|
||||
- 마찬가지로 no2의 경우에는 `sample552.no2`로 지정한다.
|
||||
- 이것으로 sample551과 sample552가 열 이름이 같아도 제대로 구별되므로 문제 없이 실행할 수 있다.
|
||||
|
||||
**`열에 테이블명 붙이기`**
|
||||
```
|
||||
UPDATE sample551 SET a = '있음' WHERE
|
||||
EXISTS (SELECT * FROM sample552 WHERE sample552.no2 = sample551.no);
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 4. IN
|
||||
- 스칼라 값끼리 비교할 때는 `=` 연산자를 사용한다. 다만 집합을 비교할 때는 사용할 수 없다.
|
||||
- `IN`을 사용하면 집합 안의 값이 존재하는지를 조사할 수 있다.
|
||||
- 서브쿼리를 사용할 때 `IN`을 통해 비교하는 경우도 많다.
|
||||
- sample552에는 3과 5라는 값이 존재하는데, 서브쿼리를 사용하지 않고 `WHERE` 구로 간단하게 처리한다면 다음과 같이 조건을 붙일 수 있다.
|
||||
- 이처럼 특정 열의 값이 `무엇 또는(OR) 무엇`이라는 조건식을 지정하는 경우 `IN`을 사용하면 간단하게 지정할 수 있다.
|
||||
|
||||
```
|
||||
WHERE no = 3 OR no = 5;
|
||||
```
|
||||
|
||||
**`IN`**
|
||||
```
|
||||
열명 IN(집합)
|
||||
```
|
||||
|
||||
- `IN`에서는 오른쪽에 집합을 지정한다.
|
||||
- 왼쪽에 지정된 값과 같은 값이 집합 안에 존재하면 참을 반환한다.
|
||||
- 집합은 상수 리스트를 괄호로 묶어 기술한다.
|
||||
- 앞의 `WHERE` 조건식을 `IN`을 사용하도록 수정하면 다음과 같다.
|
||||
- `IN`으로 지정한 값이 3과 5밖에 없어 `OR`로 기술했을 때와 별 차이가 없는 것 같지만, 값을 여러개 지정할 경우에는 조건식이 상당히 깔끔해진다.
|
||||
|
||||
**`IN을 사용해 조건식 기술`**
|
||||
```
|
||||
SELECT * FROM sample551 WHERE no IN (3, 5);
|
||||
```
|
||||
|
||||
- 한편, 집합 부분은 서브쿼리로도 지정할 수 있다. 상수 리스트 부분을 서브쿼리로 바꾸어 보면 다음과 같다.
|
||||
|
||||
**`IN의 오른쪽을 서브쿼리로 지정하기`**
|
||||
```
|
||||
SELECT * FROM sample551 WHERE no IN (SELECT no2 FROM sample552);
|
||||
```
|
||||
|
||||
- 이 같은 경우 서브쿼리는 스칼라 서브쿼리가 될 필요는 없다.
|
||||
- `IN`에는 집합을 지정할 수 있기 때문에 이전에 스칼라 값을 설명할 때 언급한 패턴을 들자면 1과 2의 패턴으로 지정할 필요가 있다.
|
||||
- 반면 3과 4의 패턴에서는 열이 복수로 지정되므로 비교할 수 없다. `IN`의 왼쪽에는 하나의 열이 지정되어 있기 때문이다.
|
||||
- `IN`은 집합 안에 값이 포함되어 있으면 참이 된다. 반면 `NOT IN`으로 지정하면 집합에 값이 포함되어 있지 않을 경우 참이 된다.
|
||||
|
||||
### IN과 NULL
|
||||
- 집계함수에서는 집합 안의 `NULL` 값을 무시하고 처리했다.
|
||||
- `IN`에서는 집합 안에 `NULL` 값이 있어도 무시하지는 않는다.
|
||||
- 다만 `NULL = NULL`을 제대로 계산할 수 없으므로 `IN`을 사용해도 `NULL` 값은 비교할 수 없다.
|
||||
- 즉, `NULL`을 비교할 때는 `IS NULL`을 사용해야 한다. 또한 `NOT IN`의 경우, 집합 안에 `NULL` 값이 있으면 설령 왼쪽 값이 집합 안에 포함되어 있지 않아도 참을 반환하지 않는다.
|
||||
- 그 결과는 `불명(UNKNOWN)`이 된다.
|
||||
- `MySQL`에서 집합에 `NULL`이 포함되어 있는 경우, 조건식 `IN`은 왼쪽 값이 집합에 포함되어 있으면 참을, 그렇지 않으면 `NULL`을 반환한다.
|
||||
- `NOT IN`은 왼쪽 값이 집합에 포함되어 있으면 거짓을, 그렇지 않으면 `NULL`을 반환한다.
|
||||
- 결국 `NOT IN`의 경우 집합에 `NULL`이 포함되어 있다면 그 결괏값은 0건이 된다.
|
||||
- `NULL`을 반환한다는 것은 비교할 수 없다는 것을 의미한다.
|
||||
- 왼쪽의 값이 `NULL`인 경우에도 오른쪽의 값과 관계없이 비교할 수 없으므로 조건식은 참 또는 거짓이 아닌 `NULL`을 반환한다.
|
||||
|
||||
---
|
||||
51
도서/SQL첫걸음/Lecture25.md
Normal file
@@ -0,0 +1,51 @@
|
||||
# 25강. 데이터베이스 객체
|
||||
데이터베이스 객체의 종류와 관리하는 방법에 대해서 알아본다.
|
||||
|
||||
- 처음 `RDBMS` 소프트웨어를 설치하면 데이터베이스는 비어있는 상태이다.
|
||||
- 여기에 테이블이나 뷰, 인덱스, 프로시저 등의 데이터베이스 객체를 작성해 데이터베이스를 구축한다.
|
||||
|
||||
---
|
||||
|
||||
## 1. 데이터베이스 객체
|
||||
- 데이터베이스 객체란 테이블이나 뷰, 인덱스 등 데이터베이스 내에 정의하는 모든 것을 일컫는 말이다.
|
||||
- 데이터베이스 내의 객체라는 의미로 `데이터베이스 객체`라고 부르는 것이다(C++이나 자바에서 사용하는 객체지향 프로그래밍의 '객체'와 다르다).
|
||||
- 객체는 데이터베이스 내에 실체를 가지는 어떤 것을 말한다.
|
||||
- 객체의 종류에 따라 데이터베이스에 저장되는 내용도 달라진다.
|
||||
- 테이블의 경우 행과 열이 저장된다.
|
||||
- 한편 `SELECT`나 `INSERT` 등은 클라이언트에서 객체를 조작하는 SQL 명령인데, 데이터베이스 내에 존재하는 것이 아니므로 객체라 부를 수 없다.
|
||||
- 객체는 이름을 가지며, 데이터베이스 내에서 객체를 작성할 때는 이름이 겹치지 않도록 해야 한다.
|
||||
- 객체 이외에도 테이블의 열 또한 이름을 가지며 그 밖에 `SELECT` 명령에서 열에 별명을 붙일 수도 있다.
|
||||
- 다만 열이나 별명은 객체가 아니다. 한 가지 동일한 점은 이름을 붙일 때 임의의 규칙에 맞게 지정해야 한다는 사실이다.
|
||||
|
||||
이름을 붙일 때는 다음과 같은 제약 사항(명명규칙)을 따른다.
|
||||
- 기존 이름이나 예약어와 중복하지 않는다.
|
||||
- 숫자로 시작할 수 없다.
|
||||
- `언더스코어(_)` 이외의 기호는 사용할 수 없다.
|
||||
- 한글을 사용할 때는 `더블쿼트(MySQL에서는 백쿼트)`로 둘러싼다.
|
||||
- 시스템이 허용하는 길이를 초과하지 않는다.
|
||||
|
||||
- 객체의 이름은 꽤 중요하다. 어떤 데이터가 저장되어 있는지 파악하는 기준이 되는 경우가 많으므로 의미 없는 번호 등으로 이름을 붙이지 않도록 해야 한다.
|
||||
- 한편 이름은 객체의 종류와는 관계없다는 것에 주의해야 한다.
|
||||
- 예를 들어 foo라는 이름의 테이블을 한번 만들면, 같은 종류의 테이블은 물론이고 뷰와 같은 다른 종류의 객체 역시 똑같은 이름으로 작성할 수 없다.
|
||||
|
||||
##### 의미없는 이름을 붙이지 않도록 한다!
|
||||
|
||||
---
|
||||
|
||||
## 2. 스키마
|
||||
- 데이터베이스 객체는 `스키마`라는 그릇 안에 만들어진다.
|
||||
- 따라서 객체의 이름이 같아도 스키마가 서로 다르면 상관없다.
|
||||
- 이와 같은 특징 때문에 데이터베이스 객체는 `스키마 객체`라 불리기도 한다.
|
||||
- 실제로 데이터베이스에 테이블을 작성해서 구축해나가는 작업을 `스키마 설계`라고 부른다.
|
||||
- 이때 스키마는 SQL 명령의 DDL을 이용하여 정의한다.
|
||||
- 어떤 것이 스키마가 되는지는 데이터베이스 제품에 따라 달라진다.
|
||||
- `MySQL`에서는 `CREATE DATABASE` 명령으로 작성한 `데이터베이스`가 스키마가 된다.
|
||||
- 한편 `Oracle` 등에서는 데이터베이스와 데이터베이스 사용자가 계층적 스키마가 된다.
|
||||
- 테이블과 스키마는 무엇인가를 담는 그릇 역할을 한다는 점에서 비슷하다.
|
||||
- 테이블 안에는 열을 정의할 수 있고 스키마 안에는 테이블을 정의할 수 있다.
|
||||
- 각각의 그릇 안에서는 중복하지 않도록 이름을 지정한다.
|
||||
- 이처럼 이름이 충돌하지 않도록 기능하는 그릇을 `네임스페이스(namespace)`라고 부르기도 한다.
|
||||
|
||||
##### 스키마나 테이블은 네임스페이스이기도 하다!
|
||||
|
||||
---
|
||||
204
도서/SQL첫걸음/Lecture26.md
Normal file
@@ -0,0 +1,204 @@
|
||||
# 26강. 테이블 작성, 삭제, 변경
|
||||
대표적인 데이터베이스 객체인 테이블을 작성, 삭제, 변경하는 방법에 대해 알아본다.
|
||||
|
||||
**`테이블의 작성, 삭제, 변경`**
|
||||
```
|
||||
CREATE TABLE 테이블명 (열 정의1, 열 정의2, ...)
|
||||
DROP TABLE 테이블명
|
||||
ALTER TABLE 테이블명 하부명령
|
||||
```
|
||||
|
||||
- `SELECT`, `INSERT`, `DELETE`, `UPDATE`는 SQL 명령 중에서도 `DML`로 분류된다.
|
||||
- `DML`은 데이터를 조작하는 명령이다. 한편, `DDL`은 데이터를 정의하는 명령으로, 스키마 내의 객체를 관리할 때 사용한다.
|
||||
|
||||
---
|
||||
|
||||
## 1. 테이블 작성
|
||||
- `DDL`은 모두 같은 문법을 사용한다.
|
||||
- `CREATE`로 작성, `DROP`으로 삭제, `ALTER`로 변경할 수 있다.
|
||||
- 뒤이어 어떤 객체를 작성, 삭제, 변경할지를 지정한다.
|
||||
- 예를 들어 테이블을 작성한다면 `CREATE TABLE`, 뷰를 작성한다면 `CREATE VIEW`와 같이 지정하면 된다.
|
||||
- `RDBMS`에서 데이터베이스 상에 제일 먼저 만드는 객체 중 하나가 바로 테이블이다.
|
||||
- 이때 `CREATE TABLE` 명령을 사용한다.
|
||||
- `CREATE TABLE`에 이어서 작성하고 싶은 테이블의 이름을 지정한다.
|
||||
- 테이블명 뒤에서는 괄호로 묶어 열을 정의할 수 있으며, 열을 정의할 때는 테이블에 필요한 열을 `콤마(,)`로 구분하여 연속해 지정한다.
|
||||
|
||||
**`CREATE TABLE`**
|
||||
```
|
||||
CREATE TABLE 테이블명 (
|
||||
열 정의1,
|
||||
열 정의2,
|
||||
...
|
||||
)
|
||||
```
|
||||
|
||||
- 열명은 열에 붙이는 이름이며, 명명규칙에 맞게 이름을 붙여준다.
|
||||
- 자료형은 `INTEGER`나 `VARCHAR` 등을 지정한다.
|
||||
- 특히 `CHAR`나 `VARCHAR`와 같은 문자열형으로 지정할 때는 최대길이를 괄호로 묶어줘야 한다.
|
||||
- 기본값을 설정할 때는 `DEFAULT`로 지정하되 자료형에 맞는 리터럴로 기술하며, 기본값은 생략할 수 있다.
|
||||
- 마지막으로 열이 `NULL`을 허용할 것인지를 지정한다.
|
||||
- `NULL`을 명시적으로 지정하거나 생략했을 경우는 `NULL`을 허용한다.
|
||||
- 한편 `NOT NULL`이라고 지정하면 제약이 걸리면서 `NULL`이 허용되지 않는다.
|
||||
|
||||
**`열 정의`**
|
||||
```
|
||||
열명 자료형 [DEFAULT 기본값] [NULL|NOT NULL]
|
||||
```
|
||||
|
||||
##### CREATE TABLE로 테이블을 작성할 수 있다!
|
||||
|
||||
---
|
||||
|
||||
## 2. 테이블 삭제
|
||||
- 필요 없는 테이블은 삭제할 수 있는데, 이때 `DROP TABLE` 명령을 사용한다.
|
||||
|
||||
**`DROP TABLE`**
|
||||
```
|
||||
DROP TABLE 테이블명
|
||||
```
|
||||
|
||||
- `DROP TABLE`에서 지정하는 것은 테이블명 뿐이다. 이때 주의할 점은 많은 데이터베이스가 SQL 명령을 실행할 때 확인을 요구하지 않는다는 것이다.
|
||||
- `OS`의 경우(제품에 따라 다르기는 하지만) 삭제 명령으로 파일을 모두 삭제하려 하면 `정말 삭제하겠습니까?`라는 메시지가 표시된다.
|
||||
- 하지만 SQL 명령의 경우 사용자에게 이와 같은 확인은 하지 않는다. 실수로 테이블을 삭제하지 않도록 신중하게 `DROP TABLE`을 실행해야 한다.
|
||||
|
||||
##### DROP TABLE로 테이블을 삭제할 수 있다!
|
||||
|
||||
### 데이터 행 삭제
|
||||
- `DROP TABLE` 명령은 데이터베이스에서 테이블을 삭제한다. 이때 테이블에 저장된 데이터도 함께 삭제된다.
|
||||
- 한편 테이블 정의는 그대로 둔채 데이터만 삭제할 때는 `DELETE` 명령을 사용한다.
|
||||
- 이때 `DELETE` 명령에 `WHERE` 조건을 지정하지 않으면 테이블의 모든 행을 삭제할 수 있다.
|
||||
- 하지만 `DELETE` 명령은 행 단위로 여러 가지 내부처리가 일어나므로 삭제할 행이 많으면 처리속도가 상당히 늦어진다.
|
||||
- 이런 경우에는 `DDL`로 분류되는 `TRUNCATE TABLE` 명령을 사용한다.
|
||||
- `TRUNCATE TABLE` 명령은 삭제할 행을 지정할 수 없고 `WHERE` 구를 지정할 수도 없지만, 모든 행을 삭제해야 할 때 빠른 속도로 삭제할 수 있다.
|
||||
|
||||
**`TRUNCATE TABLE`**
|
||||
```
|
||||
TRUNCATE TABLE 테이블명
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 3. 테이블 변경
|
||||
- 테이블을 작성해버린 뒤에도 열 구성은 얼마든지 변경할 수 있다. 이때 테이블 변경은 `ALTER TABLE` 명령을 통해 이루어진다.
|
||||
|
||||
**`ALTER TABLE`**
|
||||
```
|
||||
ALTER TABLE 테이블명 변경명령
|
||||
```
|
||||
|
||||
- 테이블을 작성한 뒤에도 열을 추가하거나 데이터 최대길이를 변경하는 등 구성을 바꿔야 하는 경우가 종종 생기는데, 이때 테이블이 비어있다면 `DROP TABLE`로 테이블을 삭제하고 나서 변경할 테이블 구조에 맞추어 `CREATE TABLE`을 실행해 테이블을 변경할 수 있다.
|
||||
- 하지만 테이블에 데이터가 이미 존재하는 경우라면 `DROP TABLE`로 테이블을 삭제하는 순간 기존 데이터도 모두 삭제된다.
|
||||
- 이때 `ALTER TABLE` 명령을 사용하면 테이블에 저장되어 있는 데이터는 그대로 남긴 채 구성만 변경할 수 있다.
|
||||
|
||||
`ALTER TABLE`로 할 수 있는 일은 크게 다음과 같이 두 가지로 분류할 수 있다.
|
||||
|
||||
- 열추가, 삭제, 변경
|
||||
- 제약 추가, 삭제
|
||||
|
||||
### 열 추가
|
||||
- `ALTER TABLE`에서 열을 추가할 때는 `ADD 하부명령`을 통해 실행할 수 있다.
|
||||
|
||||
**`열 추가`**
|
||||
```
|
||||
ALTER TABLE 테이블명 ADD 열 정의
|
||||
```
|
||||
|
||||
- 여기에서의 열 정의는 `CREATE TABLE`의 경우와 동일하다.
|
||||
- 즉, 열 이름과 각 자료형을 지정하고 필요에 따라 기본값과 `NOT NULL` 제약을 지정하면 된다. 물론 열의 이름이 중복되면 열을 추가할 수 없다.
|
||||
|
||||
`ALTER TABLE sample62 ADD newcol INTEGER;`
|
||||
|
||||
##### ALTER TABLE ADD로 테이블에 열을 추가할 수 있다!
|
||||
|
||||
- `ALTER TABLE ADD`로 열을 추가할 때, 기존 데이터행이 존재하면 추가한 열의 값이 모두 `NULL`이 된다.
|
||||
- 물론 기본값이 지정되어 있으면 기본값으로 데이터가 저장된다.
|
||||
- 한편 `NOT NULL` 제약을 붙인 열을 추가하고 싶다면 먼저 `NOT NULL`로 제약을 건 뒤에 `NULL` 이외의 값으로 기본값을 지정할 필요가 있다.
|
||||
|
||||
##### NOT NULL 제약이 걸린 열을 추가할 때는 기본값을 지정해야 한다!
|
||||
|
||||
### 열 속성 변경
|
||||
- `ALTER TABLE`로 열 속성을 변경할 경우에는 다음과 같이 `MODIFY 하부명령`을 실행한다.
|
||||
|
||||
**`열 속성 변경`**
|
||||
```
|
||||
ALTER TABLE 테이블명 MODIFY 열 정의
|
||||
```
|
||||
|
||||
- 이때도 열 정의는 `CREATE TABLE`의 경우와 동일하다.
|
||||
- `MODIFY`로 열 이름은 변경할 수 없지만, 자료형이나 기본값, `NOT NULL` 제약 등의 속성은 변경할 수 있다.
|
||||
|
||||
**`ALTER TABLE로 열 속성 변경하기`**
|
||||
```
|
||||
ALTER TABLE sample62 MODIFY newcol VARCHAR(20);
|
||||
```
|
||||
|
||||
- 기존의 데이터 행이 존재하는 경우, 속성 변경에 따라 데이터 역시 변환된다.
|
||||
- 이때 만약 자료형이 변경되면 테이블에 들어간 데이터의 자료형 역시 바뀐다.
|
||||
- 다만 그 처리과정에서 에러가 발생하면 `ALTER TABLE` 명령은 실행되지 않는다.
|
||||
- `ALTER TABLE`은 비교적 새로운 명령에 속한다. 표준화가 미처 이루어지지 않은 부분도 있어 데이터베이스에 따라 고유한 방언이 존재한다.
|
||||
- 예를 들어 `MODIFY`는 `MySQL`과 `Oracle`에서 사용할 수 있는 `ALTER TABLE`의 하부명령이다. 다른 데이터베이스에서는 `ALTER` 하부명령으로 열 속성을 변경하기도 한다.
|
||||
|
||||
### 열 이름 변경
|
||||
- `ALTER TABLE`로 열 이름을 변경할 때는 `CHANGE` 하부명령으로 시행할 수 있다.
|
||||
|
||||
**`열 이름 변경`**
|
||||
```
|
||||
ALTER TABLE 테이블명 CHANGE [기존 열 이름] [신규 열 정의]
|
||||
```
|
||||
|
||||
- 열 이름을 변경할 때는 `MODIFY`가 아닌 `CHANGE`를 사용한다.
|
||||
- `CHANGE`는 열 이름뿐만 아니라 열 속성도 변경할 수 있다.
|
||||
- 한편, `Oracle`에서는 열 이름을 변경할 경우 `RENAME TO` 하부명령을 사용한다.
|
||||
|
||||
**`ALTER TABLE로 열 이름 변경하기`**
|
||||
```
|
||||
ALTER TABLE sample62 CHANGE newcol c VARCHAR(20);
|
||||
```
|
||||
|
||||
### 열 삭제
|
||||
- `ALTER TABLE`로 열을 삭제할 떄는 `DROP` 하부명령을 사용한다.
|
||||
|
||||
**`열 삭제`**
|
||||
```
|
||||
ALTER TABLE 테이블명 DROP 열명
|
||||
```
|
||||
|
||||
- `DROP` 뒤에 삭제하고 싶은 열명을 지정한다. 물론, 테이블에 존재하지 않는 열이 지정되면 에러가 발생한다.
|
||||
|
||||
**`ALTER TABLE로 열 삭제하기`**
|
||||
```
|
||||
ALTER TABLE sample62 DROP c;
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 4. ALTER TABLE로 테이블 관리
|
||||
여기서는 실제 업무에서 자주 사용하는 `ALTER TABLE`을 이용한 테이블 관리 예를 소개한다.
|
||||
|
||||
### 최대길이 연장
|
||||
- 실제로 시스템을 운용하다 보면 처음에는 한 자리로 충분했던 용량이 시간이 지나면서 부족해지는 일이 많다.
|
||||
- 이러한 경우 `ALTER TABLE`로 열의 자료형만 변경해 대응할 수 있다.
|
||||
- 열의 자료형은 처음 `CREATE TABLE`을 실행할 때 결정된다.
|
||||
- 특히 문자열형의 경우 최대길이를 지정하는데, 이 최대길이를 `ALTER TABLE`로 늘릴 수 있다.
|
||||
|
||||
`ALTER TABLE sample MODIFY col VARCHAR(30)`
|
||||
|
||||
- 반대로 저장공간을 늘리기 위해 최대길이를 줄이고 싶은 경우도 있을 것이다. 다만, 이때는 여러 가지 문제가 발생한다.
|
||||
- 먼저 기존의 행에 존재하는 데이터의 길이보다 작게 지정할 수는 없다.
|
||||
- 작게 지정하면 저장된 데이터의 일부가 잘려나가므로 에러가 발생하기 때문이다.
|
||||
- 또한 열의 최대길이를 줄였다고 해서 실제 저장공간이 늘어나는 경우도 적다.
|
||||
- 일반적으로 최대길이를 늘리는 경우는 많지만 줄이는 경우는 별로 없다.
|
||||
|
||||
### 열 추가
|
||||
- 테이블에 열을 추가하는 일은 자주 일어난다.
|
||||
- 시스템의 기능 확장 등 이유는 여러 가지가 있는데, 이때 사용하는 `ALTER TABLE` 명령은 다음과 같다.
|
||||
|
||||
`ALTER TABLE sample ADD new_col INTEGER`
|
||||
|
||||
- 보통 열을 추가하는 정도로는 시스템 쪽에 미치는 영향이 적을 것 같지만, 테이블 정의가 바뀌어버리는 일인 만큼 꽤 영향을 준다.
|
||||
- 적어도, 변경한 테이블에 행을 추가하는 `INSERT` 명령은 확인해야 한다.
|
||||
- 열을 추가하면 해당 열에 대해 데이터 값을 지정해야 하기 때문이다.
|
||||
- 기존 시스템에서 추가한 열에 대해서는 별다른 처리를 하지 않아도 문제없다 해도 일단은 확인하는 편이 낫다.
|
||||
- 만약 기존 시스템의 `INSERT` 명령에서 열 지정이 생략되어 있다면, 열을 추가한 후 그대로 실행했을 때 열의 개수가 맞지 않아 에러가 발생한다.
|
||||
|
||||
---
|
||||
198
도서/SQL첫걸음/Lecture27.md
Normal file
@@ -0,0 +1,198 @@
|
||||
# 27강. 제약
|
||||
`CREATE TABLE`로 테이블을 정의할 경우, 열 이외에 제약도 정의할 수 있었다. 그중 하나가 바로 `NOT NULL` 제약이다. `NOT NULL` 이외에도 다양한 제약에 대해서 알아본다.
|
||||
|
||||
- 테이블에 제약을 설정함으로써 저장될 데이터를 제한할 수 있다.
|
||||
- 예를 들어 `NOT NULL` 제약은 `NULL` 값이 저장되지 않도록 제한한다.
|
||||
- `NOT NULL` 제약 외에도 `기본키(Primary Key)` 제약이나 `외부참조(정합)` 제약 등이 있다.
|
||||
- 복수의 테이블 사이에서 정합성을 유지하기 위해 설정하는 것으로 테이블 간에는 부모 자식과 같은 관계를 가지며 정합성을 유지한다.
|
||||
- 자식 테이블 측에서는 `외부키(FOREIGN KEY)`를 지정해 부모 테이블을 참조한다.
|
||||
- 부모 테이블에서 참조될 열은 반드시 `유일성(UNIQUE KEY, PRIMARY KEY)`을 가진다.
|
||||
- 이 제약은 데이터에비스 설계에도 영향을 주는 중요한 개념이다.
|
||||
- 특히 기본키 제약은 `RDBMS`에서 반드시 언급되는 사항이므로 추가나 삭제 방법을 확실하게 알아두자.
|
||||
|
||||
---
|
||||
|
||||
## 1. 테이블 작성시 제약 정의
|
||||
- 제약은 테이블에 설정하는 것이다.
|
||||
- `CREATE TABLE`로 테이블을 작성할 때 제약을 같이 정의한다.
|
||||
- 물론 `ALTER TABLE`로 제약을 지정하거나 변경할 수 있다.
|
||||
- 이때 `NOT NULL` 제약 등 하나의 열에 대해 설정하는 제약은 열을 정의할 때 지정한다.
|
||||
- 다음은 `NOT NULL` 제약과 `UNIQUE` 제약을 설정한 예이다.
|
||||
|
||||
**`테이블 열에 제약 정의하기`**
|
||||
```
|
||||
CREATE TABLE sample631 (
|
||||
a INTEGER NOT NULL,
|
||||
b INTEGER NOT NULL UNIQUE,
|
||||
c VARCHAR(30)
|
||||
);
|
||||
```
|
||||
|
||||
- a 열에는 `NOT NULL` 제약이 걸려있다.
|
||||
- b 열에는 `NOT NULL` 제약과 `UNIQUE` 제약이 걸려있다.
|
||||
- c 열에는 제약이 지정되어 있지 않다.
|
||||
- 이처럼 열에 대해 정의하는 제약을 `열 제약`이라고 부른다.
|
||||
- `복수열에 의한 기본키 제약`처럼 한 개의 제약으로 복수의 열에 제약을 설정하는 경우를 `테이블 제약`이라 부른다.
|
||||
|
||||
**`테이블에 테이블 제약 정의하기`**
|
||||
```
|
||||
CREATE TABLE sample632 (
|
||||
no INTEGER NOT NULL,
|
||||
sub_no INTEGER NOT NULL,
|
||||
name VARCHAR(30),
|
||||
PRIMARY KEY (no, sub_no)
|
||||
);
|
||||
```
|
||||
|
||||
- 제약에는 이름을 붙일 수 있다. 제약에 이름을 붙이면 나중에 관리하기 쉬워지므로 가능한 한 이름을 붙이도록 하자.
|
||||
- 제약 이름은 `CONSTRAINT` 키워드를 사용해서 지정한다.
|
||||
|
||||
**`테이블 제약에 이름 붙이기`**
|
||||
```
|
||||
CREATE TABLE sample632 (
|
||||
no INTEGER NOT NULL,
|
||||
sub_no INTEGER NOT NULL,
|
||||
name VARCHAR(30),
|
||||
CONSTRAINT pkey_sample PRIMARY KEY (no, sub_no)
|
||||
);
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 2. 제약 추가
|
||||
- 기존 테이블에도 나중에 제약을 추가할 수 있다. 이때 열 제약과 테이블 제약은 조금 다른 방법으로 추가한다.
|
||||
|
||||
### 열 제약 추가
|
||||
- 열 제약을 추가할 경우 `ALTER TABLE`로 열 정의를 변경할 수 있다.
|
||||
- 기존 테이블을 변경할 경우에는 제약을 위반하는 데이터가 있는지 먼저 검사한다.
|
||||
- 만약 c 열에 `NULL` 값이 존재한다면 `ALTER TABLE` 명령은 에러가 발생한다.
|
||||
|
||||
다음은 c 열에 `NOT NULL` 제약을 설정하는 예이다.
|
||||
|
||||
**`c열에 NOT NULL 제약 걸기`**
|
||||
```
|
||||
ALTER TABLE sample631 MODIFY c VARCHAR(30) NOT NULL;
|
||||
```
|
||||
|
||||
### 테이블 제약 추가
|
||||
- 테이블 제약은 `ALTER TABLE`의 `ADD` 하부명령으로 추가할 수 있다.
|
||||
- 다음 예제는 기본키 제약을 추가하는 예이다.
|
||||
- 기본키는 테이블에 하나만 설정할 수 있다. 이미 기본키가 설정되어 있는 테이블에 추가로 기본키를 작성할 수는 없다.
|
||||
- 또, 열 제약을 추가할 때와 마찬가지로 기존의 행을 검사해 추가할 제약을 위반하는 데이터가 있으면 에러가 발생한다.
|
||||
|
||||
**`기본키 제약 추가하기`**
|
||||
```
|
||||
ALTER TABLE sample631 ADD CONSTRAINT pkey_sample631 PRIMARY KEY(a);
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 3. 제약 삭제
|
||||
- 테이블 제약은 나중에 삭제할 수도 있다.
|
||||
- 열 제약의 경우, 제약을 추가할 때와 동일하게 열 정의를 변경합니다.
|
||||
- 다음은 앞서 추가한 c 열의 `NOT NULL` 제약을 삭제하는 `ALTER TABLE`의 예이다.
|
||||
|
||||
**`c열의 NOT NULL 제약 없애기`**
|
||||
```
|
||||
ALTER TABLE sample631 MODIFY c VARCHAR(30);
|
||||
```
|
||||
|
||||
- 한편 테이블 제약은 `ALTER TABLE`의 `DROP` 하부명령으로 삭제할 수 있다.
|
||||
- 삭제할 때는 제약명을 지정한다.
|
||||
|
||||
**`pkey_sample631 제약 삭제하기`**
|
||||
```
|
||||
ALTER TABLE sample631 DROP CONSTRAINT pkey_sample631;
|
||||
```
|
||||
|
||||
- 단, 기본키는 테이블당 하나만 설정할 수 있기 때문에 다음처럼 굳이 제약명을 지정하지 않고도 삭제할 수 있다.
|
||||
|
||||
**`기본키 제약 삭제하기`**
|
||||
```
|
||||
ALTER TABLE sample631 DROP PRIMARY KEY;
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 4. 기본키
|
||||
- `CREATE TABLE`, `ALTER TABLE`을 통해 제약의 정의, 추가, 삭제에 관해 알아보았다.
|
||||
- `NOT NULL` 제약은 열 제약이며, 기본키 제약이 테이블 제약이라는 것도 알았다.
|
||||
- 이때 `NOT NULL` 제약을 설정하려면 대상 열에는 `NULL` 값이 존재하지 않아야 한다.
|
||||
- 그렇다면 기본키 제약을 설정하기 위해서는 테이블은 어떤 조건을 만족해야 할까?
|
||||
|
||||
**`sample634 테이블 작성하기`**
|
||||
```
|
||||
CREATE TABLE sample634 (
|
||||
p INTEGER NOT NULL,
|
||||
a VARCHAR(30),
|
||||
CONSTRAINT pkey_sample634 PRIMARY KEY(p)
|
||||
);
|
||||
```
|
||||
|
||||
- 열 p가 sample634 테이블의 기본키이다. 덧붙이자면 기본키로 지정할 열은 `NOT NULL` 제약이 설정되어 있어야 한다.
|
||||
- 데이터베이스에는 열쇠를 뜻하는 `키(key)`라는 단어가 자주 나온다.
|
||||
- `검색키`와 같이 `OO키`의 형태로 쓰이는 경우가 많다.
|
||||
- 이때 검색키는 검색할 때의 키워드라고 하면 이해하기 쉽다.
|
||||
- 즉, 대량의 데이터에서 원하는 데이터를 찾아낼 때 키가 되는 요소를 지정해 검색하는 것이다.
|
||||
- 기본키는 테이블의 행 한 개를 특정할 수 있는 검색키이다.
|
||||
- 기본키 제약이 설정된 테이블에서는 기본키로 검색했을 때 복수의 행이 일치하는 데이터를 작성할 수 없다.
|
||||
- 간단히 말하면, 기본키로 설정된 열이 중복하는 데이터 값을 가지면 제약에 위반된다.
|
||||
|
||||
**`sample634에 행 추가하기`**
|
||||
```
|
||||
INSERT INTO sample634 VALUES (1, '첫째줄');
|
||||
INSERT INTO sample634 VALUES (2, '둘째줄');
|
||||
INSERT INTO sample634 VALUES (3, '셋째줄');
|
||||
```
|
||||
|
||||
- `INSERT`를 사용해 sample634에 세 개의 행을 추가했는데, 이때 p 열의 값이 각각 1, 2, 3으로 중복하지 않는다.
|
||||
- 여기서 이미 존재하는 값인 2로 다시 한 번 행을 추가하면 이 `INSERT` 명령은 기본키 제약에 위반되어 행을 추가할 수 없다. p 열의 값이 중복되기 때문이다.
|
||||
- 그 결과 `기본키 제약에 위반된다`는 내용의 에러가 표시된다.
|
||||
|
||||
**`sample634에 중복하는 행 추가하기`**
|
||||
```
|
||||
INSERT INTO sample634 VALUES (2, '넷째줄');
|
||||
|
||||
ERROR 1062 (23000): Duplicate entry '2' for key 'PRIMARY'
|
||||
```
|
||||
|
||||
- 한편 `UPDATE` 명령을 실행할 때도 제약을 위반하는 값이 없는지 검사한다.
|
||||
- 다음과 같은 `UPDATE` 명령 역시 제약에 위반되므로 실행되지 않는다.
|
||||
- p가 3인 행을 2로 갱신하는 데 성공하면 `p = 2`인 열이 두 개나 존재해 버리기 때문이다.
|
||||
|
||||
**`sample634을 중복된 값으로 갱신하기`**
|
||||
```
|
||||
UPDATE sample634 SET p = 2 WHERE p = 3;
|
||||
|
||||
ERROR 1062 (23000): Duplicate entry '2' for key 'PRIMARY'
|
||||
```
|
||||
|
||||
- 이처럼 열을 기본키로 지정해 유일한 값을 가지도록 하는 구조가 바로 `기본키 제약`이다.
|
||||
- 행이 유일성을 필요로 한다는 다른 의미에서 `유일성 제약`이라 불리기도 한다.
|
||||
|
||||
##### 기본키 제약이 설정된 열에는 중복된 값을 지정할 수 없다!
|
||||
|
||||
### 복수의 열로 기본키 구성하기
|
||||
- 기본키 제약에는 이를 구성할 열 지정이 필요하다.
|
||||
- 이때 지정된 열은 `NOT NULL` 제약이 설정되어 있어야 한다.
|
||||
- 즉, 기본키로는 `NULL` 값이 허용되지 않는다.
|
||||
- 또한 기본키를 구성하는 열은 복수라도 상관없다.
|
||||
- 복수의 열을 기본키로 지정했을 경우, 키를 구성하는 모든 열을 사용해서 중복하는 값이 있는지 없는지를 검사한다.
|
||||
- 예를 들어 a 열과 b 열로 기본키를 지정했을 경우를 생각해보자.
|
||||
- 다음과 같이 a 열만을 봤을 때는 중복하는 값이 있지만, b 열이 다르면 키 전체로서는 중복하지 않는다고 간주되기 때문에 기본키 제약에 위반되지 않는다.
|
||||
- 만약 이 상태에서 키가 완전히 동일한 데이터값으로 `INSERT` 명령을 실행하면 기본키 제약에 위반된다.
|
||||
|
||||
**`a 열과 b 열로 이루어진 기본키`**
|
||||
```
|
||||
SELECT a, b FROM sample635;
|
||||
```
|
||||
|
||||
|a|b|
|
||||
|-|-|
|
||||
|1|1|
|
||||
|1|2|
|
||||
|1|3|
|
||||
|2|1|
|
||||
|2|2|
|
||||
|
||||
---
|
||||
87
도서/SQL첫걸음/Lecture28.md
Normal file
@@ -0,0 +1,87 @@
|
||||
# 28강. 인덱스 구조
|
||||
`체인`이라고도 불리는 인덱스는 데이터베이스 객체 중 하나이다. 이 절에서는 인덱스란 무엇이며 그 역할과 구조는 어떻게 이루어지는지 알아본다.
|
||||
|
||||
- 테이블에는 인덱스를 작성할 수 있다.
|
||||
|
||||
---
|
||||
|
||||
## 1. 인덱스
|
||||
- 인덱스는 테이블에 붙여진 `색인`이라 할 수 있다.
|
||||
- 인덱스의 역할은 `검색속도의 향상`이다.
|
||||
- 여기서 `검색`이란 `SELECT` 명령에 `WHERE` 구로 조건을 지정하고 그에 일치하는 행을 찾는 일련의 과정을 말한다.
|
||||
- 검색은 탐색이라고도 불린다.
|
||||
- 테이블에 인덱스가 지정되어 있으면 효율적으로 검색할 수 있으므로 `WHERE`로 조건이 지정된 `SELECT` 명령의 처리 속도가 향상된다.
|
||||
- 책 안에 있는 특정한 부분을 찾고 싶은 경우, 본문을 처음부터 읽어나가기보다 목차나 색인을 참고해서 찾는 편이 효율적이다.
|
||||
- 인덱스가 바로 이런 역할을 한다.
|
||||
- 인덱스의 구조도 목차나 색인과 비슷하다. 목차나 색인에 제목-키워드별 페이지 번호가 적혀있듯, 데이터베이스의 인덱스에는 검색 시에 쓰이는 키워드와 대응하는 데이터 행의 장소가 저장되어 있다.
|
||||
- 인덱스는 테이블과는 별개로 독립된 데이터베이스 객체로 작성된다. 하지만 인덱스만으로는 아무런 의미가 없다.
|
||||
- 목차밖에 없는 책은 본 적이 없는 것처럼, 인덱스는 테이블에 의존하는 객체라 할 수 있다.
|
||||
- 대부분의 데이터베이스에서는 테이블을 삭제하면 인덱스도 같이 삭제된다.
|
||||
|
||||
---
|
||||
|
||||
## 2. 검색에 사용하는 알고리즘
|
||||
- 대량의 데이터를 효율적으로 검색하는 방법에 관해서는 예전부터 여러 가지로 연구되어 왔다.
|
||||
- 데이터 탐색이라든가 검색 알고리즘 등이 그에 해당한다.
|
||||
- 데이터베이스의 인덱스에 쓰이는 대표적인 검색 알고리즘으로는 `이진 트리(binary tree)`가 있으며, 그 다음으로 `해시`가 유명하다.
|
||||
- 여기서는 이진 트리의 구조를 간단히 설명한다.
|
||||
- 이진 트리는 정확히 말하면 탐색 방법이라기보다 데이터 구조에 가깝다.
|
||||
- 탐색 방법으로 말하자면 `이진탐색(binary search)`이 된다. 이때 이진탐색에서 검색하기 쉬운 구조로 한 것이 이진 트리이다.
|
||||
|
||||
### 풀 테이블 스캔(full table scan)
|
||||
- 인덱스가 지정되지 않은 테이블을 검색할 때는 풀 테이블 스캔이라 불리는 검색 방법을 사용한다.
|
||||
- 처리방법은 단순한데, 테이블에 저장된 모든 값을 처음부터 차례로 조사해나가는 것이다.
|
||||
- 아주 단순한 검색방법으로, 행이 1,000건 있다면 최대 1,000번 값을 비교한다.
|
||||
|
||||
### 이진 탐색(binary search)
|
||||
- 이진 탐색은 차례로 나열된 집합에 대해 유효한 검색 방법이다.
|
||||
- 처음부터 순서대로 조사하는 것이 아니고 집합을 반으로 나누어 조사하는 검색방법이다.
|
||||
- 차례로 나열된 수치의 집합에서 '30'을 검색한다고 가정하자.
|
||||
- 열 이름을 no라고 하고 `WHERE no = 30`과 같은 조건을 지정한 상태라고 하자.
|
||||
- `1, 2, 3, 5, 10, 11, 19, 20, 23, 30, 31, 32, 38, 40, 100`
|
||||
- 이 집합에 15개의 수치 데이터가 있다고 가정하고 여기서 30의 위치를 찾으려 할 때, 이진 탐색에서는 집합의 가운데에서부터 조사하기 시작한다. 현재 가운데 값은 20이다.
|
||||
- 지금 검색하려고 하는 30이라는 값은 20보다 크다. 수치는 정렬되어 있으므로 가운데를 기준으로 오른쪽에 있을 것이다. 그 오른쪽 부분에서 다시 가운데를 기준으로 잡아 조사한다.
|
||||
- 오른쪽의 가운데 값은 32이다. 30 < 32 이므로 이번에는 왼쪽에 원하는 수치가 있을 것이다.
|
||||
- 마침내 30을 찾게 되는데, 이번 경우에는 총 세 번 비교해 목표를 찾을 수 있었다.
|
||||
- 만약 풀 테이블 스캔으로 했다면 열 번 비교해야 했겠지만, 이진 탐색이라면 3회로 끝나기 때문에 더 효율적이다.
|
||||
- 지금 사례는 데이터수가 15개에 불과해 풀 테이블 스캔이나 이진 탐색이나 크게 차이가 없을 수 있다.
|
||||
- 하지만 실제 데이터베이스에는 수만, 수천만 건의 행이 있다.
|
||||
- 풀 테이블 스캔을 한다면 데이터 수에 비례해 비교횟수도 늘어난다.
|
||||
- 그에 비해 이진 탐색은 데이터 수가 배가 되어도 비교 횟수는 1회밖에 늘어나지 않는다. 이런 점에서 이진 탐색이 우위에 있는 것이다.
|
||||
|
||||
##### 대량의 데이터를 검색할 때는 이진 탐색이 빠르다!
|
||||
|
||||
### 이진 트리(binary tree)
|
||||
- 이진 탐색은 고속으로 검색할 수 있는 탐색 방법이지만 데이터가 미리 정렬되어 있어야 한다.
|
||||
- 하지만 테이블 내의 행을 언제나 정렬된 상태로 두는 것은 힘든 작업이다.
|
||||
- 일반적으로는 테이블에 인덱스를 작성하면 테이블 데이터와 별개로 인덱스용 데이터가 저장장치에 만들어진다. 이때 이진 트리라는 데이터 구조로 작성된다.
|
||||
- 이진 트리의 구조는 다음과 같다(이진 탐색의 예로 사용했던 집합을 그대로 이진 트리로 해보았다).
|
||||
|
||||
|
||||
|
||||
- 트리는 `노드(node)`라는 요소로 구성되며 각 노드는 두 개의 가지로 나뉜다.
|
||||
- 노드의 왼쪽 가지는 작은 값으로, 오른쪽 가지는 큰 값으로 나뉘어져 있다.
|
||||
- 두 개의 가지로 분기하는 구조라서 `이진 트리`라 불리는 것이다.
|
||||
- 검색은 이진 트리의 가지를 더듬어 가면서 행해진다.
|
||||
- 10이라는 값을 검색한다고 가정해보자.
|
||||
- 이진 탐색에서는 가운데 값부터 검색하기 시작했지만 이진 트리의 경우에는 트리의 루트 노드부터 시작한다.
|
||||
- 루트 노드는 트리의 맨 위에 있다. 20이라는 값으로 된 루트 노드부터 검색을 시작한다.
|
||||
- 검색의 진행 방법은 이진 탐색과 거의 비슷하다. 원하는 수치와 비교해서 더 크면 오른쪽 가지를, 작으면 왼쪽의 가지를 조사해 나간다.
|
||||
- 이진 탐색의 경우는 오른쪽의 가운데, 왼쪽의 가운데 값을 계산해야 하지만, 이진 트리에서는 구조 자체가 검색하기 쉬우므로 가지를 따라 이동하기만 하면 된다.
|
||||
- 20 > 10 이기 때문에 우선은 왼쪽 가지로 이동한다.
|
||||
- 다음은 5이다. 5 < 10 이므로 이번에는 오른쪽 가지로 이동한다.
|
||||
- 11 > 10 이므로 이번에는 왼쪽으로 간다.
|
||||
- 마침내 10을 찾았다.
|
||||
|
||||
---
|
||||
|
||||
## 3. 유일성
|
||||
- 이진 트리의 구조를 살피다 보면, 같은 값을 가지는 노드가 여러 개 있을 때의 결과에 대한 의문이 생길 수 있다.
|
||||
- 사실 이진 트리에서는 집합 내에 중복하는 값을 가질 수 없다.
|
||||
- 즉, 노드의 가지는 큰 쪽과 작은 쪽의 두 가지로 나뉘며, 같은 값을 허용하기 위해서는 '같은'이라는 제 3의 가지를 가질 필요가 있다.
|
||||
- 하지만, 이진 트리에서 '같은 값을 가지는 노드를 여러 개 만들 수 없다'라는 특성은 키에 대하여 유일성을 가지게 할 경우에만 유용하다.
|
||||
- 그래서 기본키 제약은 이진 트리로 인덱스를 작성하는 데이터베이스가 많은 것 같다.
|
||||
|
||||
##### 이진 트리에는 중복하는 값을 등록할 수 없다!
|
||||
|
||||
---
|
||||
132
도서/SQL첫걸음/Lecture29.md
Normal file
@@ -0,0 +1,132 @@
|
||||
# 29강. 인덱스 작성과 삭제
|
||||
여기서는 실제로 테이블에 인덱스를 작성하는 방법에 대해서 알아본다.
|
||||
|
||||
**`인덱스 작성, 삭제`**
|
||||
```
|
||||
CREATE INDEX
|
||||
DROP INDEX
|
||||
```
|
||||
|
||||
- 인덱스는 데이터베이스 객체의 하나로 `DDL`을 사용해서 작성하거나 삭제한다.
|
||||
- 표준 SQL에는 `CREATE INDEX` 명령은 없다. 인덱스 자체가 데이터베이스 제품에 의존하는 선택적인 항목으로 취급된다.
|
||||
- 하지만 대표적인 데이터베이스 제품에는 모두 인덱스 구조가 도입되어 있으며, 모두 비슷한 관리 방법으로 인덱스를 다룰 수 있다.
|
||||
|
||||
---
|
||||
|
||||
## 1. 인덱스 작성
|
||||
- 인덱스는 `CREATE INDEX` 명령으로 만든다.
|
||||
- 인덱스에 이름을 붙여 관리하는데, 데이터베이스 객체가 될지 테이블의 열처럼 취급될지는 데이터베이스 제품에 따라 다르다.
|
||||
- `Oracle`이나 `DB2` 등에서 인덱스는 스키마 객체가 된다. 따라서 스키마 내에 이름이 중복하지 않도록 지정해 관리한다.
|
||||
- 한편 `SQL Server`나 `MySQL`에서 인덱스는 테이블 내의 객체가 된다.
|
||||
- 따라서 테이블 내에 이름이 중복되지 않도록 지정해 관리한다.
|
||||
- 인덱스를 작성할 때는 해당 인덱스가 어느 테이블의 어느 열에 관한 것인지 지정할 필요가 있다.
|
||||
- 이때 열은 복수로도 지정할 수 있다. 인덱스의 네임스페이스가 데이터베이스 제품마다 다르다는 점만 주의하면 문법은 그렇게 어렵지 않다.
|
||||
|
||||
**`CREATE INDEX`**
|
||||
```
|
||||
CREATE INDEX 인덱스명 ON 테이블명 (열명1, 열명2, ...)
|
||||
```
|
||||
|
||||
- 다음 예제에서는 sample62 테이블의 no 열에 isample65라는 인덱스를 지정한다.
|
||||
- 인덱스를 작성할 때는 저장장치에 색인용 데이터가 만들어진다.
|
||||
- 테이블 크기에 따라 인덱스 작성시간도 달라지는데, 행이 대량으로 존재하면 시간도 많이 걸리고 저장공간도 많이 소비한다.
|
||||
|
||||
**`인덱스 작성하기`**
|
||||
```
|
||||
CREATE INDEX isample65 ON sample62(no);
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 2. 인덱스 삭제
|
||||
- 인덱스는 `DROP INDEX` 명령으로 삭제한다.
|
||||
- `DROP` 할 때는 다른 객체와 동일하게 인덱스 이름만 지정하면 된다.
|
||||
- 다만 테이블 내 객체로서 작성하는 경우에는 테이블 이름도 지정한다(이때 인덱스를 구성하는 열은 지정할 필요가 없다).
|
||||
|
||||
**`DROP INDEX(스키마 객체의 경우)`**
|
||||
```
|
||||
DROP INDEX 인덱스명
|
||||
```
|
||||
|
||||
**`DROP INDEX(테이블 내 객체의 경우)`**
|
||||
```
|
||||
DROP INDEX 인덱스명 ON 테이블명
|
||||
```
|
||||
|
||||
- 인덱스는 테이블에 의존하는 객체이다.
|
||||
- `DROP TABLE`로 테이블을 삭제하면 테이블에 작성된 인덱스도 자동으로 삭제된다.
|
||||
- 인덱스만 삭제하는 경우에는 `DROP INDEX`를 사용한다.
|
||||
|
||||
**`인덱스 삭제하기`**
|
||||
```
|
||||
DROP INDEX isample65 ON sample62;
|
||||
```
|
||||
|
||||
- 인덱스를 작성해두면 검색이 빨라진다.
|
||||
- 작성한 인덱스의 열을 `WHERE` 구로 조건을 지정하여 `SELECT` 명령으로 검색하면 처리속도가 향상된다.
|
||||
- 하지만 모든 `SELECT` 명령에 적용되는 만능 인덱스는 작성할 수 없다.
|
||||
- 한편, `INSERT` 명령의 경우에는 인덱스를 최신 상태로 갱신하는 처리가 늘어나므로 처리속도가 조금 떨어진다.
|
||||
- `SELECT` 명령에서의 인덱스 사용에 관해 조금 더 설명한다. 먼저 다음과 같은 명령으로 인덱스를 작성했다고 가정하자.
|
||||
|
||||
`CREATE INDEX isample65 ON sample62(a);`
|
||||
|
||||
- `WHERE` 구에 a 열에 대한 조건식을 지정한 경우 `SELECT` 명령은 인덱스를 사용해 빠르게 검색할 수 있다.
|
||||
- 예를 들면 다음과 같은 `SELECT` 명령이 된다. 그러나 `WHERE` 구의 조건식에 a 열이 전혀 사용되지 않으면 `SELECT` 명령은 isample62라는 인덱스를 사용할 수 없다.
|
||||
|
||||
`SELECT * FROM sample62 WHERE a = 'a';`
|
||||
|
||||
---
|
||||
|
||||
## 3. EXPLAIN
|
||||
- 인덱스 작성을 통해 쿼리의 성능 향상을 기대할 수 있다.
|
||||
- 이때 실제로 인덱스를 사용해 검색하는지를 확인하려면 `EXPLAIN` 명령을 사용한다.
|
||||
|
||||
**`EXPLAIN`**
|
||||
```
|
||||
EXPLAIN SQL명령
|
||||
```
|
||||
|
||||
- `EXPLAIN` 명령의 문법은 간단하다. `EXPLAIN`에 뒤이어 확인하고 싶은 `SELECT` 명령 등의 SQL 명령을 지정하면 된다. 다만 이 SQL 명령은 실제로는 실행되지 않는다.
|
||||
- 어떤 상태로 실행되는지를 데이터베이스가 설명해줄 뿐이다.
|
||||
- `MySQL`의 경우 상황에 따라 다르지만 필요한 정보를 얻기 위해 SQL 명령의 일부분을 실제로 실행하는 경우도 있다.
|
||||
- `EXPLAIN`은 표준 SQL에는 존재하지 않는, 데이터베이스 제품 의존형 명령이다. 하지만 어떤 데이터베이스 제품이라도 이와 비슷한 명령을 지원한다.
|
||||
|
||||
**`EXPALIN으로 인덱스 사용 확인하기 1 (MySQL)`**
|
||||
```
|
||||
EXPLAIN SELECT * FROM sample62 WHERE a = 'a';
|
||||
```
|
||||
|
||||
|
||||
- sample62의 a 열에는 isample65이라는 인덱스가 작성되어 있다.
|
||||
- `EXPLAIN`의 뒤를 잇는 `SELECT` 명령은 a 열의 값을 참조해 검색하므로 isample65을 사용해 검색한다(`possible_keys` 라는 곳에 사용될 수 있는 인덱스가 표시되며, `key`는 사용된 인덱스가 표시된다).
|
||||
|
||||
이때 `WHERE` 조건을 바꾸면 어떻게 변하는지 알아본다. a 열을 사용하지 않도록 조건을 변경하면 인덱스를 사용할 수 없을 것이다.
|
||||
|
||||
**`EXPLAIN으로 인덱스 사용 확인하기 2 (MySQL)`**
|
||||
```
|
||||
EXPLAIN SELECT * FROM sample62 WHERE no > 10;
|
||||
```
|
||||
|
||||
|
||||
- `possible_keys`와 `key`가 `NULL`이 된다.
|
||||
|
||||
---
|
||||
|
||||
## 4. 최적화
|
||||
- `SELECT` 명령을 실행할 때 인덱스의 사용 여부를 선택한다는 것을 알았다.
|
||||
- 이는 데이터베이스 내부의 최적화에 의해 처리되는 부분이다.
|
||||
- 내부 처리에서는 `SELECT` 명령을 실행하기에 앞서 `실행계획`을 세운다.
|
||||
- 실행계획에는 '인덱스가 지정된 열이 `WHERE` 조건으로 지정되어 있으니 인덱스를 사용하자'와 같은 처리가 이루어진다.
|
||||
- `EXPLAIN` 명령은 이 실행계획을 확인하는 명령이다.
|
||||
- 실행계획에서는 인덱스의 유무뿐만 아니라 인덱스를 사용할 것인지 여부에 대해서도 데이터베이스 내부의 최적화 처리를 통해 판단한다.
|
||||
- 이때 판단 기준으로 인덱스의 품질도 고려한다.
|
||||
- 예를 들어 '예' 또는 '아니오'라는 값만 가지는 열이 있다면, 해당 열에 인덱스를 지정해도 다음과 같은 이진트리가 되어 좋은 구조를 가지지 못한다.
|
||||
|
||||
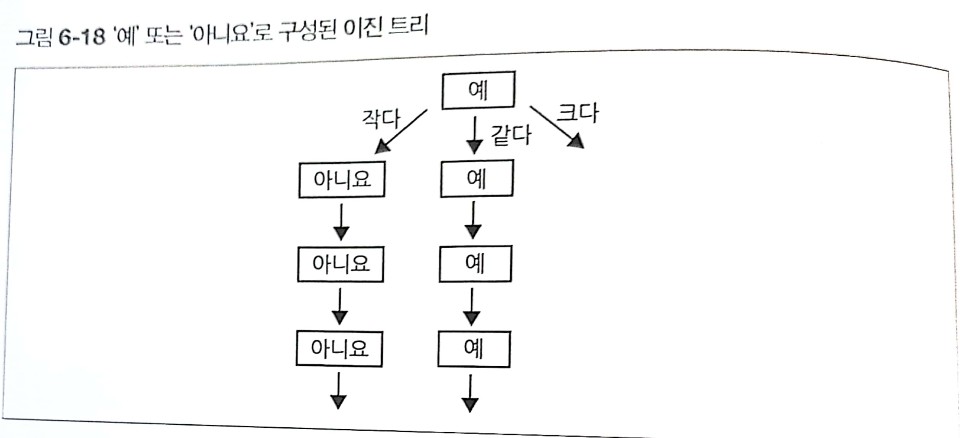
|
||||
|
||||
- 이는 단순한 리스트와 별다른 차이가 없는 구조로, 이진탐색에 의한 효율화를 기대할 수 없다.
|
||||
- 물론 '예' 또는 '아니오'는 극단적인 사례이지만 데이터의 종류가 적으면 적을수록 인덱스의 효율도 떨어진다.
|
||||
- 반대로 서로 다른 값으로 여러 종류의 데이터가 존재하면 그만큼 효율은 좋아진다.
|
||||
- 이렇게 인덱스의 품질을 고려해 실행계획이 세워지는 것이다.
|
||||
|
||||
---
|
||||
139
도서/SQL첫걸음/Lecture30.md
Normal file
@@ -0,0 +1,139 @@
|
||||
# 30강. 뷰 작성과 삭제
|
||||
뷰는 테이블과 같은 부류의 데이터베이스 객체 중 하나이다. 여기에서는 뷰를 정의하고, 작성 및 삭제하는 방법에 대해서 알아본다.
|
||||
|
||||
**`뷰의 작성 및 삭제`**
|
||||
```
|
||||
CREATE VIEW 뷰명 AS SELECT명령
|
||||
DROP VIEW 뷰명
|
||||
```
|
||||
|
||||
- 앞장에서 서브쿼리에 대해서 배웠는데, 서브쿼리는 `FROM` 구에서도 기술할 수 있었다.
|
||||
- 여기서 `FROM` 구에 기술된 서브쿼리에 이름을 붙이고 데이터베이스 객체화하여 쓰기 쉽게 한 것을 뷰라고 한다.
|
||||
|
||||
---
|
||||
|
||||
## 1. 뷰
|
||||
- 데이터베이스 객체란 테이블이나 인덱스 등 데이터베이스 안에 정의하는 모든 것을 말한다.
|
||||
- 뷰 역시 데이터베이스 객체 중 하나이다. 반면 `SELECT` 명령은 객체가 아니다.
|
||||
- `SELECT` 명령에 이름을 지정할 수도 없고 데이터베이스에 등록되지도 않기 때문이다.
|
||||
- 이처럼 본래 데이터베이스 객체로 등록할 수 없는 `SELECT` 명령을, 객체로서 이름을 붙여 관리할 수 있도록 한 것이 뷰이다.
|
||||
- `SELECT` 명령은 실행했을 때 테이블에 저장된 데이터를 결괏값으로 반환한다.
|
||||
- 따라서 뷰를 참조하면 그에 정의된 `SELECT` 명령의 실행결과를 테이블처럼 사용할 수 있다.
|
||||
|
||||
##### 뷰는 SELECT 명령을 기록하는 데이터베이스 객체다!
|
||||
|
||||
- `FROM` 구에는 서브쿼리를 사용할 수 있었다. 예를 들면 다음과 같은 `SELECT` 명령이다.
|
||||
|
||||
`SELECT * FROM (SELECT * FROM sample54) sq;`
|
||||
|
||||
- 앞의 예에서 서브쿼리 부분을 `뷰 객체`로 만들면 다음과 같은 `SELECT` 명령이 된다.
|
||||
|
||||
`SELECT * FROM sample_view_67;`
|
||||
|
||||
- sample_view_67은 뷰의 이름이다. 뷰를 정의할 때는 이름과 `SELECT` 명령을 지정한다.
|
||||
- 뷰를 만든 후에는 `SELECT` 명령에서 뷰의 이름을 지정하면 참조할 수 있다.
|
||||
- 앞선 예제에서는 서브쿼리 부분이 단순한 `SELECT` 명령으로 되어 있지만, 실제 업무에서는 `WHERE` 구로 조건을 지정하거나 `GROUP BY` 구로 집계하는 등 좀 더 복잡한 명령으로 이루어지는 경우가 많다.
|
||||
- 이런 경우 서브쿼리 부분을 뷰로 대체하여 `SELECT` 명령을 간략하게 표현할 수 있다.
|
||||
- 또한 뷰를 사용함으로써 복잡한 `SELECT` 명령을 데이터베이스에 등록해 두었다가 나중에 간단히 실행할 수도 있다.
|
||||
- 즉, 자주 사용하거나 복잡한 `SELECT` 명령을 뷰로 만들어 편리하게 사용할 수 있는 것이다.
|
||||
|
||||
##### 뷰를 작성하는 것으로 복잡한 SELECT 명령을 간략하게 표현할 수 있다!
|
||||
|
||||
### 가상 테이블
|
||||
- 뷰는 테이블처럼 취급할 수 있지만 '실체가 존재하지 않는다'라는 의미로 `가상 테이블`이라 불리기도 한다.
|
||||
- `SELECT` 명령으로 이루어지는 뷰는 테이블처럼 데이터를 쓰거나 지울 수 있는 저장공간을 가지지 않는다.
|
||||
- 이 때문에 테이블처럼 취급할 수 있다고는 해도 `SELECT 명령에서만 사용`하는 것을 권장한다.
|
||||
- `INSERT`나 `UPDATE`, `DELETE` 명령에서도 조건이 맞으면 가능하지만 사용에 주의할 필요가 있다.
|
||||
|
||||
---
|
||||
|
||||
## 2. 뷰 작성과 삭제
|
||||
- 뷰는 데이터베이스 객체이기 때문에 `DDL`로 작성하거나 삭제한다.
|
||||
- 작성할 때는 `CREATE VIEW`를, 삭제할 때는 `DROP VIEW`를 사용한다.
|
||||
|
||||
### 뷰의 작성
|
||||
|
||||
**`CREATE VIEW`**
|
||||
```
|
||||
CREATE VIEW 뷰명 AS SELECT 명령
|
||||
```
|
||||
|
||||
- `CREATE VIEW` 다음에 뷰의 이름을 지정하고, `AS`로 `SELECT` 명령을 지정한다.
|
||||
- `CREATE VIEW`의 `AS` 키워드는 별명을 붙일 때 사용하는 `AS`와는 달리 생략할 수 없다.
|
||||
|
||||
**`뷰 작성하기`**
|
||||
```
|
||||
CREATE VIEW sample_view_67 AS SELECT * FROM sample54;
|
||||
|
||||
SELECT * FROM sample_view_67;
|
||||
```
|
||||
|
||||
- `CREATE VIEW`로 뷰를 작성한 뒤 `SELECT` 명령의 `FROM` 구에 지정해 사용할 수 있다.
|
||||
- 뷰는 필요에 따라 열을 지정할 수도 있는데, 이 경우에는 이름 뒤에 괄호로 묶어 열을 나열한다.
|
||||
|
||||
**`CREATE VIEW에서 열 지정하기`**
|
||||
```
|
||||
CREATE VIEW 뷰명 (열명1, 열명2, ...) AS SELECT 명령
|
||||
```
|
||||
|
||||
- 뷰의 열 지정을 생략한 경우에는 `SELECT` 명령의 `SELECT` 구에서 지정하는 열 정보가 수집되어 자동적으로 뷰의 열로 지정된다.
|
||||
- 반대로 열을 지정한 경우에는 `SELECT` 명령의 `SELECT` 구에 지정한 열보다 우선된다.
|
||||
- 다만 `SELECT` 명령의 `SELECT` 구와 같은 수의 열을 일일이 지정해야 하므로 `SELECT` 명령의 모든 열을 사용할 경우에는 열을 지정하지 않는 편이 낫다.
|
||||
- 또한 열 이외에는 정의할 수 없으며, 테이블의 열을 정의할 때처럼 자료형이나 제약도 지정할 수 없다.
|
||||
|
||||
**`열을 지정해서 뷰 작성하기`**
|
||||
```
|
||||
CREATE VIEW sample_view_672(n, v, v2) AS SELECT no, a, a*2 FROM sample54;
|
||||
|
||||
SELECT * FROM sample_view_672 WHERE n = 1;
|
||||
```
|
||||
|
||||
### 뷰 삭제
|
||||
- 뷰를 삭제할 경우에는 `DROP VIEW`를 사용한다.
|
||||
- 일단 뷰를 삭제하면 더 이상 뷰를 참조하여 사용할 수 없다.
|
||||
|
||||
**`DROP VIEW`**
|
||||
```
|
||||
DROP VIEW 뷰명
|
||||
```
|
||||
|
||||
**`뷰 삭제하기`**
|
||||
```
|
||||
DROP VIEW sample_view_672;
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 3. 뷰의 약점
|
||||
- 뷰는 데이터베이스 객체로서 저장장치에 저장된다.
|
||||
- 하지만 테이블과 달리 대량의 저장공간을 필요로 하지 않는다.
|
||||
- 데이터베이스에 저장되는 것은 `SELECT` 명령뿐이기 때문이다.
|
||||
- 다만 저장공간을 소비하지 않는 대신 CPU 자원을 사용한다.
|
||||
- `SELECT` 명령은 데이터베이스의 테이블에서 행을 검색해 클라이언트로 반환하는 명령이다.
|
||||
- 검색뿐만 아니라 `ORDER BY`로 정렬하거나 `GROUP BY`로 집계할 수 있다.
|
||||
- 이러한 처리는 계산능력을 필요로 하기 때문에 컴퓨터의 CPU를 사용한다.
|
||||
- 뷰를 참조하면 뷰에 등록되어 있는 `SELECT` 명령이 실행된다.
|
||||
- 실행 결과는 일시적으로 보존되며, 뷰를 참조할 때마다 `SELECT` 명령이 실행된다.
|
||||
|
||||
### 머티리얼라이즈드 뷰(Materialized View)
|
||||
- 뷰에도 약점은 있다. 뷰의 근원이 되는 테이블에 보관하는 데이터양이 많은 경우, 집계처리를 할 때도 뷰가 사용된다면 처리속도가 많이 떨어질 수밖에 없다.
|
||||
- 뷰를 중첩해서 사용하는 경우에도 처리 속도가 떨어지기 쉽다.
|
||||
- 이 같은 상황을 회피하기 위해 사용할 수 잇는 것이 `머티리얼라이즈드 뷰`이다.
|
||||
- 일반적으로 뷰는 데이터를 일시적으로 저장했다가 쿼리가 실행 종료될 때 함께 삭제된다. 그에 비해 머티리얼라이즈드 뷰는 데이터를 일시적으로 저장해 사용하는 것이 아니라 테이블처럼 저장장치에 저장해두고 사용한다.
|
||||
- 머티리얼라이즈드 뷰는 처음 참조되었을 때 데이터를 저장해둔다.
|
||||
- 이후 다시 참조할 때 이전에 저장해 두었던 데이터를 그대로 사용한다.
|
||||
- 일반적인 뷰처럼 매번 `SELECT` 명령을 실행할 필요가 없다.
|
||||
- 다만 뷰에 지정된 테이블의 데이터가 변경된 경우에는 `SELECT` 명령을 재실행하여 데이터를 다시 저장한다.
|
||||
- 이처럼 변경 유무를 확인하여 재실행하는 것은 `RDBMS`가 자동으로 실행한다.
|
||||
- 뷰에 지정된 테이블의 데이터가 자주 변경되지 않는 경우라면 머티리얼라이즈드 뷰를 사용하여 뷰의 약점을 어느 정도 보완할 수 있다.
|
||||
- 다만, 한 가지 아쉬운 점이 있다면 `MySQL`에서는 머티리얼라이즈드 뷰를 사용할 수 없다.
|
||||
- 지금으로서는 `Oracle`과 `DB2`에서만 사용할 수 있는 데이터베이스 객체이다.
|
||||
|
||||
### 함수 테이블
|
||||
- 뷰는 또 하나의 약점을 갖는다. 뷰를 구성하는 `SELECT` 명령은 단독으로도 실행할 수 있어야 한다.
|
||||
- 상관 서브쿼리에서 언급한 것처럼, 부모 쿼리와 어떤 식으로든 연관된 서브쿼리의 경우에는 뷰의 `SELECT` 명령으로 사용할 수 없다.
|
||||
- 대신 이 같은 뷰의 약점을 `함수 테이블`을 사용하여 회피할 수 있다.
|
||||
- `함수 테이블`은 테이블을 결괏값으로 반환해주는 사용자정의 함수이다.
|
||||
- 함수에는 인수를 지정할 수 있기 때문에 인수의 값에 따라 `WHERE` 조건을 붙여 결괏값을 바꿀 수 있다. 그에 따라 상관 서브쿼리처럼 동작할 수 있다.
|
||||
|
||||
---
|
||||
160
도서/SQL첫걸음/Lecture31.md
Normal file
@@ -0,0 +1,160 @@
|
||||
# 31강. 집합 연산
|
||||
지금부터는 `복수의 테이블`을 사용해 데이터를 검색하는 방법에 관해 알아본다.
|
||||
|
||||
- `RDBMS`의 창시자인 에드거 커드는 `관계형 모델`을 고안한 인물이기도 하다.
|
||||
- 관계형 모델을 채택한 데이터베이스를 관계형 데이터베이스라 부른다.
|
||||
- 관계형 모델에서의 관계형은 수학 집합론의 관계형 이론에서 유래했다.
|
||||
- 집합론이라고 거창하게 말하지만 실질적으로는 데이터베이스의 데이터를 집합으로 간주해 다루기 쉽게 하자는 것에 지나지 않는다.
|
||||
|
||||
---
|
||||
|
||||
## 1. SQL과 집합
|
||||
집합이라 하면 `AND`와 `OR`를 설명할 때 등장했던 `벤 다이어그램`을 떠올리면 쉽다.
|
||||
- 벤 다이어그램에서는 하나의 원이 곧 하나의 집합이다.
|
||||
- 원 안에는 몇 가지 요소가 포함되는데, 원 안에 적혀있는 숫자가 요소에 해당한다.
|
||||
- 한편 데이터베이스에서는 테이블의 행이 요소에 해당한다.
|
||||
- 행은 여러 개의 열로 구성되는 경우도 있으므로, 수치 상으로는 복수의 값이 존재한다.
|
||||
- 하지만 집합의 요소라는 측면에서 보면 하나의 행이 곧 하나의 요소가 된다.
|
||||
- `SELECT` 명령을 실행하면 데이터베이스에 질의하며 그 결과 몇 개의 행이 반환된다.
|
||||
- 이때 반환된 결과 전체를 하나의 집합이라고 생각하면 된다.
|
||||
|
||||
---
|
||||
|
||||
## 2. UNION으로 합집합 구하기
|
||||
- 집합의 연산에는 `합집합`이라는 것이 있다. 이는 집합을 서로 더한 것을 말한다.
|
||||
- 우선 간단한 숫자를 모아놓은 집합을 이용해 설명한다.
|
||||
- A와 B라는 두 개의 집합이 존재한다고 했을 때, A 집합에는 [1, 2, 3]이라는 세 개의 요소가, B 집합에는 [2, 10, 11]이라는 세 개의 요소가 있다.
|
||||
- 그중 2라는 요소는 A에도 B에도 모두 존재한다.
|
||||
- 집합 A와 B의 합집합을 구하면 그 결과는 [1, 2, 3, 10, 11]이 된다.
|
||||
- 벤 다이어 그램으로 설명하면 두 개의 집합을 모두 합한 부분이 합집합의 결과이다.
|
||||
- 이때 두 개 집합에서 겹쳐지는 부분, 즉 '요소 2'가 계산 결과로는 한 개밖에 나타나지 않는다는 점이 핵심이다.
|
||||
- 즉, 단순하게 서로 더하면 [1, 2, 3, 2, 10, 11]과 같이 6개의 요소가 되지만 합집합에서는 그렇지 않다.
|
||||
|
||||
### UNION
|
||||
- SQL에서는 `SELECT` 명령의 실행 결과를 하나의 집합으로 다룰 수 있다.
|
||||
- 합집합을 계산할 경우에는 수학에서 사용하던 U기호 대신 `UNION` 키워드를 사용한다.
|
||||
- U는 `U`와 모양이 비슷해 기억하기 쉽다. 즉, 수학에서의 `A U B`는 SQL에서는 `A UNION B`라고 표현한다.
|
||||
- A나 B로 표현했지만 실제로는 `SELECT` 명령이다.
|
||||
- `SELECT` 명령의 결과를 집합으로 간주하고, `UNION`으로 합집합을 구할 수 있다.
|
||||
|
||||
**`두 개의 SELECT 명령을 UNION해서 합집합 구하기`**
|
||||
```
|
||||
SELECT * FROM smaple71_a
|
||||
UNION
|
||||
SELECT * FROM sample71_b;
|
||||
```
|
||||
|
||||
- 이때 두 개의 `SELECT` 명령을 하나의 명령으로 합치는 만큼, `세미콜론(;)`은 맨 나중에 붙인다는 점에 주의해야 한다.
|
||||
- 만약 sample71_a 뒤에 세미콜론을 붙이면 도중에 명령이 끝나버리므로 제대로 실행되지 않는다.
|
||||
- 정리하면, 한 번의 쿼리 실행으로 두 개의 `SELECT` 명령이 내부적으로 실행되는 형식이다.
|
||||
- 이때 각 `SELECT` 명령의 실행결과(집합)를 합집합(UNION)으로 계산하여 최종적으로 결과를 반환한다.
|
||||
|
||||
##### UNION으로 두 개의 SELECT 명령을 하나로 연계해 질의 결과를 얻을 수 있다!
|
||||
|
||||
- `UNION`을 이용하면 여러 개의 `SELECT` 명령을 하나로 묶을 수 있다.
|
||||
- 1+2+3...처럼 연속해서 더하는 것과 같은 형식이다.
|
||||
- 이때 각각의 `SELECT` 명령의 열의 내용은 서로 일치해야 한다.
|
||||
- 예를 들어 sample71_a와 sample71_b의 경우, 열 이름은 서로 다르지만 열 개수와 자료형이 서로 같기 때문에 일치한다고 말할 수 있다.
|
||||
- 반면 다음과 같이 완전히 열 구성이 다른 테이블을 `UNION`으로 묶을 수는 없다.
|
||||
|
||||
```
|
||||
SELECT * FROM sample71_a
|
||||
UNION
|
||||
SELECT * FROM sample71_b
|
||||
UNION
|
||||
SELECT * FROM sample31;
|
||||
```
|
||||
|
||||
- 다만 전체 데이터를 반환하는 `애스터리스크(*)`를 쓰지 않고, 열을 따로 지정하여 각 `SELECT` 명령에서 집합의 요소가 될 데이터를 서로 맞춰주면 `UNION`으로 실행할 수 있는 쿼리가 된다. 예를 들면 다음과 같다.
|
||||
|
||||
```
|
||||
SELECT a FROM sample71_a
|
||||
UNION
|
||||
SELECT b FROM sample71_b
|
||||
UNION
|
||||
SELECT age FROM sample31;
|
||||
```
|
||||
|
||||
- `SELECT` 명령들을 `UNION`으로 묶을 때 나열 순서는 합집합의 결과에 영향을 주지 않는다.
|
||||
- 따라서 아래의 명령들은 결과가 모두 같다.
|
||||
- 단, 결괏값의 나열 순서는 달라질 수도 있다.
|
||||
- `ORDER BY`를 지정하지 않은 `SELECT` 명령은 결과가 내부처리의 상황에 따라 바뀌기 때문이다.
|
||||
|
||||
```
|
||||
SELECT * FROM sample71_a UNION SELECT * FROM sample71_b;
|
||||
SELECT * FROM sample71_b UNION SELECT * FROM sample71_a;
|
||||
```
|
||||
|
||||
- `UNION`을 사용할 때에는 `ORDER BY`를 지정하는 방법에 주의해야 한다.
|
||||
|
||||
### UNION을 사용할 때의 ORDER BY
|
||||
- `UNION`으로 `SELECT` 명령을 결합해 합집합을 구하는 경우, 각 `SELECT` 명령에 `ORDER BY`를 지정해 정렬할 수는 없다.
|
||||
- `ORDER BY`를 지정할 때는 마지막 `SELECT` 명령에만 지정하도록 한다.
|
||||
- 예를 들어 다음과 같은 쿼리를 실행하면 에러가 발생한다.
|
||||
|
||||
**`첫 번째 SELECT 명령에 ORDER BY를 지정할 수 없다`**
|
||||
```
|
||||
SELECT a FROM sample71_a ORDER BY a
|
||||
UNION
|
||||
SELECT b FROM sample71_b;
|
||||
```
|
||||
|
||||
- `ORDER BY`로 정렬할 수 없다는 뜻이 아니다. 합집합의 결과를 정렬하므로, 가장 마지막의 `SELECT` 명령에 `ORDER BY`를 지정해야 한다는 의미이다.
|
||||
|
||||
**`마지막의 SELECT 명령에 ORDER BY를 지정한다`**
|
||||
```
|
||||
SELECT a FROM sample71_a
|
||||
UNION
|
||||
SELECT b FROM sample71_b ORDER BY b;
|
||||
```
|
||||
|
||||
- 하지만 이 쿼리에서도 에러가 발생한다. `ORDER BY`를 지정할 수 있다고 해도 마지막의 `SELECT` 명령의 결과만 정렬하는 것이 아니고 합집합의 결과를 정렬하는 것이기 때문이다.
|
||||
- 이때 두 개의 `SELECT` 명령에서 열 이름이 서로 일치한다면 문제가 없겠지만 앞의 예제에서처럼 반드시 그렇다는 보장이 없다.
|
||||
- 이런 경우 서로 동일하게 별명을 붙여 정렬할 수 있다.
|
||||
|
||||
```
|
||||
SELECT a AS c FROM sample71_a
|
||||
UNION
|
||||
SELECT b AS c FROM sample71_b ORDER BY c;
|
||||
```
|
||||
|
||||
##### UNION으로 SELECT 명령을 연결하는 경우, 가장 마지막 SELECT 명령에 대해서만 ORDER BY 구를 지정할 수 있다!
|
||||
##### ORDER BY 구에 지정하는 열은 별명을 붙여 이름을 일치시킨다!
|
||||
|
||||
### UNION ALL
|
||||
- `UNION`은 합집합을 구하는 것이므로 두 개의 집합에서 겹치는 부분은 공통 요소가 된다.
|
||||
- 예를 들어 앞에서 살펴본 sample71_a와 sample71_b 예제에서는 양쪽 모두 2가 포함되어 있었다. 그리고 이들을 합집합 하면 2는 하나만 존재한다.
|
||||
- 두 명령의 실행 결과에 `DISTINCT`를 걸어 중복을 제거한 것과 같다고 생각하면 이해하기 쉬울 것이다.
|
||||
- 수학에서 말하는 집합은 중복값이 존재하지 않는 것을 전제로 한다.
|
||||
- 그래서 `UNION`을 한 결과에도 중복값이 제거되어 있다.
|
||||
- 하지만 경우에 따라서는 중복을 제거하지 않고 2개의 `SELECT` 명령의 결과를 그냥 합치고 싶은 때도 있을 것이다. 이러한 경우에는 `UNION ALL`을 사용한다.
|
||||
- `SELECT` 명령에서 중복을 제거할 때는 `SELECT` 구에 `DISTINCT`를 지정한다.
|
||||
- 이때 기본값은 `ALL`로, 명시적으로 지정하거나 생략할 수도 있다.
|
||||
- 즉, 중복을 제거하는 경우에는 `DISTINCT`, 중복을 제거하지 않고 모두를 반환하는 경우에는 `ALL`을 추가적으로 지정한다.
|
||||
- 즉, `DISTINCT`나 `ALL`로 중복제거 여부를 지정할 수 있다는 점은 똑같지만, `UNION`의 기본동작은 `ALL`이 아닌 `DISTINCT`라는 점이 다르다.
|
||||
- 또한 `UNION DISTINCT`라는 문법은 허용되지 않으므로 주의해야 한다.
|
||||
|
||||
**`두 개의 SELECT 명령에 UNION ALL을 적용해 합집합 구하기`**
|
||||
```
|
||||
SELECT * FROM sample71_a
|
||||
UNION ALL
|
||||
SELECT * FROM sample71_b;
|
||||
```
|
||||
|
||||
- 위의 명령을 실행하면 2라는 값을 가진 행이 중복되어 표시된다.
|
||||
- `UNION ALL`은 두 개의 집합을 단순하게 합치는 것이다.
|
||||
- `UNION`에서는 이미 존재하는 값인지를 검사하는 처리가 필요한 만큼, `UNION ALL` 쪽이 성능적으로는 유리할 경우가 있다.
|
||||
- 즉, 중복값이 없는 경우에는 `UNION ALL`을 사용하는 편이 좋은 성능을 보여준다.
|
||||
|
||||
---
|
||||
|
||||
## 3. 교집합과 차집합
|
||||
- `MySQL`에서는 지원되지 않는다.
|
||||
- SQL을 이용해 교집합, 차집합도 구할 수 있다. 교집합은 `INTERSECT`를, 차집합은 `EXCEPT`를(`Oracle`의 경우는 `MINUS`) 사용한다.
|
||||
- 교집합이란 두 개의 집합이 겹치는 부분을 말하며, `공통 부분`이라 불리기도 한다.
|
||||
- 차집합은 집합에서 다른 쪽의 집합을 제거하고 남은 부분이다.
|
||||
- 계산 대상이 되는 두 개의 집합에 공통부분이 존재하지 않으면 차집합을 구해도 결과는 바뀌지 않는다.
|
||||
- 또한 완전히 같은 집합끼리 차집합을 계산하면 아무런 요소도 존재하지 않는 공집합이 된다.
|
||||
- 차집합의 결과가 공집합인지 아닌지에 따라 두 개의 집합이 동일한지 아닌지를 알 수 있다.
|
||||
|
||||
---
|
||||
299
도서/SQL첫걸음/Lecture32.md
Normal file
@@ -0,0 +1,299 @@
|
||||
# 32강. 테이블 결합
|
||||
테이블 결합은 `RDBMS`에서 매우 중요한 개념이다. 테이블의 `결합(join)`에 대해 알아본다.
|
||||
|
||||
- 테이블의 집합 연산에서는 세로(행) 방향으로 데이터가 늘어나거나 줄어드는 계산을 했다.
|
||||
- 결합에서는 가로(열) 방향으로 데이터가 늘어나는 계산이 된다.
|
||||
- 보통 데이터베이스는 하나의 테이블에 많은 데이터를 저장하지 않고 몇 개의 테이블로 나누어 저장한다.
|
||||
- 이처럼 여러 개로 나뉜 데이터를 하나로 묶어 결과를 내는 방법이 테이블 결합이다.
|
||||
- 여기서 결합을 이해하는 동시에 기본이 되는 개념이 집합론의 `곱집합`이다.
|
||||
|
||||
---
|
||||
|
||||
## 1. 곱집합과 교차결합
|
||||
- `곱집합`은 합집합이나 교집합처럼 집합의 연산 방법 중 하나이다.
|
||||
- 두 개의 집합을 곱하는 연산 방법으로 `적집합`또는 `카티전곱(Cartesian product)`이라고도 불린다. 특히 곱집합은 야구팀들의 대전표를 짜는 것과 비슷하다고 생각하면 이해하기 쉬울 것이다.
|
||||
- 집합 X는 [A, B, C]라는 요소를 가지고 집합 Y는 [1, 2, 3]이라는 세 개의 요소를 가진다고 하자.
|
||||
- 여기서 집합 X와 Y의 곱집합을 구하면 다음과 같다.
|
||||
- 즉, 집합 X의 요소 A에 집합 Y의 각 요소를 붙여 계산하는 것이다.
|
||||
- 이때 (A, 1)을 하나의 요소라고 생각해보자.
|
||||
|
||||
`곱집합`
|
||||
|A,1|A,2|A,3|
|
||||
|-|-|-
|
||||
|B,1|B,2|B,3|
|
||||
|C,1|C,2|C,3|
|
||||
|
||||
### 교차결합(Cross Join)
|
||||
- 데이터베이스의 테이블은 집합의 한 종류라고 할 수 있다.
|
||||
- 지금까지 `SELECT` 명령에서는 `FROM` 구에 하나의 테이블만 지정했다.
|
||||
- 만약 테이블을 두 개 지정하면 이들은 곱집합으로 계산된다.
|
||||
|
||||
**`교차결합`**
|
||||
```
|
||||
SELECT * FROM 테이블명1, 테이블명2
|
||||
```
|
||||
|
||||
- 각 테이블의 데이터는 앞선 예제의 집합 X, Y의 값을 그대로 사용했다.
|
||||
- 여기서 교차결합을 하기 위해서는 `FROM` 구에서 `쉼표(,)`로 구분하여 두 테이블을 지정한다.
|
||||
|
||||
**`FROM구에 테이블 두 개를 지정해 곱집합 구하기`**
|
||||
```
|
||||
SELECT * FROM sample72_x, sample72_y;
|
||||
```
|
||||
|
||||
- 실행 결과, 야구의 대전표처럼 집합이 계산된 것을 알 수 있다.
|
||||
- `FROM` 구에 복수의 테이블을 지정하면 `교차결합`을 한다.
|
||||
- 교차결합은 두 개의 테이블을 곱집합으로 계산한다.
|
||||
|
||||
##### FROM 구에 복수의 테이블을 지정하면 교차결합을 한다!
|
||||
|
||||
### UNION 연결과 결합 연결의 차이
|
||||
- 앞서 `UNION`에서도 집합을 더해 새로 큰 집합을 만들어 계산할 수 있었다.
|
||||
- 한편으로는 `FROM` 구에서 복수의 테이블을 결합할 때도 새로 큰 집합을 만들어 계산한다.
|
||||
- 두 가지 방식이 서로 비슷하지만 확대 방향이 다르다.
|
||||
- `UNION`으로 합집합을 구했을 경우에는 세로 방향으로 더해지게 된다.
|
||||
- 한편 `FROM` 구로 테이블을 결합할 경우에는 가로 방향으로 더해지게 된다.
|
||||
|
||||
##### 결합은 열(가로)방향으로 확대된다!
|
||||
|
||||
---
|
||||
|
||||
## 2. 내부결합
|
||||
- `FROM` 구에 테이블을 복수로 지정하면 곱집합으로 계산되는 것을 배웠다.
|
||||
- 앞의 예제에서는 두 개 테이블을 사용했지만 세 개, 네 개로도 지정할 수 있다.
|
||||
- 단 테이블 수가 많아지면 조합 수가 엄청나게 늘어나 집합이 거대해진다.
|
||||
- 이렇게 많은 테이블응ㄹ 교차결합하는 경우는 드물다. 즉, 결합 방법으로는 교차결합보다 `내부결합`이 자주 사용된다.
|
||||
- 수학에서의 집합은 유일한 요소로 구성된다. 즉, 중복된 값이 존재하지 않는다는 뜻이다.
|
||||
- 마찬가지로 관계형 데이터베이스에서도 테이블의 데이터가 유일한 값을 가지도록 권장한다.
|
||||
- 간단히 말하면 기본키(primary key)를 가지도록 하는 게 좋다는 것이다.
|
||||
- 데이터베이스에는 다양한 데이터가 저장되지만 동일한 데이터를 중복해서 여러 곳에 저장하지 않도록 하는 편이 좋다.
|
||||
- 만약 데이터가 변경되는 경우 여기저기 저장되어 있는 데이터를 모두 동일한 값으로 변경하기란 힘든 일이기 때문이다.
|
||||
- 이때 기본키는 하나의 데이터행을 대표할 수 있는 속성을 가진다.
|
||||
- 예를 들어 상품의 가격이나 이름과 같은 데이터를 저장하는 '상품 테이블'을 작성한다고 가정하자.
|
||||
- 이때 상품의 속성으로는 상품명, 메이커명, 가격, 상품분류 등을 꼽을 수 있다.
|
||||
- 그 중에서 상품명을 기본키로 사용한다면 어떨까? 하지만 상품명의 경우 값이 중복할 우려가 있으므로 기본키로는 적합하지 않다.
|
||||
- 이러한 이유로 '상품코드'를 '기본키'로 사용하는 경우가 많다.
|
||||
|
||||
**`상품 테이블 작성하기`**
|
||||
```
|
||||
CREATE TABLE 상품 (
|
||||
상품코드 CHAR(4) NOT NULL,
|
||||
상품명 VARCHAR(30),
|
||||
메이커명 VARCHAR(30),
|
||||
가격 INTEGER,
|
||||
상품분류 VARCHAR(30),
|
||||
PRIMARY KEY(상품코드)
|
||||
);
|
||||
```
|
||||
|
||||
- 앞의 예제처럼 테이블을 만들어두면 동일한 상품명을 가진 상품이라도 구별하여 등록할 수 있다.
|
||||
- 일반적인 전자상거래 시스템에서 상품 테이블 하나만으로 운영하는 곳은 없다고 생각해도 무리는 아닐 것이다.
|
||||
- 상품 데이터를 참조하는 별도의 테이블이 존재한다는 이야기이다.
|
||||
- 예를 들어 재고도 같이 관리하는 경우에는 입출고나 재고 수를 상품단위로 관리하는 테이블이 존재하는 것이다.
|
||||
- 만약 재고관리 테이블을 만든다면 다음과 같이 작성할 수 있다.
|
||||
|
||||
**`재고수 테이블 작성하기`**
|
||||
```
|
||||
CREATE TABLE 재고수 (
|
||||
상품코드 CHAR(4),
|
||||
입고날짜 DATE,
|
||||
재고수 INTEGER
|
||||
);
|
||||
```
|
||||
|
||||
- 물론, 실제 시스템에서는 더 많은 열로 구성되어 있을 것이다.
|
||||
- 여기서는 상품 테이블을 참조하는 테이블의 예를 설명하기 위해 간단하게 재고관리 테이블을 만들었다.
|
||||
- 이러한 이유로 기본키도 따로 지정하지 않았지만, 재고수 테이블을 참조하는 다른 테이블을 위해 기본키를 지정해두는 것도 좋다.
|
||||
- 재고수 테이블에서의 착안점은 상품코드를 통해 상품 테이블과 연결할 수 있다는 것이다.
|
||||
- 상품 테이블의 기본키는 '상품코드'이다.
|
||||
- 이 열의 값을 알면 상품명을 포함한 상품 데이터를 참조할 수 있다.
|
||||
- 요컨대 다른 테이블의 데이터를 참조해야 하는 경우, 참조할 테이블의 기본키와 **동일한 이름과 자료형**으로 열을 만들어서 행을 연결하는 경우가 많다.
|
||||
- 재고수 테이블에서 상품분류가 식료퓸인 상품의 재고수를 표시하는 경우를 생각해보자.
|
||||
- 이 경우 상품코드보다 상품명으로 표시하면 알아보기 쉬울 것이다.
|
||||
- 재고수는 재고수 테이블에서 가져오면 되지만 상품명과 상품분류는 상품 테이블에 있다.
|
||||
- 이때 재고수 테이블과 상품 테이블을 결합해 가로로 나열하고자 하며, 그러기 위해서는 `FROM` 구에서 테이블을 서로 결합한다.
|
||||
|
||||
**`상품 테이블과 재고수 테이블을 교차결합하기`**
|
||||
```
|
||||
SELECT * FROM 상품, 재고수;
|
||||
```
|
||||
|
||||
- `FROM` 구에 테이블을 복수로 지정하면 곱집합으로 계산된다.
|
||||
- 상품 테이블 행(3행)에 재고수 데이터 행(3행)으로 곱집합을 구하면 행은 3 X 3 = 9 가 된다.
|
||||
- 이렇게 만들어진 집합에서 원하는 데이터를 검색하기 위해 `WHERE` 구로 조건을 지정한다.
|
||||
- 먼저 상품코드가 같다는 조건이 필요하다. 하지만 열 이름이 '상품코드'로 서로 동일하므로 `WHERE` 구에 조건식을 지정할 때 테이블 이름도 같이 지정할 필요가 있다.
|
||||
- 상품 테이블의 상품코드 열은 `'상품.상품코드'`로, 재고수 테이블의 상품코드 열은 `'재고수.상품코드'`로 지정한다.
|
||||
|
||||
**`상품코드가 같은 행을 검색하기`**
|
||||
```
|
||||
SELECT * FROM 상품, 재고수
|
||||
WHERE 상품.상품코드 = 재고수.상품코드;
|
||||
```
|
||||
|
||||
- 이렇게 교차결합으로 계산된 곱집합에서 원하는 조합을 검색하는 것을 `내부결합(Inner Join)`이라 부른다(결합 조건으로 보면 등결합 이라고도 부를 수 있다).
|
||||
- 다음으로는 상품분류가 '식료품'이라는 조건이 필요하다.
|
||||
- 이 조건을 `WHERE` 구에 추가하는데, 추가할 때는 기존 조건식과 상품분류의 조건식이 모두 참이어야 하므로 `AND`로 조건식을 연결한다.
|
||||
- 또한 상품명과 재고수만 반환하도록 `SELECT` 구에 열을 지정한다.
|
||||
|
||||
**`검색할 행과 반환할 열 제한하기`**
|
||||
```
|
||||
SELECT 상품.상품명, 재고수.재고수 FROM 상품, 재고수
|
||||
WHERE 상품.상품코드 = 재고수.상품코드 AND 상품.상품분류 = '식료품';
|
||||
```
|
||||
|
||||
- 위와 같은 명령으로 원하는 결과를 얻을 수 있다.
|
||||
- `WHERE` 구에는 두 개의 조건식이 지정되어 있다.
|
||||
- 첫 번째 조건식은 교차결합으로 계산된 곱집합에서 원하는 조합을 검색하는 것이다.
|
||||
- 두 번째 조건식은 결합 조건이 아닌 검색 조건이다.
|
||||
- 여기에서 첫 번째 조건식의 조건을 `결합조건`이라 부른다.
|
||||
|
||||
---
|
||||
|
||||
## 3. INNER JOIN으로 내부결합하기
|
||||
지금까지 설명한 결합방법에 관해 다음과 같이 간단히 정리하면 다음과 같다.
|
||||
|
||||
- `FROM` 구에 테이블을 복수 지정해 가로 방향으로 테이블을 결합할 수 있다.
|
||||
- 교차결합을 하면 곱집합으로 계산된다.
|
||||
- `WHERE` 조건을 지정해 곱집합에서 필요한 조합만 검색할 수 있다.
|
||||
|
||||
사실 지금까지 설명한 결합방법은 구식이다. 최근에는 `INNER JOIN` 키워드를 사용한 결합방법이 일반적으로 통용된다.
|
||||
|
||||
```
|
||||
SELECT 상품.상품명, 재고수.재고수
|
||||
FROM 상품 INNER JOIN 재고수 ON 상품.상품코드 = 재고수.상품코드
|
||||
WHERE 상품.상품분류 = '식료품';
|
||||
```
|
||||
|
||||
**`내부결합`**
|
||||
```
|
||||
SELECT * FROM 테이블명1 INNER JOIN 테이블명2 ON 결합조건
|
||||
```
|
||||
|
||||
- 구식 방법에서는 `쉼표(,)`로 구분하여 테이블을 `FROM` 구에 지정했다.
|
||||
- 새로운 형식에서는 테이블과 테이블 사이에 `INNER JOIN`이라는 키워드를 넣는다.
|
||||
- 여기서 `INNER`는 '안쪽'이라는 의미이며 `JOIN`은 '연결시키다'라는 의미이다.
|
||||
- 즉, `INNER JOIN`은 `내부결합`이라는 의미가 된다.
|
||||
- 구식 방법에서는 `WHERE` 구에 결합조건을 지정하였지만 `INNER JOIN`에서는 `ON`을 사용하여 결합조건을 지정한다.
|
||||
|
||||
##### INNER JOIN으로 두 개 테이블을 가로로 결합할 수 있다!
|
||||
|
||||
---
|
||||
|
||||
## 4. 내부결합을 활용한 데이터 관리
|
||||
`'하나의 데이터는 한 군데에 저장한다'`라는 룰에 따라 데이터 구조를 설계한다고 했을 때, 메이커코드와 메이커명을 가지는 메이커 테이블을 작성해 데이터를 관리해보자.
|
||||
|
||||
- 상품을 제조하는 메이커가 많이 있다고 해도 상품 수보다는 적을 것이다.
|
||||
- 이때 코드와 이름을 가지는 테이블로 분할해 관리하면 저장공간도 절약할 수 있다.
|
||||
|
||||
그럼 메이커 테이블을 작성하는 명령과 저장할 데이터를 살펴보도록 하자.
|
||||
|
||||
- 메이커코드는 메이커를 나타내는 코드라는 의미에서 맨 앞 자를 'M'으로 한다.
|
||||
- 여기에는 두 개의 메이커가 저장되어 있다.
|
||||
|
||||
**`메이커 테이블 작성하기`**
|
||||
```
|
||||
CREATE TABLE 메이커 (
|
||||
메이커코드 CHAR(4) NOT NULL,
|
||||
메이커명 VARCHAR(30),
|
||||
PRIMARY KEY (메이커코드)
|
||||
);
|
||||
```
|
||||
|
||||
- 상품 테이블에서는 메이커명을 메이커코드로 변경해 둔다.
|
||||
- 여기서 '상품코드'와 '상품명'처럼, 'OO코드'와 'OO명'의 조합으로 열을 지정하고 'OO코드'가 기본키가 되는 패턴은 자주 나오는 것이므로 기억해 두면 좋다.
|
||||
- 현재 두 개의 테이블로 분할되어 있지만 상품명과 메이커명을 같이 출력하고 싶을 때는 내부결합을 사용한다.
|
||||
|
||||
**`상품 테이블과 메이커 테이블을 내부결합하기`**
|
||||
```
|
||||
SELECT S.상품명, M.메이커명
|
||||
FROM 상품2 S INNER JOIN 메이커 M ON S.메이커코드 = M.메이커코드;
|
||||
```
|
||||
|
||||
- 이번에는 테이블에 별명을 붙여 보았다.
|
||||
- `SELECT` 명령에서 복수의 테이블을 다룰 경우 어느 테이블의 열인지 정확하게 지정해야 한다.
|
||||
- 이때 테이블명을 매번 지정하는 것은 번거로운 일이므로 짧게 줄여 별명을 붙이는 경우가 많다.
|
||||
- 앞의 예제에서도 메이커 테이블에는 'M', 상품 테이블에는 'S'라는 짧은 별명을 붙였다.
|
||||
- 상품 테이블의 메이커코드만을 살펴보면 중복하는 행이 있다.
|
||||
- 이것은 실제로도 있을 수 있는 이야기로 '상품OO와 상품XX는 같은 OO메이커가 제조한 상품'인 경우에 해당한다.
|
||||
- 단, 기본키 제약은 상품코드에만 적용되어 있어 데이터상으로도 제약에 위반되지 않는다.
|
||||
- 반대로 메이커 테이블은 메이커코드에 기본키가 지정되어 있기 때문에 중복을 허용하지 않는다.
|
||||
- 메이커코드는 유일하게 하나씩만 존재하며 중복될 수 없다. 존재하지 않거나 혹은 하나만 존재한다.
|
||||
- 이 부분이야말로 결합이나 데이터베이스의 테이블 설계를 이해하는 동시에 핵심이 되는 개념이다.
|
||||
- A 테이블과 B 테이블을 결합했을 때, A와 B 중 어느 쪽이 하나의 행만 가지는지(일대다, 다대일) 아니면 양쪽 모두 하나의 행을 가지는지(일대일) 등과 같은 `서로 결합하는 테이블 간의 관계`가 중요하다.
|
||||
|
||||
### 외부키
|
||||
- 메이커 테이블의 메이커코드는 `기본키`이다.
|
||||
- 그에 비해 상품 테이블의 메이커코드는 `외부키`라 불리는 것으로, `다른 테이블의 기본키를 참조하는 열`이 외부키가 된다.
|
||||
|
||||
### 자기결합(Self Join)
|
||||
- `자기결합`은 테이블에 별명을 붙일 수 있는 기능을 이용해 같은 테이블끼리 결합하는 것을 말한다.
|
||||
- 특별히 명령어가 정해져 있는 것은 아니다.
|
||||
|
||||
**`상품 테이블을 자기결합하기`**
|
||||
```
|
||||
SELECT S1.상품명, S2.상품명
|
||||
FROM 상품 S1 INNER JOIN 상품 S2 ON S1.상품코드 = S2.상품코드;
|
||||
```
|
||||
|
||||
- 상품 테이블을 가로로 두 개 나열해 상품코드로 결합했다.
|
||||
- 자기결합에서는 결합의 좌우가 같은 테이블이 되기 때문에 이를 구별하기 위해서 반드시 별명을 붙여야 한다.
|
||||
- 자기결합은 자기 자신의 기본키를 참조하는 열을 자기 자신이 가지는 데이터 구조로 되어 있을 경우에 자주 사용된다.
|
||||
|
||||
---
|
||||
|
||||
## 5. 외부결합
|
||||
- 결합 방법은 크게 `내부결합`과 `외부결합`의 두 가지로 구분된다.
|
||||
- 외부결합이라고 해도 교차결합으로 결합 조건을 지정하여 검색한다는 기본적인 사고 방식은 같다.
|
||||
- 외부결합은 `'어느 한 쪽에만 존재하는 데이터행을 어떻게 다룰지'`를 변경할 수 있는 결합 방법이다.
|
||||
- 만약 상품 테이블과 재고수 테이블 중에 상품 테이블에만 행이 존재하는 상황을 생각해보자.
|
||||
- 실제로 상품 데이터를 등록한 직후에는 이러한 상황이 존재할 수 있다.
|
||||
- 상품3 테이블에 상품코드가 0009인 행을 새롭게 추가한다.
|
||||
- 그러면 현재 상품3 테이블에는 행이 존재하지만 재고수 테이블에는 아직 이 상품에 대한 데이터가 없는 상태가 된다.
|
||||
- 이런 상태에서 곱집합을 구해도 `0009 = 0009`가 되는 행은 존재하지 않으므로 내부결합 결과에서는 상품코드가 0009인 상품이 제외된다.
|
||||
|
||||
**`내부결합에서는 상품코드가 0009인 상품이 제외된다`**
|
||||
```
|
||||
SELECT 상품3.상품명, 재고수.재고수
|
||||
FROM 상품3 INNER JOIN 재고수
|
||||
ON 상품3.상품코드 = 재고수.상품코드
|
||||
WHERE 상품3.상품분류 = '식료품';
|
||||
```
|
||||
|
||||
- 이런 경우에 외부결합을 사용하면 된다. 외부결합은 결합하는 테이블 중에 어느 쪽을 기준으로 할지 결정할 수 있다.
|
||||
- 이번에는 상품 테이블(결합의 왼쪽)을 기준으로 `INNER JOIN` 대신 `LEFT JOIN`을 사용한다.
|
||||
|
||||
**`외부결합으로 상품코드 0009인 상품도 결과에 포함하기`**
|
||||
```
|
||||
SELECT 상품3.상품명, 재고수.재고수
|
||||
FROM 상품3 LEFT JOIN 재고수
|
||||
ON 상품3.상품코드 = 재고수.상품코드
|
||||
WHERE 상품3.상품분류 = '식료품';
|
||||
```
|
||||
|
||||
- 재고수 테이블에는 0009에 대한 데이터가 없으므로 값이 `NULL`로 표시되는 점에 주의해야 한다.
|
||||
- 기준이 되는 상품 테이블을 `JOIN`의 왼쪽에 기술했으므로 `LEFT JOIN`이라 지정한다.
|
||||
- 상품 테이블을 오른쪽에 지정하는 경우나 재고 테이블을 기준으로 삼고 싶은 경우에는 `RIGHT JOIN`을 사용해 외부결합을 시행한다.
|
||||
|
||||
##### LEFT JOIN, RIGHT JOIN으로 외부결합을 할 수 있다!
|
||||
|
||||
### 구식방법에서의 외부결합과 표준 SQL
|
||||
- `MySQL`은 비교적 최근에 나온 데이터베이스이다. 따라서 구식 방법을 이용해도 내부결합은 가능하지만 외부결합은 할 수 없다. 그러므로 여기서는 `Oracle`의 경우를 예로 소개한다.
|
||||
- 구식 결합방법에서는 `FROM` 구에 결합 조건을 기술하지 않는다.
|
||||
- 대신 `WHERE` 구로 결합 조건을 지정한다. 그냥 조건식을 지정하면 내부결합이 되어버리므로, 외부결합으로 진행하고 싶은 경우에는 특별한 연산자를 사용한다.
|
||||
- `Oracle`에서는 데이터가 존재하지 않을 수도 있는 테이블의 열에 `(+)`라는 특수한 기호를 붙여서 조건식을 지정한다.
|
||||
|
||||
**`Oracle에서 구식 외부결합으로 0009의 상품을 결과에 포함하기`**
|
||||
```
|
||||
SELECT 상품3.상품명, 재고수.재고수
|
||||
FROM 상품3, 재고수
|
||||
WHERE 상품3.상품코드 = 재고수.상품코드 (+) AND 상품3.상품분류 = '식료품';
|
||||
```
|
||||
|
||||
- 그 밖에도 `SQL Server`에서는 `특수한 연산자(*= 또는 =*)`를 사용해서 외부결합을 할 수 있다.
|
||||
- 이전에는 이처럼 데이터베이스에 따라 서로 다른 방법으로 외부결합을 지원했다.
|
||||
- 즉, SQL의 방언에 속한다. 하지만 현재는 표준화로 인해 내부결합은 `INNER JOIN`, 외부결합은 `LEFT JOIN`이나 `RIGHT JOIN`을 사용하도록 권장한다.
|
||||
- 그러나 표준화가 진행된 현재에는 별다른 장점이 없는 구식 결합방법은 사용하지 않는다. 따라서 참고만 하도록 하자.
|
||||
|
||||
##### 구식 결합방법은 사용하지 않는다!
|
||||
|
||||
---
|
||||
72
도서/SQL첫걸음/Lecture33.md
Normal file
@@ -0,0 +1,72 @@
|
||||
# 33강. 관계형 모델
|
||||
- 관계형 모델을 기반으로 작성된 데이터베이스가 `관계형 데이터베이스`이다.
|
||||
- SQL은 관계형 모델에 의해 구축된 데이터베이스를 조작하는 체계적인 명령의 집합이다.
|
||||
- 관계형 모델에서 SQL이 만들어졌지만 유감스럽게도 관계형 모델에서 사용하는 용어와 SQL의 용어는 일치하지 않는다.
|
||||
- SQL을 사용하는 이상 관계형 모델의 용어를 몰라도 딱히 어려움은 없지만 알아두는 것이 좋다.
|
||||
|
||||
---
|
||||
|
||||
## 1. 관계형 모델
|
||||
- `관계형 모델(Relational Model)`의 기본적인 요소는 `릴레이션(Relation)`이다.
|
||||
- 이 릴레이션이라는 말 자체는 `관계`를 뜻하지만 관계형 모델에서는 약간 다른 의미를 가진다.
|
||||
- 결합에 관해 설명할 때 `일반적인 시스템의 데이터베이스에는 복수의 테이블이 있어 테이블 간의 관계가 중요하다`고 했다.
|
||||
- 관계형 모델의 릴레이션은 SQL에서 말하는 `테이블`에 해당한다. 테이블끼리의 관계가 아니다.
|
||||
|
||||
##### 릴레이션은 테이블을 말한다!
|
||||
|
||||
- 관계형 모델의 릴레이션에는 몇 가지 `속성(attribute)`이 있다.
|
||||
- 이 속성은 속성 이름과 형 이름으로 구성된다.
|
||||
- 속성은 SQL에서 말하는 열에 해당한다.
|
||||
- 그리고 SQL에서의 행은 관계형 모델에서 `튜플(tuple)`이라 불린다.
|
||||
- 정리하자면 릴레이션은 테이블, 속성은 열, 행은 튜플에 해당한다.
|
||||
- 관계형 모델은 데이터 구조에 관해 정의한다. 릴레이션은 튜플의 집합이며, 릴레이션에 대한 연산이 집합에 대한 연산에 대응된다는 이론을 `관계대수`라고 한다.
|
||||
- 이 같은 관계대수의 기본규칙은 다음과 같다.
|
||||
- 하나 이상의 관계를 바탕으로 연산한다.
|
||||
- 연산한 결과, 반환되는 것 또한 관계이다.
|
||||
- 연산을 중첩 구조로 실행해도 상관없다.
|
||||
- `UNION`이나 테이블의 결합을 익힌 만큼, 연산한 결과도 관계(릴레이션 = 테이블)이다.
|
||||
|
||||
---
|
||||
|
||||
## 2. 관계형 모델과 SQL
|
||||
- 관계대수에서는 자주 사용될 것 같은 릴레이션의 연산 방법을 몇 가지 규정한다.
|
||||
|
||||
### 합집합
|
||||
- `합집합(union)`은 릴레이션끼리의 덧셈을 말한다.
|
||||
- SQL에서는 `UNION`에 해당한다.
|
||||
- `SELECT * FROM A UNION SELECT * FROM B`
|
||||
|
||||
### 차집합
|
||||
- `차집합(difference)`은 릴레이션끼리의 뺄셈을 말한다.
|
||||
- SQL에서는 `EXCEPT`에 해당한다.
|
||||
- `SELECT * FROM A EXCEPT SELECT * FROM B`
|
||||
|
||||
### 교집합
|
||||
- `교집합(intersection)`은 릴레이션끼리의 공통부분(교집합)을 말한다.
|
||||
- SQL에서는 `INTERSECT`에 해당한다.
|
||||
- `SELECT * FROM A INTERSECT SELECT * FROM B`
|
||||
|
||||
### 곱집합
|
||||
- `곱집합(cartesian product)`은 릴레이션끼리의 대전표를 조합하는 연산을 말한다.
|
||||
- SQL에서는 `FROM` 구에 복수의 테이블을 지정한 경우 곱집합으로 계산된다.
|
||||
- 이때 `CROSS JOIN`으로 교차결합을 하면 곱집합을 구할 수 있다.
|
||||
- `SELECT * FROM A, B`
|
||||
- `SELECT * FROM A CROSS JOIN B`
|
||||
|
||||
### 선택
|
||||
- `선택(selection)`은 튜플의 추출을 말하며, 선택은 제한이라 불리기도 한다.
|
||||
- 튜플은 SQL에서 행을 말하기 때문에 `WHERE` 구에 조건을 지정해 데이터를 검색하는 것에 해당된다.
|
||||
- `SELECT * FROM A WHERE no < 3`
|
||||
|
||||
### 투영
|
||||
- `투영(projection)`은 속성의 추출을 말한다.
|
||||
- SQL에서 속성은 열을 말하기 때문에 `SELECT` 구에 결과로 반환할 열을 지정하는 것에 해당된다.
|
||||
- `SELECT a FROM A`
|
||||
|
||||
### 결합
|
||||
- `결합(join)`은 릴레이션끼리 교차결합해 계산된 곱집합에서 결합조건을 만족하는 튜플을 추출하는 연산이다.
|
||||
- SQL에서는 내부결합에 해당한다.
|
||||
- 관계대수에도 내부결합과 외부결합이 있다.
|
||||
- `SELECT a FROM A INNER JOIN B ON A.no = B.no`
|
||||
|
||||
---
|
||||
114
도서/SQL첫걸음/Lecture34.md
Normal file
@@ -0,0 +1,114 @@
|
||||
# 34강. 데이터베이스 설계
|
||||
여기에서는 데이터베이스 설계의 개념 및 설계도를 읽는 방법 등에 관해 알기 쉽게 설명한다. 나아가서는 트랜젝션에 대해서도 다룬다. 트랜젝션은 데이터베이스 설계의 방법이라고는 할 수 없지만 시스템 개발 현장에서 자주 쓰이는 기능 중 하나이다.
|
||||
|
||||
---
|
||||
|
||||
## 1. 데이터베이스 설계
|
||||
- 데이터베이스를 설계한다는 것은 데이터베이스의 스키마 내에 테이블, 인덱스, 뷰 등의 데이터베이스 객체를 정의하는 것을 말한다.
|
||||
- 스키마 내에 정의한다는 뜻에서 `스키마 설계`라 부르기도 한다.
|
||||
- 데이터베이스 설계의 주된 내용은 테이블의 이름이나 열, 자료형을 결정하는 것이다.
|
||||
- `이 테이블은 이 열을 이용해 저쪽 테이블과 연결한다`와 같이 테이블 간의 관계를 생각하면서 여러 테이블을 정의하고 작성하게 된다.
|
||||
- 단, 설계인 이상 테이블 정의에만 그치지 않는다.
|
||||
|
||||
### 논리명과 물리명
|
||||
- 테이블을 설계할 때는 테이블 정의서나 설계도 등의 문서를 작성하는 경우가 많다.
|
||||
- 문서 양식은 여러 가지가 있으나 일반적으로 다음과 같은 양식을 사용한다.
|
||||
|
||||
`테이블명 : 상품`
|
||||
|열명|자료형|NULL|기본값|비고|
|
||||
|-|-|-|-|-|
|
||||
|상품코드|CHAR(4)|No|||
|
||||
|상품명|VARCHAR(30)|Yes|||
|
||||
|가격|INTEGER|Yes|||
|
||||
|
||||
- `DESC` 명령에 따라 표시되는 결과를 그대로 옮겨적은 것이라 봐도 무방하다.
|
||||
- 이외에 어느 열이 기본키인지를 지정하는 경우도 있다.
|
||||
- 테이블을 설계할 때는 테이블 이름이나 열 이름을 지정하는데, 하나의 테이블에 대해 두 개 의 이름을 지정할 때도 있다.
|
||||
- 하나는 데이터베이스에서 사용할 이름으로, 실제로는 `CREATE TABLE`에 지정하는 이름을 말하며 `물리명`이라고 부른다.
|
||||
- 또 하나는 `논리명`이라는 것으로 테이블의 `설계상 이름`에 해당한다.
|
||||
- 물리명은 데이터베이스 시스템 규칙에 따라 길이에 제한이 있거나 공백문자를 사용할 수 없는 등의 제약이 따른다.
|
||||
- 따라서 일상에서 사용하는 단어로는 이름을 지정하는 데 한계가 있다.
|
||||
- 또한 전통적으로 알파벳을 사용해 이름을 지정한다.
|
||||
- 예를 들면 테이블의 물리명은 'item_master', 논리명은 '상품 마스터'로 지정하는 경우가 그것이다.
|
||||
- 길이도 제한되다 보니 생략하거나 약자로 이름을 붙이는 경우도 많다.
|
||||
- 그러다 보면 물리명만으로는 의미가 전달되지 않는 경우도 많아 논리명이 필요해진다.
|
||||
- 여기서 차이점은, 물리명의 경우 `CREATE TABLE` 명령으로 테이블을 작성할 때 사용하는 이름이라면, 논리명은 해당 테이블을 실제로 부를 때 사용하는 이름이라는 점이다.
|
||||
- 물리명은 잘못 정하면 변경하기 힘들지만 논리명은 언제나 바꿀 수 있다.
|
||||
|
||||
##### 물리명은 CREATE TABLE에 지정하는 테이블이나 열 이름이다!
|
||||
##### 논리명은 설계상의 이름이다!
|
||||
|
||||
- 이러한 이유로 물리명과 논리명이 함꼐 기재된 설계도나 정의서도 있다.
|
||||
- 경우에 따라서는 별도의 논리명 기입 항목을 지정하지 않고 비고란에 기재하는 경우도 있다.
|
||||
|
||||
### 자료형
|
||||
- 테이블의 열에는 자료형을 지정해야 한다.
|
||||
- 데이터베이스에 따라 다르지만 무엇이든 저장할 수 있는 자료형은 없다.
|
||||
- 수치 데이터만 저장하는 열에는 설계 시 수치형으로 지정한다.
|
||||
- 따라서 금액이나 개수처럼 수치 데이터만 다룰 수 있는 열은 주저없이 수치 자료형으로 지정하면 된다.
|
||||
- 한편 제조번호처럼 알파벳도 다루어야 한다면 문자열형으로 지정하는 편이 낫다.
|
||||
- 수치형을 문자열형으로 변환하는 것은 문제가 되지 않지만 문자열형을 수치형으로 변환하는 경우에는 에러가 발생하기도 해 번거로울 수 있다.
|
||||
- 데이터에 따라서는 '1, 2, 3 중에 하나'라든가 'yes, no중에 하나'만 데이터 값으로 취급하는 경우가 생기기도 한다.
|
||||
- 이런 경우에는 데이터베이스 기능으로 제약(CHECK 제약)을 걸 수 있으므로 데이터 정합성이 중요한 부분에는 적극적으로 사용할 필요가 있다.
|
||||
- 일반적으로는, 데이터베이스 시스템에서 데이터 정합성을 체크할 수 있다면 데이터베이스에 맡겨버리는 편이 가장 확실하고 편리하다.
|
||||
- 이런 기능을 활용하는 대신 애플리케이션에서 따로 구현해 사용할 수도 있지만, 이런 경우 정합성이 맞지 않을 수 있으며 개발비용도 상승해 추천하지 않는다.
|
||||
- 한편, 앞에서 예로 든 '1, 2, 3' 등의 경우 각 숫자에 '상, 중, 하'와 같은 의미를 부여해 데이터를 사용할 때는 정의서의 비고란에 적어두는 경우가 많다.
|
||||
- 데이터의 의미를 따로 정의할 수 없기 때문에 비고란도 중요한 역할을 한다.
|
||||
- `MySQL`에서는 테이블을 작성할 때 `comment`라는 키워드를 이용하여 주석을 열 단위로 기입해 둘 수 있다.
|
||||
|
||||
### 고정길이와 가변길이
|
||||
- 문자열의 자료형에는 고정길이와 가변길이가 있다.
|
||||
- 어느쪽으로 지정할 것인지는 저장할 데이터를 고려해 결정한다.
|
||||
- 예를 들어 제조번호처럼 자리수가 이미 정해져 있는 경우에는 고정길이 문자열로 지정하는 편이 좋다.
|
||||
- 데이터의 최대길이 역시 제조번호의 자릿수에 맞춰 정하면 된다.
|
||||
- 한편, 비고란과 같이 자주 입력되지도 않지만 입력되는 문자열의 길이의 변동폭이 클 경우에는 가변길이 문자열이 적합하다.
|
||||
- 데이터베이스의 열에 저장할 수 있는 크기는 의외로 작다.
|
||||
- `VARCHAR` 형으로 지정할 수 있는 최대 크기는 기껏해야 수천 바이트이다.
|
||||
- 조금 큰 파일을 그대로 `VARCHAR` 형의 열에 저장하면 쉽게 용량을 넘겨버린다.
|
||||
- 이러한 경우에는 `LOB` 형을 사용한다.
|
||||
- 여기서 `LOB`는 `Large Object`의 약자이다.
|
||||
- `LOB`형은 큰 데이터를 다루는 자료형이지만 인덱스를 지정할 수 없다는 제약이 있다.
|
||||
|
||||
##### 큰 데이터는 LOB 형으로 저장할 수 있다!
|
||||
|
||||
### 기본키
|
||||
- 테이블을 작성할 때 기본키 제약을 거는 경우에는 주의를 기울여야 한다.
|
||||
- 테이블의 행에 유일성을 지정한다는 것은 대단히 중요한 일이다.
|
||||
- 하지만 기본키로 지정할 열이 생각나지 않는 경우도 많을 것이다.
|
||||
- 이러한 경우 자동증가 열을 사용해서 기본키로 지정하면 간단하게 해결할 수 있다.
|
||||
- 자동증가 열은 `INSERT` 할 경우 번호를 자동으로 증가시켜 저장해주는 편리한 열이다.
|
||||
- 데이터베이스 제품에 따라 다르지만, `MySQL`의 경우는 열을 정의할 때 `AUTO_INCREMENT`를 지정하는 것으로 자동증가 열이 된다.
|
||||
- `AUTO_INCREMENT`로 지정한 열은 `PRIMARY KEY` 또는 `UNIQUE`로 유일성을 지정해야 한다. 아무 열이나 자동증가 열로 지정하지 않도록 주의해야 한다.
|
||||
- 테이블 설계에 관련해 정규화라는 것도 있다(추후에 설명).
|
||||
- 지금까지 소개한 여러 요소들을 바탕으로 테이블 정의서가 작성되므로 테이블 정의서를 소홀하게 여기지 않도록 하자.
|
||||
|
||||
---
|
||||
|
||||
## 2. ER다이어그램
|
||||
- 테이블을 설계할 때 테이블 간의 관계를 명확히 하기 위해 설계도를 작성하는 경우가 있다.
|
||||
- `ER다이어그램`은 이런 경우에 널리 쓰이는 도식이다.
|
||||
- `ER`의 `E`는 개체를 뜻하는 `Entity`의 약자이며 `R`은 `Relationship`의 약자이다.
|
||||
- 즉, `ER다이어그램`은 개체 간의 관계를 표현한 것이다.
|
||||
- 여기에서도 관계라는 단어가 나오는데, ER다이어그램의 관계는 관계형 데이터베이스의 릴레이션과 달리 릴레이션십을 가리킨다.
|
||||
- 여기서는 헷갈리지 않도록 릴레이션십을 연계라 불러 구별한다.
|
||||
- 이 같은 ER다이어그램은 관계형 데이터베이스 외의 대상에 대해서도 사용된다.
|
||||
- 엔티티, 즉 개체는 테이블 또는 뷰를 말한다.
|
||||
- ER다이어그램에서 개체는 사각형으로 표기한다. 사각형의 상단에는 개체 이름을 적고 사각형 안에는 개체의 속성을 표기한다.
|
||||
- 여기서 속성은 테이블의 열을 의미한다.
|
||||
- 기본키가 되는 열부터 차례로 기술하며, 열 이름은 주로 논리명으로 표기한다.
|
||||
- 개체와 개체가 서로 연계되는 경우에는 선으로 이어서 표현한다.
|
||||
- 앞에서 결합을 설명할 때 작성했던 상품 테이블과 메이커 테이블은 메이커코드를 매체로 연결된다.
|
||||
- 이것을 ER다이어그램으로 표현하면 다음과 같다.
|
||||
|
||||
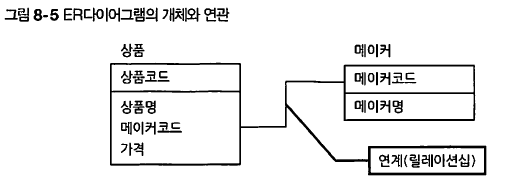
|
||||
|
||||
- 연계를 표기할 때는 서로 몇 개의 데이터 행과 연관되는지, 즉 몇 대 몇의 관계를 가지는지를 숫자나 기호로 나타낼 수 있다(카디널리티 또는 다중도라고 한다).
|
||||
- 이는 매우 중요한 것으로, 여러 가지 패턴의 표기방법 중에서도 가장 기본적인 세 가지는 다음과 같다.
|
||||
- 일대일(1 : 1)
|
||||
- 일대다(1 : 多)
|
||||
- 다대다(多 : 多)
|
||||
- ER다이어그램의 연계는 데이터베이스에서는 외부참조제약(외부키 제약)으로 지정되는 경우가 있으므로 기억해두자.
|
||||
- 외부키 제약을 설정하면 데이터의 정합성이 엄격히 관리되어 번거로워진다는 이유로 이를 채용하지 않는 시스템도 있다.
|
||||
- `설계상 이렇게 연관되어 있다`라고 나타내는 것이 ER다이어그램의 역할이다.
|
||||
|
||||
---
|
||||
142
도서/SQL첫걸음/Lecture35.md
Normal file
@@ -0,0 +1,142 @@
|
||||
# 35강. 정규화
|
||||
테이블을 올바른 형태로 변경하고 분할하는 것을 정규화라 한다.
|
||||
|
||||
- 정규화란 데이터베이스의 테이블을 규정된 올바른 형태로 개선해나가는 것이다.
|
||||
- 정규화는 데이터베이스의 설계 단계에서 행해진다.
|
||||
- 경우에 따라서는 기존 시스템을 재검토할 때 정규화하는 경우도 있다.
|
||||
- 여기서 말하는 올바른 형태란 주관적 기준이라 할 수 있다.
|
||||
- 정규화의 순서는 이전의 데이터베이스 기술자들이 고안해 정리한 것이다.
|
||||
- 이를 참고하여 정규화하는 과정을 통해 관계형 데이터베이스가 효율적으로 동작하도록 만들 수 있다.
|
||||
- 잘만 활용하면 효율적인 데이터베이스를 설계할 수 있다.
|
||||
|
||||
---
|
||||
|
||||
## 1. 정규화
|
||||
먼저, 쇼핑 사이트의 주문처리 시스템을 구축해본다. 그에 앞서 간단한 주문데이터로는 어떤 것이 필요할지 생각해 본다.
|
||||
|
||||
**`간단한 주문 데이터`**
|
||||
|
||||
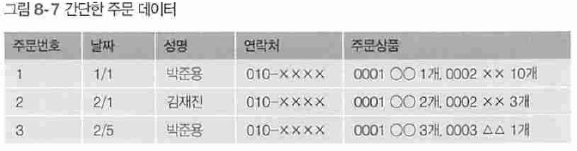
|
||||
|
||||
- 여기서 주문상품 부분이 특별한 형식 없이 대충 만들어진 것처럼 보여 문제가 될 수 있다. 따라서 상품은 상품코드를 이용해 다루도록 한다.
|
||||
- '0001 OO 1개'라고 되어 있는 부분은 상품코드가 0001인 상품 OO를 1개 주문했다는 뜻이다.
|
||||
- 물론 한번 주문할 때 여러 개의 상품을 주문할 수도 있다.
|
||||
- 주문번호 1의 데이터를 살펴보면 '0001 OO이 1개, 0002 XX가 10개'로 두 가지 종류의 상품을 주문했다는 것을 알 수 있다.
|
||||
- 이렇게 대충 만들어진 데이터를 정규화해 데이터베이스의 테이블로 만들어 본다.
|
||||
- 정규화는 단계적으로 실시한다. 그 첫 번째 단계가 `제1 정규화`로, 이를 시행하면 제1 정규형 테이블을 만들 수 있다.
|
||||
|
||||
---
|
||||
|
||||
## 2. 제1 정규형
|
||||
- 관계형 데이터베이스의 테이블에는 하나의 셀에 하나의 값만 저장할 수 있다는 제약이 있다.
|
||||
- 이로 인해 주문상품의 데이터를 그대로 테이블로 만들 수는 없다.
|
||||
- 적어도 상품코드와 상품명, 개수 데이터를 담는 세 개의 열로 나누어야 한다.
|
||||
|
||||
**`주문상품 데이터를 상품코드, 상품명, 개수로 분할하기`**
|
||||
|
||||
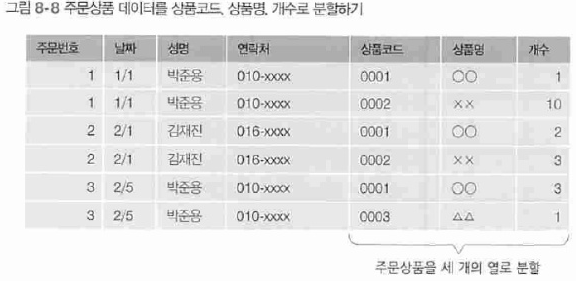
|
||||
|
||||
- 위처럼 구분하면 하나의 셀에는 하나의 값만 저장되므로 테이블화 할 수 있다.
|
||||
- 이때 테이블 이름은 '주문'이라 한다.
|
||||
- 주문상품 데이터를 상품코드와 개수로 분할함에 따라 열이 두 개 더 추가되었고 행도 늘어난 것에 주목하자.
|
||||
- 이렇게 하나의 셀에 하나의 값만 저장할 수 있도록 하고, 반복되는 부분을 세로(행) 방향으로 늘려나가는 것이 제1 정규화의 제 1단계이다.
|
||||
|
||||
##### 반복되는 데이터를 가로(열 방향)가 아닌 세로(행 방향)로 늘리는 것이 제1 정규화의 제1 단계이다!
|
||||
|
||||
- 제1 정규화에서는 중복을 제거하는 테이블의 분할도 이루어진다.
|
||||
- 예를 들면 한번의 주문으로 여러 개의 상품을 주문할 수 있으므로 주문번호, 날짜, 성명, 연락처가 동일한 값을 가지는 행이 여러 개 존재할 수 있다.
|
||||
- 이때 동일한 값을 가지는 행이 여러 개 존재하지 않도록 하나로 정리한다.
|
||||
- 먼저, 주문 테이블을 주문상품 테이블과 주문 테이블로 나눈다.
|
||||
- 주문 테이블은 주문번호, 날짜, 성명, 연락처로 구성한다.
|
||||
- 한편 주문상품 테이블을 상품코드, 상품명, 개수로 구성하되, 추가적으로 주문 테이블과 결합할 수 있도록 주문번호 열을 추가한다.
|
||||
|
||||
**`주문 데이터를 주문 테이블과 주문상품 테이블로 분할`**
|
||||
|
||||
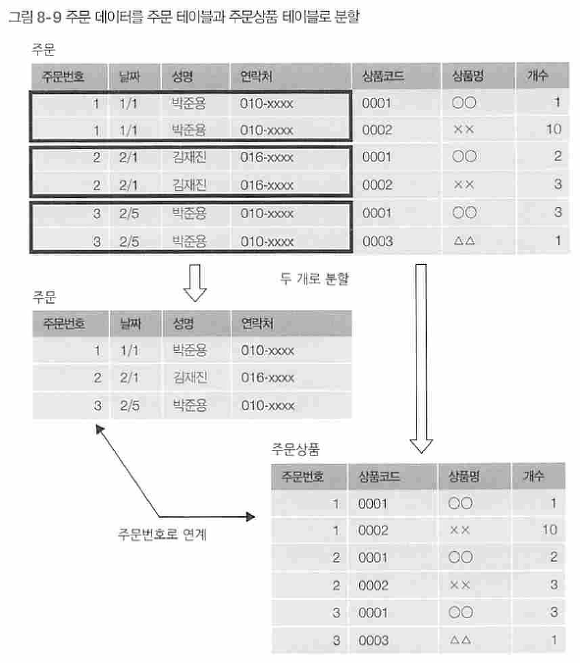
|
||||
|
||||
- 그 결과 반복되는 부분이 하나로 깔끔하게 정리되었다.
|
||||
- 이것으로 주문 데이터가 변경되더라도 한 군데만 수정하면 된다.
|
||||
- 물론 분할 전 상태의 데이터를 원할 때에도 결합하면 되므로 아무런 문제가 없다.
|
||||
- 여기에서 분할 이후의 주문 테이블을 자세히 살펴보면, 주문번호에는 중복된 값이 존재하지 않기 때문에 기본키로 지정할 수 있다.
|
||||
- 한편 주문상품 테이블에서는 주문 번호와 상품코드를 한데 묶어 기본키로 지정할 수 있다.
|
||||
- 이처럼 제1 정규화에서는 반복되는 부분을 찾아내서 테이블을 분할하고 기본키가 될 열을 작성할 수 있다.
|
||||
|
||||
##### 제1 정규화에서는 테이블 분할과 기본키 지정이 이루어진다!
|
||||
|
||||
---
|
||||
|
||||
## 3. 제2 정규형
|
||||
- 제1 정규화에서 테이블에 기본키를 작성한 것과 같은 방법으로, `제2 정규화`에서는 데이터가 중복하는 부분을 찾아내어 테이블로 분할해 나간다.
|
||||
- 이때 기본키에 의해 특정되는 열과 그렇지 않은 열로 나누는 것으로 정규화가 이루어진다.
|
||||
- 주문상품의 기본키는 주문번호와 상품코드의 두 개 열로 되어 있다.
|
||||
- 주문번호 1에 상품코드가 0001인 상품 주문량은 총 1개라는 것을 알 수 있다.
|
||||
- 이것은 기본키를 바탕으로 특정되는 데이터이다.
|
||||
- 즉, 개수 열은 기본키가 결정되고나면 특정할 수 있는 것이다.
|
||||
- 한편 상품명은 주문번호와 관계없이 상품코드만으로 특정할 수 있다.
|
||||
- 상품코드는 기본키의 일부이긴 하지만 단독으로 기본키 역할을 할 수는 없다.
|
||||
- 이처럼 두 가지로 분류할 수 있으므로 두 개 테이블로 분할한다.
|
||||
- 테이블명은 '상품'이라고 한다.
|
||||
|
||||
**`주문상품 테이블을 분할`**
|
||||
|
||||
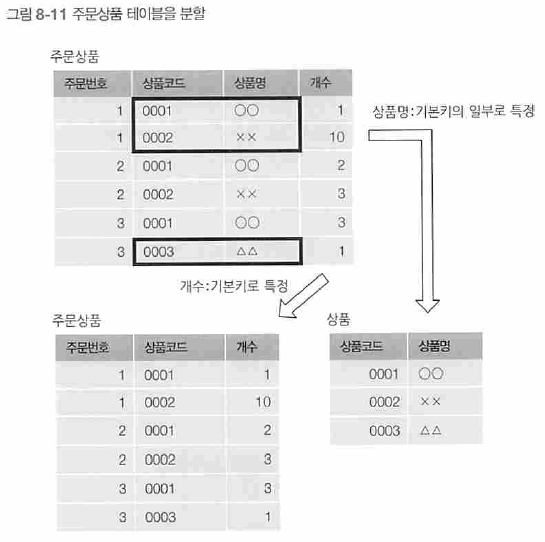
|
||||
|
||||
- 상품 테이블은 상품코드만으로 기본키를 지정했다.
|
||||
- 어려운 말로 표현하자면 부분 함수종속성을 찾아내서 테이블을 분할하는 것이 제2 정규화이다.
|
||||
- 여기서 함수종속성이란 키 값을 이용해 데이터를 특정지을 수 있는 것을 가리킨다.
|
||||
|
||||
---
|
||||
|
||||
## 4. 제3 정규형
|
||||
- 마지막으로 `제3 정규화`이다. 이 또한 중복하는 부분을 찾아내어 테이블을 분할하는 수법이다.
|
||||
- 제2 정규화의 경우에는 기본키에 중복이 없는지 조사했지만 제3 정규화에서는 기본키 이외의 부분에서 중복이 없는지를 조사한다.
|
||||
|
||||
**`주문 테이블을 분할`**
|
||||
|
||||
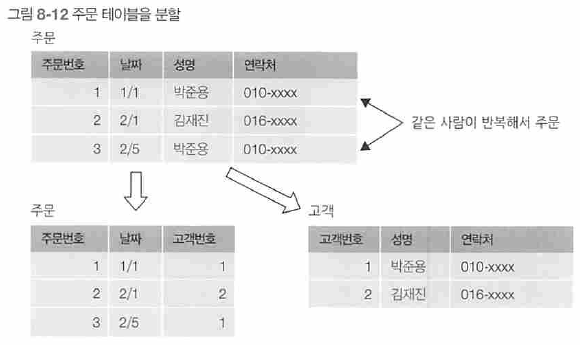
|
||||
|
||||
- 분할하기 전의 주문 테이블을 살펴보면 데이터가 중복되어 있다.
|
||||
- 같은 사람이 여러 번 주문하는 경우가 있기 때문이다.
|
||||
- 이때 주문 테이블에서 이름을 기준으로 연락처를 특정지을 수 있다.
|
||||
- 단, 주문 테이블의 기본키는 어디까지나 주문번호로, 이름은 기본키와는 관계가 없다.
|
||||
- 한편 분할하여 새로 만들 테이블의 이름은 '고객'이라 붙였다.
|
||||
- 여기서도 이름을 기본키로 지정하면 동명이인의 경우 데이터를 제대로 저장할 수 없으므로 고객번호를 기본키로 지정하여 고객 테이블을 작성했다.
|
||||
|
||||
실제로는 제5 정규형까지 있지만 대부분의 시스템에서 제3 정규형까지의 정규화를 채택한다.
|
||||
|
||||
**`정규화 후의 테이블`**
|
||||
|
||||
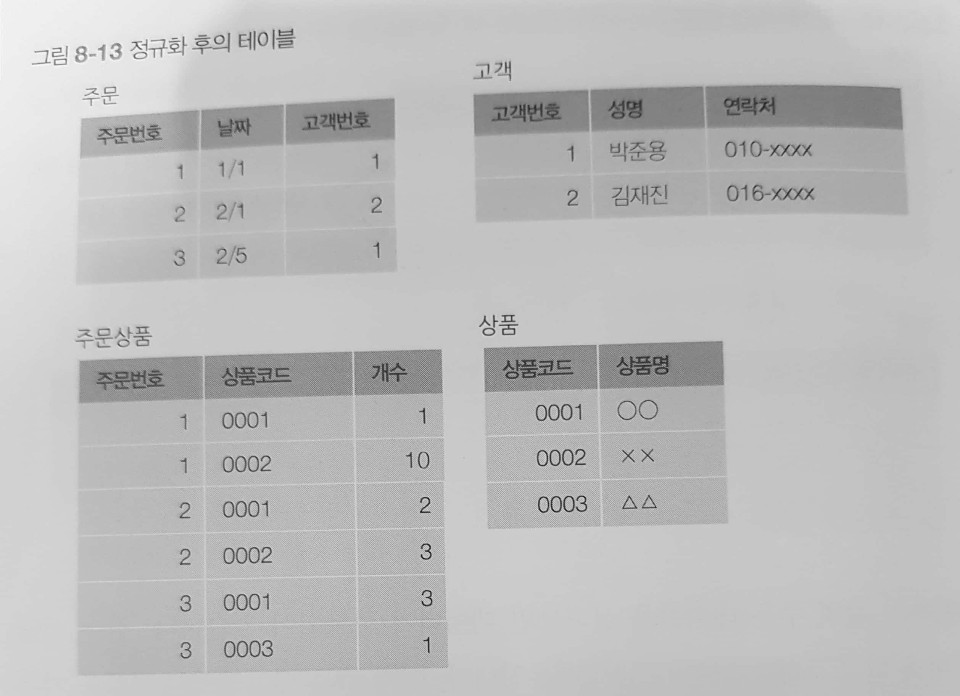
|
||||
|
||||
- 이처럼 정규화를 통해 테이블을 분할해 나간다.
|
||||
- 분할할 때에는 서로 결합할 수 있도록 기본키를 추가해 분할한다.
|
||||
- 테이블 간의 연계는 ER다이어그램으로 표현하면 알기 쉽다.
|
||||
|
||||
**`정규화 후의 테이블을 ER다이어그램으로 표기`**
|
||||
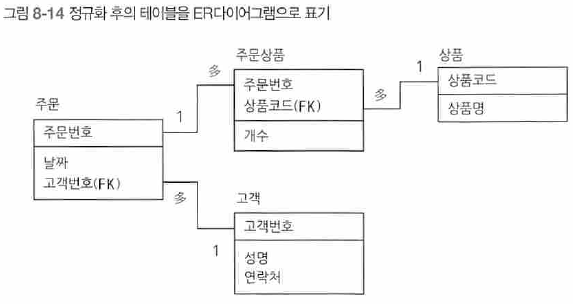
|
||||
|
||||
- ER다이어그램에서는 네모난 상자(엔티티)가 테이블을 의미한다.
|
||||
- 테이블 간의 선이 연계(릴레이션십)을 의미하며 1대多, 多대1 등과 같은 다중도로도 표시한다.
|
||||
- 주문상품 테이블과 상품 테이블 간의 연계(릴레이션십)에서는 상품 쪽이 1, 주문상품 쪽이 多로 1대多라는 다중도를 나타낸다.
|
||||
- 즉, 주문상품 테이블 쪽의 데이터에서 상품 테이블을 보면 상품 테이블의 하나의 행을 특정하는 것이다.
|
||||
- 이는 상품코드가 기본키인 만큼 당연한 일이다.
|
||||
- 반대로 상품 테이블 쪽에서 주문상품 테이블을 보면 하나의 상품이 여러 번 주문되었기 때문에 상품코드를 이용해도 주문상품 테이블의 하나의 행만 특정할 수 없다.
|
||||
- 다시 말해 여러 개의 행이 존재한다는 이야기이다.
|
||||
- 그 밖에 주문상품의 상품코드에 (FK)라고 적혀 있는 것은 외부키 속성을 가진다는 의미이다.
|
||||
|
||||
---
|
||||
|
||||
## 5. 정규화의 목적
|
||||
- 정규화에서는 중복하거나 반복되는 부분을 찾아내서 테이블을 분할하고 기본키를 작성해 사용하는 것을 기본 개념으로 삼는다.
|
||||
- 이는 `하나의 데이터는 한 곳에 있어야 한다`는 규칙에 근거한다.
|
||||
|
||||
##### 정규화로 데이터 구조를 개선하는 것은 하나의 데이터가 한 곳에 저장되도록 하기 위함이다!
|
||||
|
||||
- 하나의 데이터가 반드시 한 곳에만 저장되어 있다면 데이터를 변경하더라도 한 곳만 변경하는 것으로 끝낼 수 있다.
|
||||
- 반면 정규화되지 않은 경우에는 여기저기 중복해서 저장된 데이터를 검색하고 일일이 변경해야 한다.
|
||||
- 이것은 매우 번거로운 작업이다.
|
||||
- 또한 인덱스가 지정된 열의 데이터가 변경되는 경우에는 인덱스도 재구축해야 한다.
|
||||
- 하지만 기본키는 분할한 테이블끼리 연계하기 위해 작성한, 이른바 내부적인 데이터이므로 변경될 일은 거의 없다.
|
||||
- 따라서 정규화를 통해 테이블에 대한 인덱스의 재구축을 억제할 수 있다.
|
||||
|
||||
---
|
||||
131
도서/SQL첫걸음/Lecture36.md
Normal file
@@ -0,0 +1,131 @@
|
||||
# 36강. 트랜잭션
|
||||
여기에서는 트랜잭션에 대해서 알아본다.
|
||||
|
||||
**`트랜잭션의 제어`**
|
||||
```
|
||||
START TRANSACTION
|
||||
COMMIT
|
||||
ROLLBACK
|
||||
```
|
||||
|
||||
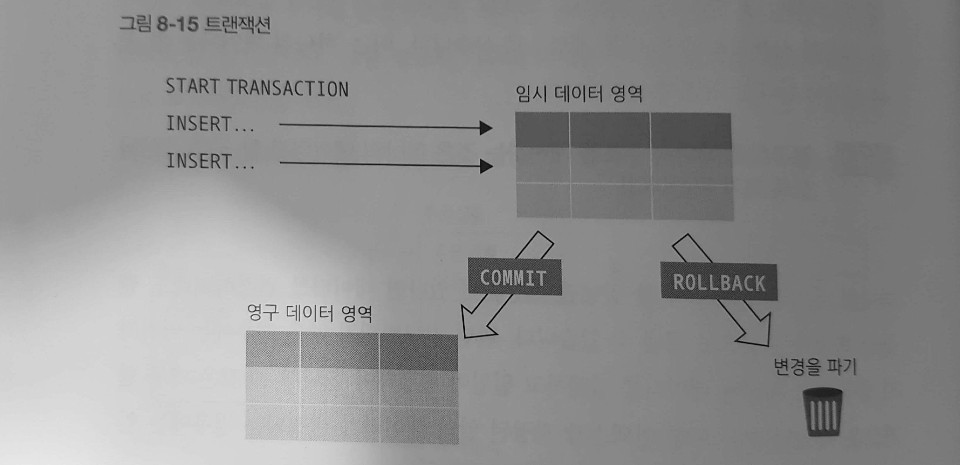
|
||||
|
||||
- 데이터베이스는 `트랙잭션`이라는 기능을 제공한다.
|
||||
- `INSERT`나 `UPDATE` 명령으로 데이터를 추가, 갱신할 때도 트랜잭션 기능을 사용하지만 지금까지 특별히 의식할 필요는 없었다.
|
||||
- 이는 자동 커밋이라 불리는 기능이 동작했기 때문이다.
|
||||
|
||||
---
|
||||
|
||||
## 1. 트랜잭션
|
||||
정규화에 의해 분할된 주문 테이블과 주문상품 테이블의 관계를 생각해보자.
|
||||
|
||||
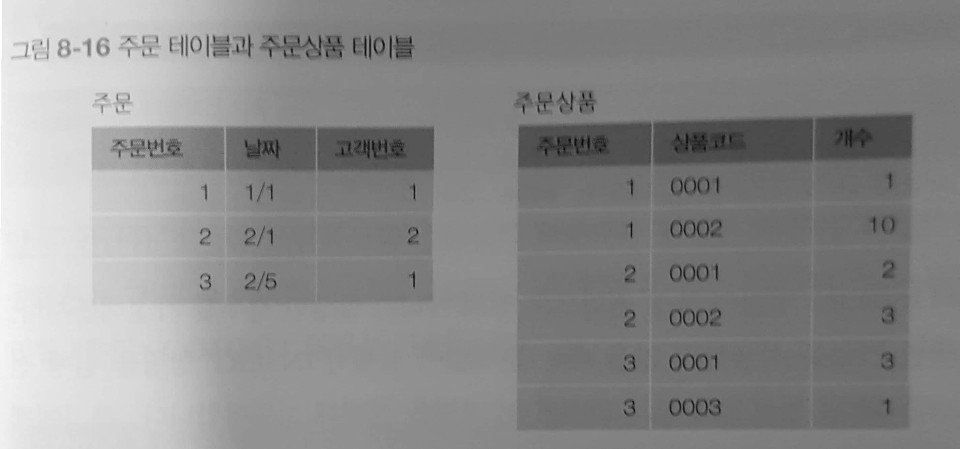
|
||||
|
||||
- 주문 테이블과 주문상품 테이블 사이에는 의존관계가 존재한다.
|
||||
- 주문 테이블에 행이 존재한다면 주문상품 테이블에는 적어도 하나의 행이 존재해야 한다.
|
||||
- 그렇지 않으면 주문한 상품이 없는데도 주문이 된 상태가 된다.
|
||||
- 보통은 하나 이상의 상품을 주문하므로 주문이 발생하면 주문 테이블과 주문상품 테이블 모두 행이 추가된다.
|
||||
- 물론 있다, 없다는 주문번호와 관련이 있으므로 '같은 주문번호로'라는 조건을 붙일 수 있다.
|
||||
|
||||
### 발주처리
|
||||
- 주문이 발생했을 때 어떻게 처리되는지 생각해보자. 간단히 말하자면 발주처리에 관한 것으로, 먼저 주문번호를 지정해야 한다.
|
||||
- 이때 기존 주문과 구분되는 주문번호를 발행하는 처리가 필요하다.
|
||||
- 자동 증가를 사용하면 자동적으로 번호가 부여되지만 그렇지 않은 경우에는 '번호 중 가장 큰 값을 `SELECT` 명령으로 가져와 그 값에 1을 더한다'라는 처리가 필요하다.
|
||||
- 최대값은 `MAX()`로 검색할 수 있으므로 `MAX + 1`이라 할 수도 있다.
|
||||
- 번호를 발행 받았다면 해당 번호를 키로 삼아 `INSERT`가 이루어진다.
|
||||
- 주문 테이블에는 `INSERT` 한 번, 주문상품 테이블에는 주문된 상품 수만큼 `INSERT` 명령이 실행된다.
|
||||
- 중요한 것은 복수의 테이블에 `INSERT` 되므로 실행되는 명령은 최소 두 번이라는 것이다.
|
||||
|
||||
**`발주처리`**
|
||||
```
|
||||
INSERT INTO 주문 VALUES(4, '2014-03-01', 1);
|
||||
INSERT INTO 주문상품 VALUES(4, '0003', 1);
|
||||
INSERT INTO 주문상품 VALUES(4, '0004', 2);
|
||||
```
|
||||
|
||||
- 여기서 `INSERT` 명령이 특정 원인으로 인해 에러가 발생한 경우를 가정해보자.
|
||||
- 트랜잭션 기능을 사용하지 않을 때는 문제없이 실행된 `INSERT` 명령을 실행 전으로 되돌릴 수 없으므로 따로 `DELETE` 명령을 실행해 지워야한다.
|
||||
- 즉, 위의 세 번째 `INSERT` 명령에서 에러가 발생했다고 치면, 앞서 실행한 두 개의 `INSERT` 명령에 의해 추가된 데이터를 `DELETE` 명령으로 삭제하는 처리가 필요하다.
|
||||
|
||||
---
|
||||
|
||||
## 2. 롤백과 커밋
|
||||
- 이처럼 몇 단계로 처리를 나누어 SQL 명령을 실행하는 경우에 트랜잭션을 자주 사용한다.
|
||||
- 트랜잭션을 사용해서 데이터를 추가한다면 에러가 발생해도 트랜잭션을 `롤백(rollback)`해서 종료할 수 있다.
|
||||
- 롤백하면 트랜잭션 내에서 행해진 모든 변경사항을 잃었던 것으로 할 수 있다.
|
||||
- 아무런 에러가 발생하지 않는다면 변경사항을 적용하고 트랜잭션을 종료하는데, 이때 `커밋(commit)`을 사용한다.
|
||||
|
||||
##### 트랜잭션을 롤백하면 변경한 내용이 적용되지 않는다!
|
||||
|
||||
### 자동커밋
|
||||
- 트랜잭션을 사용해서 데이터를 추가할 때는 자동커밋을 꺼야 한다.
|
||||
- `mysql` 클라이언트에서 명령을 실행할 때는 자동커밋이 켜져 있는 상태이다.
|
||||
- `INSERT`나 `UPDATE`, `DELETE`가 처리될 때마다 트랜잭션은 암묵적으로 자동커밋 상태로 되어 있다.
|
||||
- 자동커밋을 끄기 위해서는 명시적으로 트랜잭션의 시작을 선언할 필요가 있다.
|
||||
- 트랜잭션을 시작할 때는 `START TRANSACTION` 명령을 사용한다.
|
||||
|
||||
**`트랜잭션 시작`**
|
||||
```
|
||||
START TRANSACTION
|
||||
```
|
||||
|
||||
- 앞서 언급한 것처럼 트랜잭션을 종료하기 위해서는 변경된 내용을 적용한 후에 종료하는 '커밋'과 적용하지 않고 종료하는 '롤백'의 두 가지 방식이 있다.
|
||||
- 커밋할 때에는 `COMMIT` 명령을 사용한다.
|
||||
|
||||
**`트랜잭션 내에서 실행한 명령을 적용한 후 종료`**
|
||||
```
|
||||
COMMIT
|
||||
```
|
||||
|
||||
- 롤백은 `ROLLBACK` 명령을 사용한다.
|
||||
|
||||
**`트랜잭션 내에서 실행한 명령을 파기한 후 종료`**
|
||||
```
|
||||
ROLLBACK
|
||||
```
|
||||
|
||||
- 트랜잭션 내에서 실행된 SQL 명령은 임시 데이터 영역에서 수행되다가, `COMMIT` 명령을 내리면 임시 데이터 영역에서 정식 데이터 영역으로 변경이 적용된다고 생각하면 된다.
|
||||
- `ROLLBACK` 명령을 내리면 임시 데이터 영역에서의 처리는 버려진다.
|
||||
|
||||
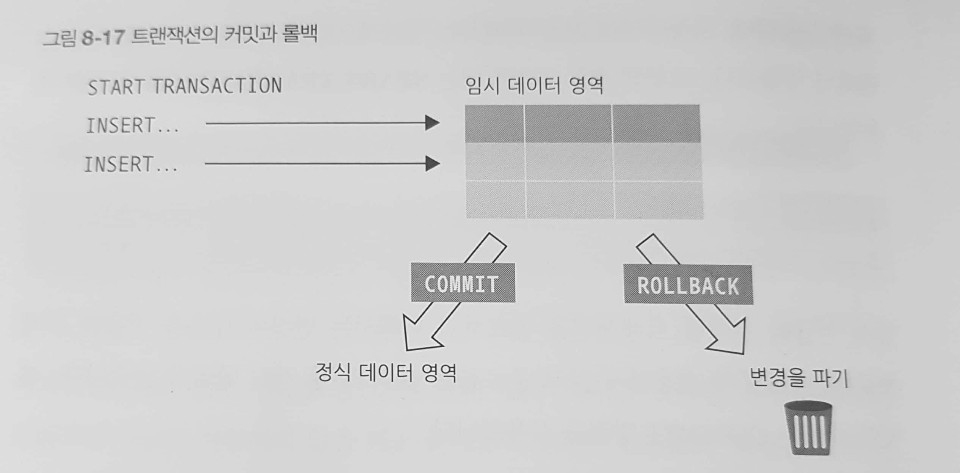
|
||||
|
||||
다음 예제에서는 트랜잭션을 사용해 발주처리를 한다. 에러가 발생하지 않은 경우의 사례로, 트랜잭션은 `COMMIT`을 이용해 종료한다.
|
||||
|
||||
**`트랜잭션 내에서의 발주처리`**
|
||||
```
|
||||
START TRANSACTION;
|
||||
INSERT INTO 주문 VALUES(4, '2014-03-01', 1);
|
||||
INSERT INTO 주문상품 VALUES(4, '0003', 1);
|
||||
INSERT INTO 주문상품 VALUES(4, '0004', 2);
|
||||
COMMIT
|
||||
```
|
||||
|
||||
- 이렇게 트랜잭션을 시작해서 SQL 명령을 실행하고 `COMMIT` 또는 `ROLLBACK` 명령으로 트랜잭션을 종료하는 일련의 처리방법을 '트랜잭션을 걸어서 실행한다' 또는 '트랜잭션 내에서 실행한다'라고 말한다.
|
||||
|
||||
##### 트랜잭션을 사용해서 처리하는 것으로 간단히 데이터를 관리할 수 있다!
|
||||
|
||||
---
|
||||
|
||||
## 3. 트랜잭션 사용법
|
||||
- 발주처리와 같은 데이터 등록처리 과정에서는 대부분 트랜잭션 내에서 여러 개의 SQL 명령을 실행하게 된다.
|
||||
- 다만 하나의 명령에 트랜잭션을 걸어 실행하는 것은 별로 의미가 없다.
|
||||
- 트랜잭션 내에서 실행하는 복수의 SQL 명령은 세트 단위로 유효/무효가 된다.
|
||||
- 다시 말하면, 반드시 세트로 실행하고 싶은 SQL 명령을 트랜잭션에서 하나로 묶어 실행한다는 것이다.
|
||||
- 또 `ROLLBACK`은 에러가 발생한 경우 변경사항이 적용되지 않도록 하는 목적으로 주로 사용하지만, 에러가 발생하지 않아도 `ROLLBACK`을 하면 변경한 내용은 파기된다.
|
||||
- 반대로 에러가 발생하더라도 `COMMIT`을 하면 문제없이 실행된 SQL 명령의 변경사항은 데이터베이스에 그대로 반영된다.
|
||||
|
||||
##### 세트로 실행하고 싶은 SQL 명령은 트랜잭션 내에서 실행한다!
|
||||
|
||||
- 트랜잭션을 시작할 때 사용하는 명령은 `START TRANSACTION`이라고 설명했지만 이것은 `MySQL`의 경우에 적용된다.
|
||||
- `MySQL`에서는 `START TRANSACTION` 외에도 `BEGIN`을 사용할 수 있다.
|
||||
- `SQL Server`나 `PostgreSQL`에서는 `BEGIN TRANSACTION` 명령을 사용한다.
|
||||
- `Oracle`이나 `DB2`에서 트랜잭션을 시작하는 명령은 따로 없다. 이 또한 표준화가 진행되지 못한 부분이다.
|
||||
- 자동커밋은 클라이언트 툴의 기능이다.
|
||||
- 미들웨어도 데이터베이스 접속 시 대개 자동커밋을 한다.
|
||||
- 한편, 데이터베이스 서버에서는 언제나 트랜잭션을 걸 수 있는 상태로 SQL 명령이 실행된다.
|
||||
- 트랜잭션을 사용할 경우에는 접속형태나 클라이언트 툴의 자동커밋 사용 여부 등, 트랜잭션 관련 기능을 파악해 둘 필요가 있다.
|
||||
- `DELETE` 명령은 삭제 여부에 관해 사용자에게 확인하지 않는다고 설명했다.
|
||||
- 불친절한 시스템이라고 생각할 수도 있으나, `DELETE` 명령을 트랜잭션 내에서 실행하는 경우에는 `ROLLBACK`으로 삭제를 취소할 수 있다.
|
||||
- 단, 자동커밋으로 되어있는 경우에는 주의해야 한다. `ROLLBACK`으로 취소할 수 있는 것은 트랜잭션 내에서 실행했을 경우에 한해서이다.
|
||||
|
||||
---
|
||||
BIN
도서/SQL첫걸음/images/05강 DESC 명령.PNG
Normal file
{kind=link}
|
After Width: | Height: | Size: 22 KiB |
BIN
도서/SQL첫걸음/images/28강 이진 트리.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 21 KiB |
BIN
도서/SQL첫걸음/images/29강 EXPLAIN으로 인덱스 사용 확인.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 14 KiB |
BIN
도서/SQL첫걸음/images/29강 EXPLAIN으로 인덱스 사용불가 확인.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 14 KiB |
BIN
도서/SQL첫걸음/images/29강 예 또는 아니오로 구성된 이진 트리.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 32 KiB |
BIN
도서/SQL첫걸음/images/34강 ER다이어그램의 개체와 연관.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 5.8 KiB |
BIN
도서/SQL첫걸음/images/35강 간단한 주문 데이터.PNG
Normal file
{kind=link}
|
After Width: | Height: | Size: 64 KiB |
BIN
도서/SQL첫걸음/images/35강 정규화 후의 테이블.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 78 KiB |
BIN
도서/SQL첫걸음/images/35강 정규화 후의 테이블을 ER다이어그램으로 표기.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 23 KiB |
BIN
도서/SQL첫걸음/images/35강 주문 데이터를 주문 테이블과 주문상품 테이블로 분할.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 107 KiB |
BIN
도서/SQL첫걸음/images/35강 주문 테이블을 분할.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 32 KiB |
BIN
도서/SQL첫걸음/images/35강 주문상품 데이터를 상품코드, 상품명, 개수로 분할하기.PNG
Normal file
{kind=link}
|
After Width: | Height: | Size: 105 KiB |
BIN
도서/SQL첫걸음/images/35강 주문상품 테이블을 분할.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 44 KiB |
BIN
도서/SQL첫걸음/images/36강 주문 테이블과 주문상품 테이블.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 39 KiB |
BIN
도서/SQL첫걸음/images/36강 트랜잭션.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 48 KiB |
BIN
도서/SQL첫걸음/images/36강 트랜잭션의 커밋과 롤백.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 41 KiB |
165
도서/모던 자바 인 액션 (Modern Java In Action)/.gitignore
vendored
Normal file
@@ -0,0 +1,165 @@
|
||||
|
||||
# Created by https://www.toptal.com/developers/gitignore/api/windows,intellij,java
|
||||
# Edit at https://www.toptal.com/developers/gitignore?templates=windows,intellij,java
|
||||
|
||||
### Intellij ###
|
||||
# Covers JetBrains IDEs: IntelliJ, RubyMine, PhpStorm, AppCode, PyCharm, CLion, Android Studio, WebStorm and Rider
|
||||
# Reference: https://intellij-support.jetbrains.com/hc/en-us/articles/206544839
|
||||
|
||||
# User-specific stuff
|
||||
.idea/**/workspace.xml
|
||||
.idea/**/tasks.xml
|
||||
.idea/**/usage.statistics.xml
|
||||
.idea/**/dictionaries
|
||||
.idea/**/shelf
|
||||
|
||||
# Generated files
|
||||
.idea/**/contentModel.xml
|
||||
|
||||
# Sensitive or high-churn files
|
||||
.idea/**/dataSources/
|
||||
.idea/**/dataSources.ids
|
||||
.idea/**/dataSources.local.xml
|
||||
.idea/**/sqlDataSources.xml
|
||||
.idea/**/dynamic.xml
|
||||
.idea/**/uiDesigner.xml
|
||||
.idea/**/dbnavigator.xml
|
||||
|
||||
# Gradle
|
||||
.idea/**/gradle.xml
|
||||
.idea/**/libraries
|
||||
|
||||
# Gradle and Maven with auto-import
|
||||
# When using Gradle or Maven with auto-import, you should exclude module files,
|
||||
# since they will be recreated, and may cause churn. Uncomment if using
|
||||
# auto-import.
|
||||
# .idea/artifacts
|
||||
# .idea/compiler.xml
|
||||
# .idea/jarRepositories.xml
|
||||
# .idea/modules.xml
|
||||
# .idea/*.iml
|
||||
# .idea/modules
|
||||
# *.iml
|
||||
# *.ipr
|
||||
|
||||
# CMake
|
||||
cmake-build-*/
|
||||
|
||||
# Mongo Explorer plugin
|
||||
.idea/**/mongoSettings.xml
|
||||
|
||||
# File-based project format
|
||||
*.iws
|
||||
|
||||
# IntelliJ
|
||||
out/
|
||||
|
||||
# mpeltonen/sbt-idea plugin
|
||||
.idea_modules/
|
||||
|
||||
# JIRA plugin
|
||||
atlassian-ide-plugin.xml
|
||||
|
||||
# Cursive Clojure plugin
|
||||
.idea/replstate.xml
|
||||
|
||||
# Crashlytics plugin (for Android Studio and IntelliJ)
|
||||
com_crashlytics_export_strings.xml
|
||||
crashlytics.properties
|
||||
crashlytics-build.properties
|
||||
fabric.properties
|
||||
|
||||
# Editor-based Rest Client
|
||||
.idea/httpRequests
|
||||
|
||||
# Android studio 3.1+ serialized cache file
|
||||
.idea/caches/build_file_checksums.ser
|
||||
|
||||
### Intellij Patch ###
|
||||
# Comment Reason: https://github.com/joeblau/gitignore.io/issues/186#issuecomment-215987721
|
||||
|
||||
# *.iml
|
||||
# modules.xml
|
||||
# .idea/misc.xml
|
||||
# *.ipr
|
||||
|
||||
# Sonarlint plugin
|
||||
# https://plugins.jetbrains.com/plugin/7973-sonarlint
|
||||
.idea/**/sonarlint/
|
||||
|
||||
# SonarQube Plugin
|
||||
# https://plugins.jetbrains.com/plugin/7238-sonarqube-community-plugin
|
||||
.idea/**/sonarIssues.xml
|
||||
|
||||
# Markdown Navigator plugin
|
||||
# https://plugins.jetbrains.com/plugin/7896-markdown-navigator-enhanced
|
||||
.idea/**/markdown-navigator.xml
|
||||
.idea/**/markdown-navigator-enh.xml
|
||||
.idea/**/markdown-navigator/
|
||||
|
||||
# Cache file creation bug
|
||||
# See https://youtrack.jetbrains.com/issue/JBR-2257
|
||||
.idea/$CACHE_FILE$
|
||||
|
||||
# CodeStream plugin
|
||||
# https://plugins.jetbrains.com/plugin/12206-codestream
|
||||
.idea/codestream.xml
|
||||
|
||||
### Java ###
|
||||
# Compiled class file
|
||||
*.class
|
||||
|
||||
# Log file
|
||||
*.log
|
||||
|
||||
# BlueJ files
|
||||
*.ctxt
|
||||
|
||||
# Mobile Tools for Java (J2ME)
|
||||
.mtj.tmp/
|
||||
|
||||
# Package Files #
|
||||
*.jar
|
||||
*.war
|
||||
*.nar
|
||||
*.ear
|
||||
*.zip
|
||||
*.tar.gz
|
||||
*.rar
|
||||
|
||||
# virtual machine crash logs, see http://www.java.com/en/download/help/error_hotspot.xml
|
||||
hs_err_pid*
|
||||
|
||||
### Windows ###
|
||||
# Windows thumbnail cache files
|
||||
Thumbs.db
|
||||
Thumbs.db:encryptable
|
||||
ehthumbs.db
|
||||
ehthumbs_vista.db
|
||||
|
||||
# Dump file
|
||||
*.stackdump
|
||||
|
||||
# Folder config file
|
||||
[Dd]esktop.ini
|
||||
|
||||
# Recycle Bin used on file shares
|
||||
$RECYCLE.BIN/
|
||||
|
||||
# Windows Installer files
|
||||
*.cab
|
||||
*.msi
|
||||
*.msix
|
||||
*.msm
|
||||
*.msp
|
||||
|
||||
# Windows shortcuts
|
||||
*.lnk
|
||||
|
||||
# End of https://www.toptal.com/developers/gitignore/api/windows,intellij,java
|
||||
Modern-Java-In-Action.iml
|
||||
.idea/.gitignore
|
||||
.idea/compiler.xml
|
||||
.idea/misc.xml
|
||||
.idea/modules.xml
|
||||
.idea/vcs.xml
|
||||
@@ -0,0 +1,28 @@
|
||||
# Contents
|
||||
|
||||
### Part1. 기초
|
||||
- [Chapter1. 자바 8, 9, 10, 11 : 무슨 일이 일어나고 있는가?]()
|
||||
- [Chapter2. 동작 파라미터화 코드 전달하기]()
|
||||
- [Chapter3. 람다 표현식](https://github.com/banjjoknim/TIL/blob/master/%EB%AA%A8%EB%8D%98%20%EC%9E%90%EB%B0%94%20%EC%9D%B8%20%EC%95%A1%EC%85%98%20(Modern%20Java%20In%20Action)/src/Part1/Chapter3/Chapter3.md)
|
||||
|
||||
### Part2. 함수형 데이터 처리
|
||||
- [Chapter4. 스트림 소개](https://github.com/banjjoknim/TIL/blob/master/%EB%AA%A8%EB%8D%98%20%EC%9E%90%EB%B0%94%20%EC%9D%B8%20%EC%95%A1%EC%85%98%20(Modern%20Java%20In%20Action)/src/Chapter4/Chapter4.md)
|
||||
- [Chapter5. 스트림 활용](https://github.com/banjjoknim/TIL/blob/master/%EB%AA%A8%EB%8D%98%20%EC%9E%90%EB%B0%94%20%EC%9D%B8%20%EC%95%A1%EC%85%98%20(Modern%20Java%20In%20Action)/src/Chapter5/Chapter5.md)
|
||||
- [Chapter6. 스트림으로 데이터 수집](https://github.com/banjjoknim/TIL/blob/master/%EB%AA%A8%EB%8D%98%20%EC%9E%90%EB%B0%94%20%EC%9D%B8%20%EC%95%A1%EC%85%98%20(Modern%20Java%20In%20Action)/src/Chapter6/Chapter6.md)
|
||||
- [Chapter7. 병렬 데이터 처리와 성능](https://github.com/banjjoknim/TIL/blob/master/%EB%AA%A8%EB%8D%98%20%EC%9E%90%EB%B0%94%20%EC%9D%B8%20%EC%95%A1%EC%85%98%20(Modern%20Java%20In%20Action)/src/Chapter7/Chapter7.md)
|
||||
|
||||
### Part3. 스트림과 람다를 이용한 효과적 프로그래밍
|
||||
- [Chapter8. 컬렉션 API 개선](https://github.com/banjjoknim/TIL/blob/master/%EB%AA%A8%EB%8D%98%20%EC%9E%90%EB%B0%94%20%EC%9D%B8%20%EC%95%A1%EC%85%98%20(Modern%20Java%20In%20Action)/src/Chapter8/Chapter8.md)
|
||||
- [Chapter9. 리팩터링, 테스팅, 디버깅](https://github.com/banjjoknim/TIL/blob/master/%EB%AA%A8%EB%8D%98%20%EC%9E%90%EB%B0%94%20%EC%9D%B8%20%EC%95%A1%EC%85%98%20(Modern%20Java%20In%20Action)/src/Chapter9/Chapter9.md)
|
||||
- [Chapter10. 람다를 이용한 도메인 전용 언어](https://github.com/banjjoknim/TIL/blob/master/%EB%AA%A8%EB%8D%98%20%EC%9E%90%EB%B0%94%20%EC%9D%B8%20%EC%95%A1%EC%85%98%20(Modern%20Java%20In%20Action)/src/Chapter10/Chapter10.md)
|
||||
|
||||
### Part4. 매일 자바와 함께
|
||||
- [Chapter11. null 대신 Optional 클래스](https://github.com/banjjoknim/TIL/blob/master/%EB%AA%A8%EB%8D%98%20%EC%9E%90%EB%B0%94%20%EC%9D%B8%20%EC%95%A1%EC%85%98%20(Modern%20Java%20In%20Action)/src/Chapter11/Chapter11.md)
|
||||
- [Chapter12. 새로운 날짜와 시간 API](https://github.com/banjjoknim/TIL/blob/master/%EB%AA%A8%EB%8D%98%20%EC%9E%90%EB%B0%94%20%EC%9D%B8%20%EC%95%A1%EC%85%98%20(Modern%20Java%20In%20Action)/src/Chapter12/Chapter12.md)
|
||||
- [Chapter13. 디폴트 메서드](https://github.com/banjjoknim/TIL/blob/master/%EB%AA%A8%EB%8D%98%20%EC%9E%90%EB%B0%94%20%EC%9D%B8%20%EC%95%A1%EC%85%98%20(Modern%20Java%20In%20Action)/src/Chapter13/Chapter13.md)
|
||||
- [Chapter14. 자바 모듈 시스템](https://github.com/banjjoknim/TIL/blob/master/%EB%AA%A8%EB%8D%98%20%EC%9E%90%EB%B0%94%20%EC%9D%B8%20%EC%95%A1%EC%85%98%20(Modern%20Java%20In%20Action)/src/Chapter14/Chapter14.md)
|
||||
|
||||
### Part5. 개선된 자바 동시성
|
||||
- [Chapter15. CompletableFuture와 리액티브 프로그래밍 컨셉의 기초](https://github.com/banjjoknim/TIL/blob/master/%EB%AA%A8%EB%8D%98%20%EC%9E%90%EB%B0%94%20%EC%9D%B8%20%EC%95%A1%EC%85%98%20(Modern%20Java%20In%20Action)/src/Chapter15/Chapter15.md)
|
||||
- [Chapter16. CompletableFuture : 안정적 비동기 프로그래밍](https://github.com/banjjoknim/TIL/blob/master/%EB%AA%A8%EB%8D%98%20%EC%9E%90%EB%B0%94%20%EC%9D%B8%20%EC%95%A1%EC%85%98%20(Modern%20Java%20In%20Action)/src/Chapter16/Chapter16.md)
|
||||
|
||||
@@ -0,0 +1,30 @@
|
||||
package Chapter10;
|
||||
|
||||
import java.util.HashMap;
|
||||
import java.util.Map;
|
||||
|
||||
public class BuyStocksSteps {
|
||||
private Map<String, Integer> stockUnitPrices = new HashMap<>();
|
||||
private Order order = new Order();
|
||||
|
||||
public void setUnitPrice(String stockName, int unitPrice) {
|
||||
stockUnitPrices.put(stockName, unitPrice);
|
||||
}
|
||||
|
||||
public void buyStocks(int quantity, String stockName) {
|
||||
Trade trade = new Trade();
|
||||
trade.setType(Trade.Type.BUY);
|
||||
|
||||
Stock stock = new Stock();
|
||||
stock.setSymbol(stockName);
|
||||
|
||||
trade.setStock(stock);
|
||||
trade.setPrice(stockUnitPrices.get(stockName));
|
||||
trade.setQuantity(quantity);
|
||||
order.addTrade(trade);
|
||||
}
|
||||
|
||||
public void checkOrderValue(int expectedValue) {
|
||||
// assertEquals(expectedValue, order.getValue());
|
||||
}
|
||||
}
|
||||
1222
도서/모던 자바 인 액션 (Modern Java In Action)/src/Chapter10/Chapter10.md
Normal file
@@ -0,0 +1,28 @@
|
||||
package Chapter10;
|
||||
|
||||
import java.util.List;
|
||||
import java.util.Map;
|
||||
import java.util.function.Function;
|
||||
import java.util.stream.Collector;
|
||||
|
||||
import static java.util.stream.Collectors.groupingBy;
|
||||
|
||||
public class GroupingBuilder<T, D, K> {
|
||||
private final Collector<? super T, ?, Map<K, D>> collector;
|
||||
|
||||
public GroupingBuilder(Collector<? super T, ?, Map<K, D>> collector) {
|
||||
this.collector = collector;
|
||||
}
|
||||
|
||||
public Collector<? super T, ?, Map<K, D>> get() {
|
||||
return collector;
|
||||
}
|
||||
|
||||
public <J> GroupingBuilder<T, Map<K, D>, J> after(Function<? super T, ? extends J> classifier) {
|
||||
return new GroupingBuilder<T, Map<K, D>, J>(groupingBy(classifier, collector));
|
||||
}
|
||||
|
||||
public static <T, D, K> GroupingBuilder<T, List<T>, K> groupOn(Function<? super T, ? extends K> classifier) {
|
||||
return new GroupingBuilder<T, List<T>, K>(groupingBy(classifier));
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,33 @@
|
||||
package Chapter10;
|
||||
|
||||
import java.util.function.Consumer;
|
||||
|
||||
public class LambdaOrderBuilder {
|
||||
|
||||
private Order order = new Order();
|
||||
|
||||
public static Order order(Consumer<LambdaOrderBuilder> consumer) {
|
||||
LambdaOrderBuilder builder = new LambdaOrderBuilder();
|
||||
consumer.accept(builder);
|
||||
return builder.order;
|
||||
}
|
||||
|
||||
public void forCustomer(String customer) {
|
||||
order.setCustomer(customer);
|
||||
}
|
||||
|
||||
public void buy(Consumer<TradeBuilder> consumer) {
|
||||
trade(consumer, Trade.Type.BUY);
|
||||
}
|
||||
|
||||
public void sell(Consumer<TradeBuilder> consumer) {
|
||||
trade(consumer, Trade.Type.SELL);
|
||||
}
|
||||
|
||||
private void trade(Consumer<TradeBuilder> consumer, Trade.Type type) {
|
||||
TradeBuilder builder = new TradeBuilder();
|
||||
builder.trade.setType(type);
|
||||
consumer.accept(builder);
|
||||
order.addTrade(builder.trade);
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,31 @@
|
||||
package Chapter10;
|
||||
|
||||
public class MethodChainingOrderBuilder {
|
||||
|
||||
public final Order order = new Order();
|
||||
|
||||
private MethodChainingOrderBuilder(String customer) {
|
||||
order.setCustomer(customer);
|
||||
}
|
||||
|
||||
public static MethodChainingOrderBuilder forCustomer(String customer) {
|
||||
return new MethodChainingOrderBuilder(customer);
|
||||
}
|
||||
|
||||
// public TradeBuilder buy(int quantity) {
|
||||
// return new TradeBuilder(this, Trade.Type.BUY, quantity); // 주식을 파는 TradeBuilder 만들기
|
||||
// }
|
||||
//
|
||||
// public TradeBuilder sell(int quantity) {
|
||||
// return new TradeBuilder(this, Trade.Type.SELL, quantity);
|
||||
// }
|
||||
|
||||
public MethodChainingOrderBuilder addTrade(Trade trade) {
|
||||
order.addTrade(trade);
|
||||
return this;
|
||||
}
|
||||
|
||||
public Order end() {
|
||||
return order;
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,29 @@
|
||||
package Chapter10;
|
||||
|
||||
import java.util.function.Consumer;
|
||||
import java.util.stream.Stream;
|
||||
|
||||
public class MixedBuilder {
|
||||
|
||||
public static Order forCustomer(String customer, TradeBuilder... tradeBuilders) {
|
||||
Order order = new Order();
|
||||
order.setCustomer(customer);
|
||||
Stream.of(tradeBuilders).forEach(b -> order.addTrade(b.trade));
|
||||
return order;
|
||||
}
|
||||
|
||||
public static TradeBuilder buy(Consumer<TradeBuilder> consumer) {
|
||||
return buildTrade(consumer, Trade.Type.BUY);
|
||||
}
|
||||
|
||||
public static TradeBuilder sell(Consumer<TradeBuilder> consumer) {
|
||||
return buildTrade(consumer, Trade.Type.SELL);
|
||||
}
|
||||
|
||||
private static TradeBuilder buildTrade(Consumer<TradeBuilder> consumer, Trade.Type buy) {
|
||||
TradeBuilder builder = new TradeBuilder();
|
||||
builder.trade.setType(buy);
|
||||
consumer.accept(builder);
|
||||
return builder;
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,45 @@
|
||||
package Chapter10;
|
||||
|
||||
import java.util.stream.Stream;
|
||||
|
||||
public class NestedFunctionOrderBuilder {
|
||||
|
||||
public static Order order(String customer, Trade... trades) {
|
||||
Order order = new Order();
|
||||
order.setCustomer(customer);
|
||||
Stream.of(trades).forEach(order::addTrade);
|
||||
return order;
|
||||
}
|
||||
|
||||
public static Trade buy(int quantity, Stock stock, double price) {
|
||||
return buildTrade(quantity, stock, price, Trade.Type.BUY);
|
||||
}
|
||||
|
||||
public static Trade sell(int quantity, Stock stock, double price) {
|
||||
return buildTrade(quantity, stock, price, Trade.Type.SELL);
|
||||
}
|
||||
|
||||
private static Trade buildTrade(int quantity, Stock stock, double price, Trade.Type buy) {
|
||||
Trade trade = new Trade();
|
||||
trade.setQuantity(quantity);
|
||||
trade.setType(buy);
|
||||
trade.setStock(stock);
|
||||
trade.setPrice(price);
|
||||
return trade;
|
||||
}
|
||||
|
||||
public static double at(double price) {
|
||||
return price;
|
||||
}
|
||||
|
||||
public static Stock stock(String symbol, String market) {
|
||||
Stock stock = new Stock();
|
||||
stock.setSymbol(symbol);
|
||||
stock.setMarket(market);
|
||||
return stock;
|
||||
}
|
||||
|
||||
public static String on(String market) {
|
||||
return market;
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,57 @@
|
||||
package Chapter10;
|
||||
|
||||
import java.util.ArrayList;
|
||||
import java.util.List;
|
||||
|
||||
public class Order {
|
||||
|
||||
private String customer;
|
||||
private List<Trade> trades = new ArrayList<>();
|
||||
|
||||
public void addTrade(Trade trade) {
|
||||
trades.add(trade);
|
||||
}
|
||||
|
||||
public String getCustomer() {
|
||||
return customer;
|
||||
}
|
||||
|
||||
public void setCustomer(String customer) {
|
||||
this.customer = customer;
|
||||
}
|
||||
|
||||
public double getValue() {
|
||||
return trades.stream()
|
||||
.mapToDouble(Trade::getValue)
|
||||
.sum();
|
||||
}
|
||||
|
||||
public static void main(String[] args) {
|
||||
Order order = new Order();
|
||||
order.setCustomer("BigBank");
|
||||
|
||||
Trade trade1 = new Trade();
|
||||
trade1.setType(Trade.Type.BUY);
|
||||
|
||||
Stock stock1 = new Stock();
|
||||
stock1.setSymbol("IBM");
|
||||
stock1.setMarket("NYSE");
|
||||
|
||||
trade1.setStock(stock1);
|
||||
trade1.setPrice(125.00);
|
||||
trade1.setQuantity(80);
|
||||
order.addTrade(trade1);
|
||||
|
||||
Trade trade2 = new Trade();
|
||||
trade1.setType(Trade.Type.BUY);
|
||||
|
||||
Stock stock2 = new Stock();
|
||||
stock1.setSymbol("GOOGLE");
|
||||
stock1.setMarket("NASDAQ");
|
||||
|
||||
trade1.setStock(stock2);
|
||||
trade1.setPrice(375.00);
|
||||
trade1.setQuantity(50);
|
||||
order.addTrade(trade2);
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,19 @@
|
||||
package Chapter10;
|
||||
|
||||
public class Person {
|
||||
private final String name;
|
||||
private final int age;
|
||||
|
||||
public Person(String name, int age) {
|
||||
this.name = name;
|
||||
this.age = age;
|
||||
}
|
||||
|
||||
public String getName() {
|
||||
return name;
|
||||
}
|
||||
|
||||
public int getAge() {
|
||||
return age;
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,23 @@
|
||||
package Chapter10;
|
||||
|
||||
public class Stock {
|
||||
|
||||
private String symbol;
|
||||
private String market;
|
||||
|
||||
public String getSymbol() {
|
||||
return symbol;
|
||||
}
|
||||
|
||||
public String getMarket() {
|
||||
return market;
|
||||
}
|
||||
|
||||
public void setSymbol(String symbol) {
|
||||
this.symbol = symbol;
|
||||
}
|
||||
|
||||
public void setMarket(String market) {
|
||||
this.market = market;
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,13 @@
|
||||
package Chapter10;
|
||||
|
||||
public class StockBuilder {
|
||||
public Stock stock = new Stock();
|
||||
|
||||
public void symbol(String symbol) {
|
||||
stock.setSymbol(symbol);
|
||||
}
|
||||
|
||||
public void market(String market) {
|
||||
stock.setMarket(market);
|
||||
}
|
||||
}
|
||||
29
도서/모던 자바 인 액션 (Modern Java In Action)/src/Chapter10/Tax.java
Normal file
@@ -0,0 +1,29 @@
|
||||
package Chapter10;
|
||||
|
||||
public class Tax {
|
||||
public static double regional(double value) {
|
||||
return value * 1;
|
||||
}
|
||||
|
||||
public static double general(double value) {
|
||||
return value * 1.3;
|
||||
}
|
||||
|
||||
public static double surcharge(double value) {
|
||||
return value * 1.05;
|
||||
}
|
||||
|
||||
public static double calculate(Order order, boolean useRegional, boolean useGeneral, boolean useSurcharge) {
|
||||
double value = order.getValue();
|
||||
if (useRegional) {
|
||||
value = Tax.regional(value);
|
||||
}
|
||||
if (useGeneral) {
|
||||
value = Tax.general(value);
|
||||
}
|
||||
if (useSurcharge) {
|
||||
value = Tax.surcharge(value);
|
||||
}
|
||||
return value;
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,25 @@
|
||||
package Chapter10;
|
||||
|
||||
import java.util.function.DoubleUnaryOperator;
|
||||
|
||||
public class TaxCalculator {
|
||||
public DoubleUnaryOperator taxFunction = d -> d;
|
||||
|
||||
public TaxCalculator with(DoubleUnaryOperator f) {
|
||||
taxFunction = taxFunction.andThen(f);
|
||||
return this;
|
||||
}
|
||||
|
||||
public double calculate(Order order) {
|
||||
return taxFunction.applyAsDouble(order.getValue());
|
||||
}
|
||||
|
||||
public static void main(String[] args) {
|
||||
Order order = new Order();
|
||||
double value = new TaxCalculator()
|
||||
.with(Tax::regional)
|
||||
.with(Tax::surcharge)
|
||||
.calculate(order);
|
||||
System.out.println(value);
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,46 @@
|
||||
package Chapter10;
|
||||
|
||||
public class Trade {
|
||||
public enum Type {BUY, SELL}
|
||||
|
||||
private Type type;
|
||||
private Stock stock;
|
||||
private int quantity;
|
||||
private double price;
|
||||
|
||||
public Type getType() {
|
||||
return type;
|
||||
}
|
||||
|
||||
public Stock getStock() {
|
||||
return stock;
|
||||
}
|
||||
|
||||
public int getQuantity() {
|
||||
return quantity;
|
||||
}
|
||||
|
||||
public double getPrice() {
|
||||
return price;
|
||||
}
|
||||
|
||||
public void setType(Type type) {
|
||||
this.type = type;
|
||||
}
|
||||
|
||||
public void setStock(Stock stock) {
|
||||
this.stock = stock;
|
||||
}
|
||||
|
||||
public void setQuantity(int quantity) {
|
||||
this.quantity = quantity;
|
||||
}
|
||||
|
||||
public void setPrice(double price) {
|
||||
this.price = price;
|
||||
}
|
||||
|
||||
public double getValue() {
|
||||
return quantity * price;
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,21 @@
|
||||
package Chapter10;
|
||||
|
||||
import java.util.function.Consumer;
|
||||
|
||||
public class TradeBuilder {
|
||||
public Trade trade = new Trade();
|
||||
|
||||
public void quantity(int quantity) {
|
||||
trade.setQuantity(quantity);
|
||||
}
|
||||
|
||||
public void price(double price) {
|
||||
trade.setPrice(price);
|
||||
}
|
||||
|
||||
public void stock(Consumer<StockBuilder> consumer) {
|
||||
StockBuilder builder = new StockBuilder();
|
||||
consumer.accept(builder);
|
||||
trade.setStock(builder.stock);
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,16 @@
|
||||
package Chapter10;
|
||||
|
||||
public class TradeBuilderWithStock {
|
||||
private final MethodChainingOrderBuilder builder;
|
||||
private final Trade trade;
|
||||
|
||||
public TradeBuilderWithStock(MethodChainingOrderBuilder builder, Trade trade) {
|
||||
this.builder = builder;
|
||||
this.trade = trade;
|
||||
}
|
||||
|
||||
public MethodChainingOrderBuilder at(double price) {
|
||||
trade.setPrice(price);
|
||||
return builder.addTrade(trade);
|
||||
}
|
||||
}
|
||||
11
도서/모던 자바 인 액션 (Modern Java In Action)/src/Chapter11/Car.java
Normal file
@@ -0,0 +1,11 @@
|
||||
package Chapter11;
|
||||
|
||||
import java.util.Optional;
|
||||
|
||||
public class Car {
|
||||
private Optional<Insurance> insurance;
|
||||
|
||||
public Optional<Insurance> getInsurance() {
|
||||
return insurance;
|
||||
}
|
||||
}
|
||||
516
도서/모던 자바 인 액션 (Modern Java In Action)/src/Chapter11/Chapter11.md
Normal file
@@ -0,0 +1,516 @@
|
||||
# Chapter11. null 대신 Optional 클래스
|
||||
- 1965년 `토니 호어(Tony Hoare)`라는 영국 컴퓨터과학자가 힙에 할당되는 레코드를 사용하며 형식을 갖는 최초의 프로그래밍 언어 중 하나인 `알골(ALGOL W)`을 설계하면서 처음 `null` 참조가 등장했다.
|
||||
- 그 당시에는 `null` 참조 및 예외로 값이 없는 상황을 가장 단순하게 구현할 수 있다고 판단했고 결과적으로 `null` 및 관련 예외가 탄생했다.
|
||||
|
||||
## 11.1 값이 없는 상황을 어떻게 처리할까?
|
||||
다음처럼 자동차와 자동차 보험을 갖고 있는 사람 객체를 중첩 구조로 구현했다고 하자.
|
||||
|
||||
###### 예제 11-1. Person/Car/Insurance 데이터 모델
|
||||
```java
|
||||
public class Person {
|
||||
private Car car;
|
||||
|
||||
public Car getCar() {
|
||||
return car;
|
||||
}
|
||||
}
|
||||
|
||||
public class Car {
|
||||
private Insurance insurance;
|
||||
|
||||
public Insurance getInsurance() {
|
||||
return insurance;
|
||||
}
|
||||
}
|
||||
|
||||
public class Insurance {
|
||||
private String name;
|
||||
|
||||
public String getName() {
|
||||
return name;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
다음 코드에서는 어떤 문제가 발생할까?
|
||||
|
||||
```java
|
||||
public String getCarInsuranceName(Person person) {
|
||||
return person.getCar().getInsurance().getName();
|
||||
}
|
||||
```
|
||||
|
||||
코드에는 아무 문제가 없는 것처럼 보이지만 차를 소유하지 않은 사람도 많다. 이때 `getCar`를 호출하면 `null` 참조를 반환하는 방식으로 자동차를 소유하고 있지 않음을 표현할 것이다. 그러면 `getInsurance`는 `null` 참조의 보험 정보를 반환하려 할 것이므로 런타임에 `NullPointerException`이 발생하면서 프로그램 실행이 중단된다. 또 다른 문제도 있다. 만약 `Person`이 `null`이라면 어떻게 될까? 아니면 `getInsurance`가 `null`을 반환한다면 어떻게 될까?
|
||||
|
||||
### 11.1.1 보수적인 자세로 NullPointerException 줄이기
|
||||
예기치 않은 `NullPointerException`을 피하려면 어떻게 해야 할까? 다음은 `null` 확인 코드를 추가해서 `NullPointerException`을 줄이려는 코드다.
|
||||
|
||||
###### 예제 11-2 null 안전 시도 1: 깊은 의심
|
||||
```java
|
||||
public String getCarInsuranceName(Person person) {
|
||||
if (person != null) { // null 확인 코드
|
||||
Car car = person.getCar();
|
||||
if (car != null) { // null 확인 코드
|
||||
Insurance insurance = car.getInsurance();
|
||||
if(insurance != null) { // null 확인 코드
|
||||
return insurance.getName();
|
||||
}
|
||||
}
|
||||
}
|
||||
return "Unknown";
|
||||
}
|
||||
```
|
||||
|
||||
위 코드에서는 변수를 참조할 때마다 `null`을 확인하며 중간 과정에 하나라도 `null` 참조가 있으면 `Unknown`이라는 문자열을 반환한다.
|
||||
|
||||
`예제 11-2`의 메서드에서는 모든 변수가 `null`인지 의심하므로 변수를 접근할 때마다 중첩된 `if`가 추가되면서 코드 들여쓰기 수준이 증가한다. 따라서 이와 같은 `반복 패턴(recurring pattern)` 코드를 `깊은 의심(deep doubt)`이라고 부른다. 즉, 변수가 `null`인지 의심되어 중첩 `if` 블록을 추가하면 코드 들여쓰기 수준이 증가한다. 이를 반복하다보면 코드의 구조가 엉망이 되고 가독성도 떨어진다. 따라서 뭔가 다른 해결 방법이 필요하다. 다음 예제는 다른 방법으로 이 문제를 해결하는 코드다.
|
||||
|
||||
###### 예제 11-3. null 안전 시도 2: 너무 많은 출구
|
||||
```java
|
||||
public String getCarInsuranceName(Person person) {
|
||||
if (person == null) {
|
||||
return "Unknown";
|
||||
}
|
||||
Car car = person.getCar();
|
||||
if (car == null) {
|
||||
return "Unknown";
|
||||
}
|
||||
Insurance insurance = car.getInsurance();
|
||||
if (insurance == null) {
|
||||
return "Unknown";
|
||||
}
|
||||
return insurance.getName();
|
||||
}
|
||||
```
|
||||
|
||||
위 코드는 조금 다른 방법으로 중첨 `if` 블록을 없앴다. 즉, `null` 변수가 있으면 즉시 `Unknown`을 반환한다. 하지만 이 예제도 그렇게 좋은 코드는 아니다. 메서드에 네 개의 출구가 생겼기 때문이다. 출구 때문에 유지보수가 어려워진다. 게다가 `null`일 때 반환되는 기본값 `Unknown`이 세 곳에서 반복되고 있는데 같은 문자열을 반복하면서 오타 등의 실수가 생길 수 있다. 물론 `Unknown`이라는 문자열을 상수로 만들어서 이 문제를 해결할 수 있다.
|
||||
|
||||
앞의 코드는 쉽게 에러를 일으킬 수 있다. 만약 누군가가 `null`일 수 있다는 사실을 깜빡 잊었다면 어떤 일이 일어날까?
|
||||
|
||||
### 11.1.2 null 때문에 발생하는 문제
|
||||
자바에서 `null` 참조를 사용하면서 발생할 수 있는 이론적, 실용적 문제를 확인하자.
|
||||
|
||||
- **에러의 근원이다** : `NullPointerException`은 자바에서 가장 흔히 발생하는 에러다.
|
||||
- **코드를 어지럽힌다** : 때로는 중첩된 `null` 확인 코드를 추가해야 하므로 `null` 때문에 코드 가독성이 떨어진다.
|
||||
- **아무 의미가 없다** : `null`은 아무 의미도 표현하지 않는다. 특히 정적 형식 언어에서 값이 없음을 표현하는 방법으로는 적절하지 않다.
|
||||
- **자바 철학에 위배된다** : 자바는 개발자로부터 모든 포인터를 숨겼다. 하지만 예외가 있는데 그것이 바로 `null` 포인터다.
|
||||
- **형식 시스템에 구멍을 만든다** : `null`은 무형식이며 정보를 포함하고 있지 않으므로 모든 참조 형식에 `null`을 할당할 수 있다. 이런 식으로 `null`이 할당되기 시작하면서 시스템의 다른 부분으로 `null`이 퍼졌을 때 애초에 `null`이 어떤 의미로 사용되었는지 알 수 없다.
|
||||
|
||||
다른 프로그래밍 언어에서는 `null` 참조를 어떻게 해결하는지 살펴보면서 `null` 참조 문제 해결방법의 실마리를 찾아보자.
|
||||
|
||||
### 11.1.3 다른 언어는 null 대신 무얼 사용하나?
|
||||
최근 그루비 같은 언어에서는 `안전 내비게이션 연산자(safe navigation operator) - (?.)`를 도입해서 `null` 문제를 해결했다. 다음은 사람들이 그들의 자동차에 적용한 보험회사의 이름을 가져오는 그루비 코드 예제다.
|
||||
|
||||
```groovy
|
||||
def carInsuranceName = person?.car?.insurance?.name
|
||||
```
|
||||
|
||||
그루비 안전 내비게이션 연산자를 이용하면 `null` 참조 예외 걱정 없이 객체에 접근할 수 있다. 이때 호출 체인에 `null`인 참조가 있으면 결과로 `null`이 반환된다. 그루비의 안전 내비게이션 연산자를 이용하면 부작용을 최소화하면서 `null` 예외 문제를 더 근본적으로 해결할 수 있다.
|
||||
|
||||
`하스켈`, `스칼라` 등의 함수형 언어는 아예 다른 관점에서 `null` 문제를 접근한다. `하스켈`은 `선택형값(optional value)`을 저장할 수 있는 `Maybe`라는 형식을 제공한다. `Maybe`는 주어진 형식의 값을 갖거나 아니면 아무 값도 갖지 않을 수 있다. 따라서 `null` 참조 개념은 자연스럽게 사라진다. `스칼라`도 `T` 형식의 값을 갖거나 아무 값도 갖지 않을 수 있는 `Option[T]`라는 구조를 제공한다. 그리고 `Option` 형식에서 제공하는 연산을 사용해서 값이 있는지 여부를 명시적으로 확인해야 한다(즉, `null` 확인). 형식 시스템에서 이를 강제하므로 `null`과 관련한 문제가 일어날 가능성이 줄어든다.
|
||||
|
||||
자바 8은 `선택형값` 개념의 영향을 받아서 `java.util.Optional<T>`라는 새로운 클래스를 제공한다. 여기서는 이를 이용해서 값이 없는 상황을 모델링하는 방법을 설명한다. 또한 `null`을 `Optional`로 바꿀 때 우리 도메인 모델에서 선택형값에 접근하는 방법도 달라져야 함을 설명할 것이다.
|
||||
|
||||
---
|
||||
|
||||
## 11.2 Optional 클래스 소개
|
||||
자바 8은 `하스켈`과 `스칼라`의 영향을 받아서 `java.util.Optional<T>`라는 새로운 클래스를 제공한다. `Optional`은 선택형값을 캡슐화하는 클래스다. 예를 들어 어떤 사람이 차를 소유하고있지 않다면 `Person` 클래스의 `car` 변수는 `null`을 가져야 할 것이다. 하지만 새로운 `Optional`을 이용할 수 있으므로 `null`을 할당하는 것이 아니라 변수형을 `Optional<Car>`로 설정할 수 있다.
|
||||
|
||||
값이 있으면 `Optional` 클래스는 값을 감싼다. 반면 값이 없으면 `Optional.empty` 메서드로 `Optional`을 반환한다. `Optional.empty`는 `Optional`의 특별한 싱글턴 인스턴스를 반환하는 정적 팩토리 메서드이다. `null` 참조와 `Optional.empty()`는 서로 의미상 비슷하지만 실제로는 차이점이 많다. `null`을 참조하려 하면 `NullPointerException`이 발생하지만 `Optional.empty()`는 `Optional` 객체이므로 이를 다양한 방식으로 활용할 수 있다.
|
||||
|
||||
`null` 대신 `Optional`을 사용하면서 `Car` 형식이 `Optional<Car>`로 바뀌었다. 이는 값이 없을 수 있음을 명시적으로 보여준다. 반면 `Car` 형식을 사용했을 때는 `Car`에 `null` 참조가 할당될 수 있는데 이것이 올바른 값인지 아니면 잘못된 값인지 판단할 아무 정보도 없다.
|
||||
|
||||
이제 `Optional`을 이용해서 `예제 11-1`의 코드를 다음처럼 고칠 수 있다.
|
||||
|
||||
###### 예제 11-4. Optional로 Person/Car/Insurance 데이터 모델 재정의
|
||||
```java
|
||||
public class Person {
|
||||
private Optional<Car> car; // 사람이 차를 소유했을 수도 소유하지 않았을 수도 있으므로 Optional로 정의한다.
|
||||
|
||||
public Optional<Car> getCar() {
|
||||
return car;
|
||||
}
|
||||
}
|
||||
|
||||
public class Car {
|
||||
private Optional<Insurance> insurance; // 자동차가 보험에 가입되어 있을 수도 가입되어 있지 않았을 수도 있으므로 Optional로 정의한다.
|
||||
|
||||
public Optional<Insurance> getInsurance() {
|
||||
return insurance;
|
||||
}
|
||||
}
|
||||
|
||||
public class Insurance {
|
||||
private String name; // 보험회사에는 반드시 이름이 있다.
|
||||
|
||||
public String getName() {
|
||||
return name;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
`Optional` 클래스를 사용하면서 모델의 `의미(sementic)`가 더 명확해졌음을 확인할 수 있다. 사람은 `Optional<Car>`를 참조하며 자동차는 `Optional<Insurance>`를 참조하는데, 이는 사람이 자동차를 소유했을 수도 아닐 수도 있으며, 자동차는 보험에 가입되어 있을 수도 아닐 수도 있음을 명확히 설명한다.
|
||||
|
||||
또한 보험회사 이름은 `Optional<String>`이 아니라 `String` 형식으로 선언되어 있는데, 이는 보험회사는 반드시 이름을 가져야 함을 보여준다. 따라서 보험회사 이름을 참조할 때 `NullPointerException`이 발생할 수도 있다는 정보를 확인할 수 있다. 하지만 보험회사 이름이 `null`인지 확인하는 코드를 추가할 필요는 없다. 오히려 고쳐야 할 문제를 감추는 꼴이 되기 때문이다. 보험회사는 반드시 이름을 가져야 하며 이름이 없는 보험회사를 발견했다면 예외를 처리하는 코드를 추가하는 것이 아니라 보험회사 이름이 없는 이유가 무엇인지 밝혀서 문제를 해결해야 한다. `Optional`을 이용하면 값이 없는 상황이 우리 데이터에 문제가 있는 것인지 아니면 알고리즘의 버그인지 명확하게 구분할 수 있다. 모든 `null` 참조를 `Optional`로 대치하는 것은 바람직하지 않다. `Optional`의 역할은 더 이해하기 쉬운 API를 설계하도록 돕는 것이다. 즉, 메서드의 시그니처만 보고도 선택형값인지 여부를 구별할 수 있다. `Optional`이 등장하면 이를 언랩해서 값이 없을 수 있는 상황에 적절하게 대응하도록 강제하는 효과가 있다.
|
||||
|
||||
---
|
||||
|
||||
## 11.3 Optional 적용 패턴
|
||||
`Optional` 형식을 이용해서 도메인 모델의 의미를 더 명확하게 만들 수 있으며 `null` 참조 대신 값이 없는 상황을 표현할 수 있음을 확인했다. 실제로는 `Optional`을 어떻게 활용할 수 있을까?
|
||||
|
||||
### 11.3.1 Optional 객체 만들기
|
||||
`Optional`을 사용하려면 `Optional` 객체를 만들어야 한다. 다양한 방법으로 `Optional` 객체를 만들 수 있다.
|
||||
|
||||
#### 빈 Optional
|
||||
정적 팩토리 메서드 `Optional.empty`로 빈 `Optional` 객체를 얻을 수 있다.
|
||||
|
||||
```java
|
||||
Optional<Car> optCar = Optional.empty();
|
||||
```
|
||||
|
||||
#### null이 아닌 값으로 Optional 만들기
|
||||
또는 정적 팩토리 메서드 `Optional.of`로 `null`이 아닌 값을 포함하는 `Optional`을 만들 수 있다.
|
||||
|
||||
```java
|
||||
Optional<Car> optCar = Optional.of(car);
|
||||
```
|
||||
|
||||
이제 `car`가 `null`이라면 즉시 `NullPointerException`이 발생한다(`Optional`을 사용하지 않았다면 `car`의 프로퍼티에 접근하려 할 때 에러가 발생했을 것이다).
|
||||
|
||||
#### null값으로 Optional 만들기
|
||||
마지막으로 정적 팩토리 메서드 `Optional.ofNullable`로 `null`값을 저장할 수 있는 `Optional`을 만들 수 있다.
|
||||
|
||||
```java
|
||||
Optional<Car> optCar = Optional.ofNullable(car);
|
||||
```
|
||||
|
||||
`car`가 `null`이면 `빈 Optional` 객체가 반환된다.
|
||||
|
||||
그런데 `Optional`에서 어떻게 값을 가져오는지는 아직 살펴보지 않았다. `get` 메서드를 이용해서 `Optional`의 값을 가져올 수 있는데, `Optional`이 비어있으면 `get`을 호출했을 때 예외가 발생한다. 즉, `Optional`을 잘못 사용하면 결국 `null`을 사용했을 때와 같은 문제를 겪을 수 있다. 따라서 먼저 `Optional`로 명시적인 검사를 제거할 수 있는 방법을 살펴본다.
|
||||
|
||||
### 11.3.2 맵으로 Optional의 값을 추출하고 변환하기
|
||||
보통 객체의 정보를 추출할 때는 `Optional`을 사용할 때가 많다. 예를 들어 보험회사의 이름을 추출한다고 가정하자. 다음 코드처럼 이름 정보에 접근하기 전에 `insurance`가 `null`인지 확인해야 한다.
|
||||
|
||||
```java
|
||||
String name = null;
|
||||
if(insurance != null) {
|
||||
name = insurance.getName();
|
||||
}
|
||||
```
|
||||
|
||||
이런 유형의 패턴에 사용할 수 있도록 `Optional`은 `map` 메서드를 지원한다. 다음 코드를 살펴보자(이 코드에서는 `예제 11-4`에서 소개한 모델을 사용함).
|
||||
|
||||
```java
|
||||
Optional<Insurance> optInsurance = Optional.ofNullable(insurance);
|
||||
Optional<String> name = optInsurance.map(Insurance::getName);
|
||||
```
|
||||
|
||||
`Optional`의 `map` 메서드는 스트림의 `map` 메서드와 개념적으로 비슷하다. 스트림의 `map`은 스트림의 각 요소에 제공된 함수를 적용하는 연산이다. 여기서 `Optional` 객체를 최대 요소의 개수가 한 개 이하인 데이터 컬렉션으로 생각할 수 있다. `Optional`이 값을 포함하면 `map`의 인수로 제공된 함수가 값을 바꾼다. `Optional`이 비어있으면 아무 일도 일어나지 않는다.
|
||||
|
||||
```java
|
||||
public String getCarInsuranceName(Person person) {
|
||||
return person.getCar().getInsurance().getName();
|
||||
}
|
||||
```
|
||||
|
||||
그러면 여러 메서드를 안전하게 호출하는데, 이 코드를 어떻게 활용할 수 있을까?
|
||||
|
||||
이제 `flatMap`이라는 `Optional`의 또 다른 메서드를 살펴보자!
|
||||
|
||||
### 11.3.3 flatMap으로 Optional 객체 연결
|
||||
`map`을 사용하는 방법을 배웠으므로 다음처럼 `map`을 이용해서 코드를 재구현할 수 있다.
|
||||
|
||||
```java
|
||||
Optional<Person> optPerson = Optional.of(person);
|
||||
Optional<String> name = optPerson.map(Person::getCar)
|
||||
.map(Car::getInsurance)
|
||||
.map(Insurance::getName);
|
||||
```
|
||||
|
||||
안타깝게도 위 코드는 컴파일되지 않는다. 왜 그럴까? 변수 `optPeople`의 형식은 `Optional<People>`이므로 `map` 메서드를 호출할 수 있다. 하지만 `getCat`는 `Optional<Car>` 형식의 객체를 반환한다(`예제 11-4` 참조). 즉, `map` 연산의 결과는 `Optional<Optional<Car>>` 형식의 객체다. `getInsurance`는 또 다른 `Optional` 객체를 반환하므로 `getInsurance` 메서드를 지원하지 않는다.
|
||||
|
||||
이 문제를 어떻게 해결할 수 있을까? 스트림의 `flatMap`과 같이 우리도 이차원 `Optional`을 일차원 `Optional`로 평준화해야 한다. `flatMap` 메서드를 통해 이차원 `Optional`이 일차원 `Optional`로 바뀐다.
|
||||
|
||||
#### Optional로 자동차의 보험회사 이름 찾기
|
||||
`Optional`의 `map`과 `flatMap`을 살펴봤으니 이제 이를 실제로 사용해보자. `예제 11-2`와 `예제 11-3`에서 구현했던 빈틈이 많은 코드를 `예제 11-4`에서 보여준 `Optional` 기반 데이터 모델로 재구현할 수 있다.
|
||||
|
||||
###### 예제 11-5. Optional로 자동차의 보험회사 이름 찾기
|
||||
```java
|
||||
public String getCarInsuranceName(Optional<Person> person) {
|
||||
return person.flatMap(Person::getCar)
|
||||
.flatMap(Car::getInsurance)
|
||||
.map(Insurance::getName)
|
||||
.orElse("Unknown"); // 결과 Optional이 비어있으면 기본값 사용
|
||||
}
|
||||
```
|
||||
|
||||
`예제 11-5`를 `예제 11-2`, `예제 11-3`과 비교하면서 `Optional`을 이용해서 값이 없는 상황을 처리하는 것이 어떤 장점을 제공하는지 확인할 수 있다. 즉, `null`을 확인하느라 조건 분기문을 추가해서 코드를 복잡하게 만들지 않으면서도 쉽게 이해할 수 있는 코드를 완성했다.
|
||||
|
||||
우선 `예제 11-2`와 `예제 11-3`의 `getCarInsuranceName` 메서드의 시그니처를 고쳤다. 주어진 조건에 해당하는 사람이 없을 수 있기 때문이다. 예를 들어 `id`로 사람을 검색했는데 `id`에 맞는 사람이 없을 수 있다. 따라서 `Person` 대신 `Optional<Person>`을 사용하도록 메서드 인수 형식을 바꿨다.
|
||||
|
||||
또한 `Optional`을 사용하므로 도메인 모델과 관련한 암묵적인 지식에 의존하지 않고 명시적으로 형식 시스템을 정의할 수 있었다. 정확한 정보 전달은 언어의 가장 큰 목표 중 하나다(물론 프로그래밍 언어도 예외는 아니다). `Optional`을 인수로 받거나 `Optional`을 반환하는 메서드를 정의한다면 결과적으로 이 메서드를 사용하는 모든 사람에게 이 메서드가 빈 값을 받거나 빈 결과를 반환할 수 있음을 잘 문서화해서 제공하는 것과 같다.
|
||||
|
||||
#### Optional을 이용한 Person/Car/Insurance 참조 체인
|
||||
지금까지 `Optional<Person>`으로 시작해서 `Person`의 `Car`, `Car`의 `Insurance`, `Insurance`의 이름 문자열을 참조(`map`, `flatMap`을 이용)하는 방법을 살펴봤다.
|
||||
|
||||
우선 `Person`을 `Optional`로 감싼 다음에 `flatMap(Person::getCar)`를 호출했다. 이미 설명한 것처럼 이 호출을 두 단계의 논리적 과정으로 생각할 수 있다. 첫 번째 단계에서는 `Optional` 내부의 `Person`에 `Function`을 적용한다. 여기서는 `Person`의 `getCar` 메서드가 `Function`이다. `getCar` 메서드는 `Optional<Car>`를 반환하므로 `Optional` 내부의 `Person`이 `Optional<Car>`로 변환되면서 중첩 `Optional`이 생성된다. 따라서 `flatMap` 연산으로 `Optional`을 평준화한다. 평준화 과정이란 이론적으로 두 `Optional`을 합치는 기능을 수행하면서 둘 중 하나라도 `null`이면 빈 `Optional`을 생성하는 연산이다. `flatMap`을 빈 `Optional`에 호출하면 아무 일도 일어나지 않고 그대로 반환된다. 반면 `Optional`이 `Person`을 감싸고 있다면 `flatMap`에 전달된 `Function`이 `Person`에 적용된다. `Function`을 적용한 결과가 이미 `Optional`이므로 `flatMap` 메서드는 결과를 그대로 반환할 수 있다.
|
||||
|
||||
두 번째 단계도 첫 번째 단계와 비슷하게 `Optional<Car>`를 `Optional<Insurance>`로 변환한다. 세 번째 단계에서 `Insurance.getName()`은 `String`을 반환하므로 `flatMap`을 사용할 필요가 없다.
|
||||
|
||||
호출 체인 중 어떤 메서드가 `빈 Optional`을 반환한다면 전체 결과로 `빈 Optional`을 반환하고 아니면 관련 보험회사의 이름을 포함하는 `Optional`을 반환한다. 이제 반환된 `Optional`의 값을 어떻게 읽을 수 있을까? 호출 체인의 결과로 `Optional<String>`이 반환되는게 여기에 회사 이름이 저장되어 있을 수도 있고 없을 수도 있다. `예제 11-5`에서는 `Optional`이 비어있을 때 기본값(default value)을 제공하는 `orElse`라는 메서드를 사용했다. `Optional`은 기본값을 제공하거나 `Optional`을 언랩(unwrap)하는 다양한 메서드를 제공한다.
|
||||
|
||||
### 11.3.4 Optional 스트림 조작
|
||||
자바 9에서는 `Optional`을 포함하는 스트림을 쉽게 처리할 수 있도록 `Optional`에 `stream()` 메서드를 추가했다. `Optional` 스트림을 값을 가진 스트림으로 변환할 때 이 기능을 유용하게 활용할 수 있다. 여기서는 다른 예제를 이용해 `Optional` 스트림을 어떻게 다루고 처리하는지 설명한다.
|
||||
|
||||
`예제 11-6`은 `예제 11-4`에서 정의한 `Person/Car/Insurance` 도메인 모델을 사용한다. `List<Person>`을 인수로 받아 자동차를 소유한 사람들이 가입한 보험 회사의 이름을 포함하는 `Set<String>`을 반환하도록 메서드를 구현해야 한다.
|
||||
|
||||
###### 예제 11-6. 사람 목록을 이용해 가입한 보험 회사 이름 찾기
|
||||
```java
|
||||
public Set<String> getCarInsuranceNames(List<Person> persons) {
|
||||
return persons.stream()
|
||||
.map(Person::getCar) // 사람 목록을 각 사람이 보유한 자동차의 Optional<Car> 스트림으로 변환
|
||||
.map(optCar -> optCar.flatMap(Car::getInsurance)) // flatMap 연산을 이용해 Optional<Car>을 해당 Optional<Insurance>로 변환
|
||||
.map(optIns -> optIns.map(Insurance::getName)) // Optional<Insurance>를 해당 이름의 Optional<String>으로 매핑
|
||||
.flatMap(Optional::stream) // Stream<Optional<String>>을 현재 이름을 포함하는 Stream<String>으로 변환
|
||||
.collect(toSet()); // 결과 문자열을 중복되지 않은 값을 갖도록 집합으로 수집
|
||||
}
|
||||
```
|
||||
|
||||
보통 스트림 요소를 조작하려면 변환, 필터 등의 일련의 여러 긴 체인이 필요한데 이 예제는 `Optional` 값이 감싸있으므로 이 과정이 조금 더 복잡해졌다. 예제에서 `getCar()` 메서드가 단순히 `Car`가 아니라 `Optional<Car>`를 반환하므로 사람이 자동차를 가지지 않을 수도 있는 상황임을 기억하자. 따라서 첫 번째 `map` 변환을 수행하고 `Stream<Optional<Car>>`를 얻는다. 이어지는 두 개의 `map` 연산을 이용해 `Optional<Car>`를 `Optional<Insurance>`로 변환한 다음 `예제 11-5`에서 했던 것처럼 스트림이 아니라 각각의 요소에 했던 것처럼 각각을 `Optional<String>`로 변환한다.
|
||||
|
||||
세 번의 변환 과정을 거친 결과 `Stream<Optional<String>>`를 얻는데 사람이 차를 갖고 있지 않거나 또는 차가 보험에 가입되어 있지 않아 결과가 비어있을 수 있다. `Optional` 덕분에 이런 종류의 연산을 `null` 걱정없이 안전하게 처리할 수 있지만 마지막 결과를 얻으려면 `빈 Optional`을 제거하고 값을 언랩해야 한다는 것이 문제다. 다음 코드처럼 `filter`, `map`을 순서적으로 이용해 결과를 얻을 수 있다.
|
||||
|
||||
```java
|
||||
Stream<Optional<String>> stream = ...
|
||||
Set<String> result = stream.filter(Optional::isPresent)
|
||||
.map(Optional::get)
|
||||
.collect(toSet());
|
||||
```
|
||||
|
||||
하지만 `예제 11-6`에서 확인했듯이 `Optional` 클래스의 `stream()` 메서드를 이용하면 한 번의 연산으로 같은 결과를 얻을 수 있다. 이 메서드는 각 `Optional`이 비어있는지 아닌지에 따라 `Optional`을 0개 이상의 항목을 포함하는 스트림으로 변환한다. 따라서 이 메서드의 참조를 스트림의 한 요소에서 다른 스트림으로 적용하는 함수로 볼 수 있으며 이를 원래 스트림에 호출하는 `flatMap` 메서드로 전달할 수 있다. 지금까지 배운것처럼 이런 방법으로 스트림의 요소를 두 수준인 스트림의 스트림으로 변환하고 다시 한 수준인 평면 스트림으로 바꿀 수 있다. 이 기법을 이용하면 한 단계의 연산으로 값을 포함하는 `Optional`을 언랩하고 비어있는 `Optional`은 건너뛸 수 있다.
|
||||
|
||||
### 11.3.5 디폴트 액션과 Optional 언랩
|
||||
`빈 Optional`인 상황에서 기본값을 반환하도록 `orElse`로 `Optional`을 읽었다. `Optional` 클래스는 이 외에도 `Optional` 인스턴스에 포함된 값을 읽는 다양한 방법을 제공한다.
|
||||
|
||||
- `get()`은 값을 읽는 가장 간단한 메서드면서 동시에 가장 안전하지 않은 메서드다. 메서드 `get`은 래핑된 값이 있으면 해당 값을 변환하고 값이 없으면 `NoSuchElementException`을 발생시킨다. 따라서 `Optional`에 값이 반드시 있다고 가정할 수 있는 상황이 아니면 `get` 메서드를 사용하지 않는 것이 바람직하다. 결국 이 상황은 중첩된 `null` 확인 코드를 넣는 상황과 크게 다르지 않다.
|
||||
- `예제 11-5`에서는 `orElse(T other)`를 사용했다. `orElse` 메서드를 이용하면 `Optional`이 값을 포함하지 않을 때 기본값을 제공할 수 있다.
|
||||
- `orElseGet(Supplier<? extends T> other)`는 `orElse` 메서드에 대응하는 게으른 버전의 메서드다. `Optional`에 값이 없을 때만 `Supplier`가 실행되기 때문이다. 디폴트 메서드를 만드는 데 시간이 걸리거나(효율성 때문에) `Optional`이 비어있을 때만 기본값을 생성하고 싶다면(기본 값이 반드시 필요한 상황) `orElseGet(Supplier<? extends T> other)`를 사용해야 한다.
|
||||
- `orElseThrow(Supplier<? extends X> exceptionSupplier)`는 `Optional`이 비어있을 때 예외를 발생시킨다는 점에서 `get` 메서드와 비슷하다. 하지만 이 메서드는 발생시킬 예외의 종류를 선택할 수 있다.
|
||||
- `ifPersent(Consumer<? super T> consumer)`를 이용하면 값이 존재할 때 인수로 넘겨준 동작을 실행할 수 있다. 값이 없으면 아무 일도 일어나지 않는다.
|
||||
|
||||
자바 9에서는 다음의 인스턴스 메서드가 추가되었다.
|
||||
- `ifPresentOrElse(Consumer<? super T> action, Runnable emptyAction)`. 이 메서드는 `Optional`이 비었을 때 실행할 수 있는 `Runnable`을 인수로 받는다는 점만 `ifPresent`와 다르다.
|
||||
|
||||
### 11.3.6 두 Optional 합치기
|
||||
이제 `Person`과 `Car` 정보를 이용해서 가장 저렴한 보험료를 제공하는 보험회사를 찾는 몇몇 복잡한 비즈니스 로직을 구현한 외부 서비스가 있다고 가정하자.
|
||||
|
||||
```java
|
||||
public Insurance findCheapestInsurance(Person person, Car car) {
|
||||
// 다양한 보험회사가 제공하는 서비스 조회
|
||||
// 모든 결과 데이터 비교
|
||||
return cheapestCompany;
|
||||
}
|
||||
```
|
||||
|
||||
이제 두 `Optional`을 인수로 받아서 `Optional<Insurance>`를 반환하는 `null 안전 버전(nullsafe version)`의 메서드를 구현해야 한다고 가정하자. 인수로 전달한 값 중 하나라도 비어있으면 `빈 Optional<Insurance>`를 반환한다. `Optional` 클래스는 `Optional`이 값을 포함하는지 여부를 알려주는 `isPresent`라는 메서드도 제공한다. 따라서 `isPresent`를 이용해서 다음처럼 코드를 구현할 수 있다.
|
||||
|
||||
```java
|
||||
public Optional<Insurance> nullSafeFindCheapestInsurance(Optional<Person> person, Optional<Car> car) {
|
||||
if (person.isPersent() && car.isPersent()) {
|
||||
return Optional.of(findCheapestInsurance(person.get(), car.get()));
|
||||
} else {
|
||||
return Optional.empty();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
이 메서드의 장점은 `person`과 `car`의 시그니처만으로 둘 다 아무 값도 반환하지 않을 수 있다는 정보를 명시적으로 보여준다는 것이다. 안타깝게도 구현 코드는 `null` 확인 코드와 크게 다른 점이 없다. `Optional` 클래스에서 제공하는 기능을 이용해서 이 코드를 더 자연스럽게 개선할 수 없을까? `퀴즈 11-1`을 살펴보면서 더 멋진 해결책을 찾아보자.
|
||||
|
||||
`Optional` 클래스와 `Stream` 인터페이스는 `map`과 `flatMap` 메서드 이외에도 다양한 비슷한 기능을 공유한다. 다음으로는 세 번째 메서드 `filter`를 살펴본다.
|
||||
|
||||
##### 퀴즈 11-1. Optional 언랩하지 않고 두 Optional 합치기
|
||||
`map`과 `flatMap` 메서드를 이용해서 기존의 `nullSafeFindCheapestInsurance()` 메서드를 한 줄의 코드로 재구현하시오.
|
||||
|
||||
```java
|
||||
// 정답
|
||||
public Optional<Insurance> nullSafeFindCheapestInsurance(Optional<Person> person, Optional<Car> car) {
|
||||
return person.flatMap(p -> car.map(c -> findCheapestInsurance(p, c)));
|
||||
}
|
||||
```
|
||||
|
||||
### 11.3.7 필터로 특정값 거르기
|
||||
종종 객체의 메서드를 호출해서 어떤 프로퍼티를 확인해야 할 때가 있다. 예를 들어 보험회사 이름이 'CambridgeInsurance'인지 확인해야 한다고 가정하자. 이 작업을 안전하게 수행하려면 다음 코드에서 보여주는 것처럼 `Insurance` 객체가 `null`인지 여부를 확인한 다음에 `getName` 메서드를 호출해야 한다.
|
||||
|
||||
```java
|
||||
Insurance insurance = ...;
|
||||
if(insurance != null && "CambridgeInsurance".equals(insurance.getName())) {
|
||||
System.out.println("ok");
|
||||
}
|
||||
```
|
||||
|
||||
`Optional` 객체에 `filter` 메서드를 이용해서 다음과 같이 코드를 재구현할 수 있다.
|
||||
|
||||
```java
|
||||
Optional<Insurance> optInsurance = ...;
|
||||
optInsurance.filter(insurance -> "CambridgeInsurance".equals(insurance.getName()))
|
||||
.ifPresent(x -> System.out.println("ok"));
|
||||
```
|
||||
|
||||
`filter` 메서드는 프레디케이트를 인수로 받는다. `Optional` 객체가 값을 가지며 프레디케이트와 일치하면 `filter` 메서드는 그 값을 반환하고 그렇지 않으면 `빈 Optional` 객체를 반환한다. `Optional`은 최대 한 개의 요소를 포함할 수 있는 스트림과 같다고 설명했으므로 이 사실을 적용하면 `filter` 연산의 결과를 쉽게 이해할 수 있다. `Optional`이 비어있다면 `filter` 연산은 아무 동작도 하지 않는다. `Optional`에 값이 있으면 그 값에 프레디케이트를 적용한다. 프레디케이트 적용 결과가 `true`면 `Optional`에는 아무 변화도 일어나지 않는다. 하지만 결과가 `false`면 값은 사라져버리고 `Optional`은 빈 상태가 된다.
|
||||
|
||||
##### 퀴즈 11-2. Optional 필터링
|
||||
우리의 `Person/Car/Insurance` 모델을 구현하는 `Person` 클래스에는 사람의 나이 정보를 가져오는 `getAge`라는 메서드도 있었다. 다음 시그니처를 이용해서 `예제 11-5`의 `getCarInsuranceName` 메서드를 고치시오.
|
||||
|
||||
```java
|
||||
public String getCarInsuranceName(Optional<Person> person, int minAge)
|
||||
```
|
||||
|
||||
즉, 인수 `person`이 `minAge` 이상의 나이일 때만 보험회사 이름을 반환한다.
|
||||
|
||||
```java
|
||||
// 정답
|
||||
public String getCarInsuranceName(Optional<Person> person, int minAge) {
|
||||
return person.filter(p -> p.getAge() >= minAge)
|
||||
.flatMap(Person::getCar)
|
||||
.flatMap(Car::getInsurance)
|
||||
.map(Insurance::getName)
|
||||
.orElse("Unknown");
|
||||
}
|
||||
```
|
||||
|
||||
##### 표 11-1. Optional 클래스의 메서드
|
||||
|메서드|설명|
|
||||
|-|-|
|
||||
|empty|`빈 Optional` 인스턴스 반환|
|
||||
|filter|값이 존재하며 프레디케이트와 일치하면 값을 포함하는 `Optional`을 반환하고, 값이 없거나 프레디케이트와 일치하지 않으면` 빈 Optional`을 반환함|
|
||||
|flatMap|값이 존재하면 인수로 제공된 함수를 적용한 `결과 Optional`을 반환하고, 값이 없으면 `빈 Optional`을 반환함|
|
||||
|get|값이 존재하면 `Optional이 감싸고 있는 값`을 반환하고, 값이 없으면 `NoSuchElementException`이 발생함|
|
||||
|ifPersent|값이 존재하면 지정된 `Consumer를 실행`하고, 값이 없으면 아무 일도 일어나지 않음|
|
||||
|ifPersentOrElse|값이 존재하면 지정된 `Consumer를 실행`하고, 값이 없으면 아무 일도 일어나지 않음|
|
||||
|isPersent|값이 존재하면 `true`를 반환하고, 값이 없으면 `false`를 반환함|
|
||||
|map|값이 존재하면 제공된 매핑 함수를 적용함|
|
||||
|of|값이 존재하면 `값을 감싸는 Optional`을 반환하고, 값이 `null`이면 `NullPointerException`을 발생함|
|
||||
|ofNullable|값이 존재하면 `값을 감싸는 Optional`을 반환하고, 값이 `null`이면 `빈 Optional`을 반환함|
|
||||
|or|값이 존재하면 `같은 Optional`을 반환하고, 값이 없으면 `Supplier`에서 만든 `Optional`을 반환|
|
||||
|orElse|값이 존재하면 값을 반환하고, 값이 없으면 기본값을 반환|
|
||||
|orElseGet|값이 존재하면 값을 반환하고, 값이 없으면 `Supplier에서 제공하는 값`을 반환|
|
||||
|orElseThrow|값이 존재하면 값을 반환하고, 값이 없으면 `Supplier에서 생성한 예외`를 발생함|
|
||||
|stream|값이 존재하면 `존재하는 값만 포함하는 스트림을 반환`하고, 값이 없으면 빈 스트림을 반환|
|
||||
|
||||
---
|
||||
|
||||
## 11.4 Optional을 사용한 실용 예제
|
||||
`Optional` 클래스를 효과적으로 사용하려면 잠재적으로 존재하지 않는 값의 처리 방법을 바꿔야 한다. 즉, 코드 구현만 바꾸는 것이 아니라 네이티브 자바 API와 상호작용하는 방식도 바꿔야 한다. `Optional` 기능을 활용할 수 있도록 우리 코드에 작은 유틸리티 메서드를 추가하는 방식으로 이 문제를 해결할 수 있다.
|
||||
|
||||
### 11.4.1 잠재적으로 null이 될 수 있는 대상을 Optional로 감싸기
|
||||
기존의 자바 API에서는 `null`을 반환하면서 요청한 값이 없거나 어떤 문제로 계산에 실패했음을 알린다. 예를 들어 `Map`의 `get` 메서드는 요청한 키에 대응하는 값을 찾지 못했을 때 `null`을 반환한다. 지금까지 살펴본 것처럼 `null`을 반환하는 것보다는 `Optional`을 반환하는 것이 더 바람직하다. `get` 메서드의 시그니처는 우리가 고칠 수 없지만 `get` 메서드의 반환값은 `Optional`로 감쌀 수 있다. `Map<String, Object>` 형식의 맵이 있는데, 다음처럼 `key`로 값에 접근한다고 가정하자.
|
||||
|
||||
```java
|
||||
Object value = map.get("key");
|
||||
```
|
||||
|
||||
문자열 `key`에 해당하는 값이 없으면 `null`이 반환될 것이다. `map`에서 반환하는 값을 `Optional`로 감싸서 이를 개선할 수 있다. 코드가 복잡하기는 하지만 기존처럼 `if-then-else`를 추가하거나, 아니면 아래와 같이 깔끔하게 `Optional.ofNullable`을 이용하는 두 가지 방법이 있다.
|
||||
|
||||
```java
|
||||
Optional<Object> value = Optional.ofNullable(map.get("key"));
|
||||
```
|
||||
|
||||
이와 같은 코드를 이용해서 `null`일 수 있는 값을 `Optional`로 안전하게 변환할 수 있다.
|
||||
|
||||
### 11.4.2 예외와 Optional 클래스
|
||||
자바 API는 어떤 이유에서 값을 제공할 수 없을 때 `null`을 반환한느 대신 예외를 발생시킬 때도 있다. 이것에 대한 전형적인 예가 문자열을 정수로 변환하는 정적 메서드 `Integer.parseInt(String)`다. 이 메서드는 문자열을 정수로 바꾸지 못할 때 `NumberFormatException`을 발생시킨다. 즉, 문자열이 숫자가 아니라는 사실을 예외로 알리는 것이다. 기존에 값이 `null`일 수 있을때는 `if`문으로 `null` 여부를 확인했지만 예외를 발생시키는 메서드에서는 `try/catch 블록`을 사용해야 한다는 점이 다르다.
|
||||
|
||||
정수로 변환할 수 없는 문자열 문제를 `빈 Optional`로 해결할 수 있다. 즉, `parseInt`가 `Optional`을 반환하도록 모델링할 수 있다. 물론 기존 자바 메서드 `parseInt`를 직접 고칠 수는 없지만 다음 코드처럼 `parseInt`를 감싸는 작은 유틸리티 메서드를 구현해서 `Optional`을 반환할 수 있다.
|
||||
|
||||
###### 예제 11-7. 문자열을 정수 Optional로 변환
|
||||
```java
|
||||
public static Optional<Integer> stringToInt(String s) {
|
||||
try {
|
||||
return Optional.of(Integer.parseInt(s)); // 문자열을 정수로 변환할 수 있으면 정수로 변환된 값을 포함하는 Optional을 반환한다.
|
||||
} catch (NumberFormatException e) {
|
||||
return Optional.empty(); // 그렇지 않으면 빈 Optional을 반환한다.
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
위와 같은 메서드를 포함하는 유틸리티 클래스 `OptionalUtility`를 만들어서 필요할 때 `OptionalUtility.stringToInt`를 이용해서 문자열을 `Optional<Integer>`로 변환할 수 있다. 기존처럼 거추장스러운 `try/catch` 로직을 사용할 필요가 없다.
|
||||
|
||||
### 11.4.3 기본형 Optional을 사용하지 말아야 하는 이유
|
||||
스트림처럼 `Optional`도 기본형으로 특화된 `OptionalInt`, `OptionalLong`, `OptionalDouble` 등의 클래스를 제공한다. 예를 들어 `예제 11-7`에서 `Optional<Integer>` 대신 `OptionalInt`를 반환할 수 있다. 하지만 스트림과는 달리 `Optional`의 최대 요소 수는 한 개이므로 `Optional`에서는 기본형 특화 클래스로 성능을 개선할 수 없다.
|
||||
|
||||
기본형 특화 `Optional`은 `Optional` 클래스의 유용한 메서드 `map`, `flatMap`, `filter` 등을 지원하지 않으므로 기본형 특화 `Optional`을 사용할 것을 권장하지 않는다. 게다가 스트림과 마찬가지로 기본형 특화 `Optional`로 생성한 결과는 다른 일반 `Optional`과 혼용할 수 없다. 예를 들어 `예제 11-7`이 `OptionalInt`를 반환한다면 이를 다른 `Optional`의 `flatMap`에 메서드 참조로 전달할 수 없다.
|
||||
|
||||
### 11.4.4 응용
|
||||
`Optional` 클래스의 메서드를 실제 업무에서 어떻게 활용할 수 있는지 살펴보자. 예를 들어 프로그램의 설정 인수로 `Properties`를 전달한다고 가정하자. 그리고 다음과 같은 `Properties`로 우리가 만든 코드를 테스트할 것이다.
|
||||
|
||||
```java
|
||||
Properties props = new Properties();
|
||||
props.setProperty("a", "5");
|
||||
props.setProperty("b", "true");
|
||||
props.setProperty("c", "-3");
|
||||
```
|
||||
|
||||
이제 프로그램에서는 `Properties`를 읽어서 값을 초 단위의 지속 시간(duration)으로 해석한다. 다음과 같은 메서드 시그니처로 지속 시간을 읽을 것이다.
|
||||
|
||||
```java
|
||||
public int readDuration(Properties props, String name)
|
||||
```
|
||||
|
||||
지속 시간은 양수여야 하므로 문자열이 양의 정수를 가리키면 해당 정수를 반환하지만 그 외에는 0을 반환한다. 이를 다음처럼 `JUnit` 어설션(assertion)으로 구현할 수 있다.
|
||||
|
||||
```java
|
||||
assertEquals(5, readDuration(param, "a"));
|
||||
assertEquals(0, readDuration(param, "b"));
|
||||
assertEquals(0, readDuration(param, "c"));
|
||||
assertEquals(0, readDuration(param, "d"));
|
||||
```
|
||||
|
||||
이들 어설션은 다음과 같은 의미를 갖는다. 프로퍼티 `a`는 양수로 변환할 수 있는 문자열을 포함하므로 `readDuration` 메서드는 5를 반환한다. 프로퍼티 `b`는 숫자로 변환할 수 없는 문자열을 포함하므로 0을 반환한다. 프로퍼티 `c`는 음수 문자열을 포함하므로 0을 반환한다. `d`라는 이름의 프로퍼티는 없으므로 0을 반환한다.
|
||||
|
||||
###### 예제 11-8. 프로퍼티에서 지속 시간을 읽는 명령형 코드
|
||||
```java
|
||||
public int readDuration(Properties props, String name) {
|
||||
String value = props.getProperty(name);
|
||||
if (value != null) { // 요청한 이름에 해당하는 프로퍼티가 존재하는지 확인한다.
|
||||
try {
|
||||
int i = Integer.parseInt(value); // 문자열 프로퍼티를 숫자로 변환하기 위해 시도한다.
|
||||
if (i > 0) { // 결과 숫자가 양수인지 확인한다.
|
||||
return i;
|
||||
}
|
||||
} catch (NumberFormatException nfe) {
|
||||
|
||||
}
|
||||
}
|
||||
return 0; // 하나의 조건이라도 실패하면 0을 반환한다.
|
||||
}
|
||||
```
|
||||
|
||||
예상대로 `if`문과 `try/catch` 블록이 중첩되면서 구현 코드가 복잡해졌고 가독성도 나빠졌다.
|
||||
|
||||
##### 퀴즈 11-3. Optional로 프로퍼티에서 지속 시간 읽기
|
||||
지금까지 배운 `Optional` 클래스의 기능과 `예제 11-7`의 유틸리티 메서드를 이용해서 `예제 11-8`의 명령형 코드를 하나의 유연한 코드로 재구현하시오.
|
||||
|
||||
다음은 간단하게 구현한 정답 코드다.
|
||||
|
||||
```java
|
||||
public int readDuration(Properties props, String name) {
|
||||
return Optional.ofNullable(props.getProperty(name))
|
||||
.flatMap(OptionalUtility::stringToInt)
|
||||
.filter(i -> i > 0)
|
||||
.orElse(0);
|
||||
}
|
||||
```
|
||||
|
||||
`Optional`과 스트림에서 사용한 방식은 여러 연산이 서로 연결되는 데이터베이스 질의문과 비슷한 형식을 갖는다.
|
||||
|
||||
---
|
||||
|
||||
## 11.5 마치며
|
||||
- 역사적으로 프로그래밍 언어에서는 `null` 참조로 값이 없는 상황을 표현해왔다.
|
||||
- 자바 8에서는 값이 있거나 없음을 표현할 수 있는 클래스 `java.util.Optional<T>`를 제공한다.
|
||||
- 팩토리 메서드 `Optional.empty`, `Optional.of`, `Optional.ofNullable` 등을 이용해서 `Optional` 객체를 만들 수 있다.
|
||||
- `Optional` 클래스는 스트림과 비슷한 연산을 수행하는 `map`, `flatMap`, `filter` 등의 메서드를 제공한다.
|
||||
- `Optional`로 값이 없는 상황을 적절하게 처리하도록 강제할 수 있다. 즉, `Optional`로 예상치 못한 `null` 예외를 방지할 수 있다.
|
||||
- `Optional`을 활용하면 더 좋은 API를 설계할 수 있다. 즉, 사용자는 메서드의 시그니처만 보고도 `Optional`값이 사용되거나 반환되는지 예측할 수 있다.
|
||||
|
||||
---
|
||||
@@ -0,0 +1,9 @@
|
||||
package Chapter11;
|
||||
|
||||
public class Insurance {
|
||||
private String name;
|
||||
|
||||
public String getName() {
|
||||
return name;
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,11 @@
|
||||
package Chapter11;
|
||||
|
||||
import java.util.Optional;
|
||||
|
||||
public class Person {
|
||||
private Optional<Car> car;
|
||||
|
||||
public Optional<Car> getCar() {
|
||||
return car;
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,9 @@
|
||||
package Chapter11;
|
||||
|
||||
import java.util.Optional;
|
||||
|
||||
public class Quiz11_1 {
|
||||
// public Optional<Insurance> nullSafeFindCheapestInsurance(Optional<Person> person, Optional<Car> car) {
|
||||
// return person.flatMap(p -> car.map(c -> nullSafeFindCheapestInsurance(p, c)));
|
||||
// }
|
||||
}
|
||||
488
도서/모던 자바 인 액션 (Modern Java In Action)/src/Chapter12/Chapter12.md
Normal file
@@ -0,0 +1,488 @@
|
||||
# Chapter12. 새로운 날짜와 시간 API
|
||||
- 자바 API는 복잡한 애플리케이션을 만드는 데 필요한 여러 가지 유용한 컴포넌트를 제공한다.
|
||||
- 자바 8에서는 지금까지의 날짜와 시간 문제를 개선하는 새로운 날짜와 시간 API를 제공한다.
|
||||
- 자바 1.0에서는 `java.util.Date` 클래스 하나로 날짜와 시간 관련 기능을 제공했다. 날짜를 의미하는 `Date`라는 클래스의 이름과 달리 `Date` 클래스는 특정 시점을 날짜가 아닌 밀리초 단위로 표현한다.
|
||||
- 게다가 1900년을 기준으로 하는 오프셋, 0에서 시작하는 달 인덱스 등 모호한 설계로 유용성이 떨어졌다.
|
||||
- 다음은 자바 9의 릴리스 날짜인 2017년 9월 21일을 가리키는 `Date` 인스턴스를 만드는 코드다.
|
||||
|
||||
```java
|
||||
Date date = new Date(117, 8, 21);
|
||||
```
|
||||
|
||||
다음은 날짜 출력 결과다.
|
||||
|
||||
```
|
||||
Thu Sep 21 00:00:00 CET 2017
|
||||
```
|
||||
|
||||
- 결과가 직관적이지 않으며 `Date` 클래스의 `toString`으로는 반환되는 문자열을 추가로 활용하기가 어렵다.
|
||||
- 출력 결과에서 알 수 있듯이 `Date`는 `JVM` 기본시간대인 `CET`, 즉 `중앙 유럽시간대(Central European Time)`를 사용했다. 그렇다고 `Date` 클래스가 자체적으로 시간대 정보를 알고 있는 것도 아니다.
|
||||
- 자바 1.0의 `Date` 클래스에 문제가 있다는 점에는 의문의 여지가 없었지만 과거 버전과 호환성을 깨뜨리지 않으면서 이를 해결할 수 있는 방법이 없었다.
|
||||
- 결과적으로 자바 1.1에서는 `Date` 클래스의 여러 메서드를 사장(deprecated)시키고 `java.util.Calendar`라는 클래스를 대안으로 제공했다. 안타깝게도 `Calendar` 클래스 역시 쉽게 에러를 일으키는 문제를 가지고 있었다.
|
||||
- 예를 들어 `Calendar`에서는 1900년도에서 시작하는 오프셋은 없앴지만 여전히 달의 인덱스는 0부터 시작했다.
|
||||
- 더 안타까운 점은 `Date`와 `Calendar` 두 가지 클래스가 등장하면서 개발자들에게 혼란이 가중된 것이다.
|
||||
- 게다가 `DateFormat` 같은 일부 기능은 `Date` 클래스에만 작동했다(`DateFormat`은 언어의 종류와 독립적으로 날짜와 시간의 형식을 조절하고 파싱할 때 사용한다).
|
||||
- `DateFormat`에도 문제가 있었다. 예를 들어 `DateFormat`은 스레드에 안전하지 않다. 즉, 두 스레드가 동시에 하나의 포매터(formatter)로 날짜를 파싱할 때 예기치 못한 결과가 일어날 수 있다.
|
||||
- 마지막으로 `Date`와 `Calendar`는 모두 가변(mutable) 클래스다. 가변 클래스라는 설계 때문에 유지보수가 아주 어렵다.
|
||||
- 부실한 날짜와 시간 라이브러리 때문에 많은 개발자는 `Joda-Time` 같은 서드파티 날짜와 시간 라이브러리를 사용했고, 결국 자바 8에서는 `Joda-Time`의 많은 기능을 `java.time` 패키지로 추가했다.
|
||||
|
||||
여기서는 새로운 날짜와 시간 API가 제공하는 새로운 기능을 살펴본다. 먼저 사람과 기기에서 사용할 수 있는 날짜와 시간을 생성하는 기본적인 방법을 살펴본 다음에, 날짜 시간 객체를 조작하고, 파싱하고, 출력하거나, 다양한 시간대와 대안 캘린더 등 새로운 날짜와 시간 API를 사용하는 방법을 살펴본다.
|
||||
|
||||
---
|
||||
|
||||
## 12.1 LocalDate, LocalTime, Instant, Duration, Period 클래스
|
||||
- `java.time` 패키지는 `LocalDate`, `LocalTime`, `LocalDateTime`, `Instant`, `Duration`, `Period` 등 새로운 클래스를 제공한다.
|
||||
|
||||
### 12.1.1 LocalDate와 LocalTime 사용
|
||||
새로운 날짜와 시간 API를 사용할 때 처음 접하게 되는 것이 `LocalDate`다. `LocalDate` 인스턴스는 시간을 제외한 날짜를 표현하는 불변 객체다. 특히 `LocalDate` 객체는 어떤 시간대 정보도 포함하지 않는다.
|
||||
|
||||
정적 팩토리 메서드 `of`로 `LocalDate` 인스턴스를 만들 수 있다. 다음 코드에서 보여주는 것처럼 `LocalDate` 인스턴스는 연도, 달, 요일 등을 반환하는 메서드를 제공한다.
|
||||
|
||||
###### 예제 12-1. LocalDate 만들고 값 읽기
|
||||
```java
|
||||
LocalDate date = LocalDate.of(2017, 9, 21); // 2017-09-21
|
||||
int year = date.getYear(); // 2017
|
||||
Month month = date.getMonth(); // SEPTEMBER
|
||||
int day = date.getDayOfMonth(); // 21
|
||||
DayOfWeek dow = date.getDayOfWeek(); //THURSDAY
|
||||
int len = date.lengthOfMonth(); // 31 (3월의 일 수)
|
||||
boolean leap = date.isLeapYear(); // false (윤년이 아님)
|
||||
```
|
||||
|
||||
팩토리 메서드 `now`는 시스템 시계의 정보를 이용해서 현재 날짜 정보를 얻는다.
|
||||
|
||||
```java
|
||||
LocalDate today = LocalDate.now();
|
||||
```
|
||||
|
||||
지금부터 살펴볼 다른 날짜와 시간 관련 클래스도 이와 비슷한 기능을 제공한다. `get` 메서드에 `TemporalField`를 전달해서 정보를 얻는 방법도 있다. `TemporalField`는 시간 관련 객체에서 어떤 필드의 값에 접근할지 정의하는 인터페이스다. 열거자 `ChronoField`는 `TemporalField` 인터페이스를 정의하므로 다음 코드에서 보여주는 것처럼 `ChronoField`의 열거자 요소를 이용해서 원하는 정보를 쉽게 얻을 수 있다.
|
||||
|
||||
###### 예제 12-2. TemporalField를 이용해서 LocalDate값 읽기
|
||||
```java
|
||||
int year = date.get(ChronoField.YEAR);
|
||||
int month = date.get(ChronoField.MONTH_OF_YEAR);
|
||||
int day = date.get(ChronoField.DAY_OF_MONTH);
|
||||
```
|
||||
|
||||
다음처럼 내장 메서드 `getYear()`, `getMonthValue()`, `getDayOfMonth()` 등을 이용해 가독성을 높일 수 있다.
|
||||
|
||||
```java
|
||||
int year = date.getYear();
|
||||
int month = date.getMonthValue();
|
||||
int day = date.getDayOfMonth();
|
||||
```
|
||||
|
||||
마찬가지로 `13:45:20` 같은 시간은 `LocalTime` 클래스로 표현할 수 있다. 오버로드 버전의 두 가지 정적 메서드 `of`로 `LocalTime` 인스턴스를 만들 수 있다. 즉, 시간과 분을 인수로 받는 `of` 메서드와 시간과 분, 초를 인수로 받는 `of` 메서드가 있다. `LocalDate` 클래스처럼 `LocalTime` 클래스는 다음과 같은 게터 메서드를 제공한다.
|
||||
|
||||
###### 예제 12-3. LocalTime 만들고 값 읽기
|
||||
```java
|
||||
LocalTime time = LocalTime.of(13, 45, 20);
|
||||
int hour = time.getHour();
|
||||
int minute = time.getMinute();
|
||||
int second = time.getSecond();
|
||||
```
|
||||
|
||||
날짜와 시간 문자열로 `LocalDate`와 `LocalTime`의 인스턴스를 만드는 방법도 있다. 다음처럼 `parse` 정적 메서드를 사용할 수 있다.
|
||||
|
||||
```java
|
||||
LocalDate date = LocalDate.parse("2017-09-21");
|
||||
LocalTime time = LocalTime.parse("13:45:20");
|
||||
```
|
||||
|
||||
`parse` 메서드에 `DateTimeFormatter`를 전달할 수도 있다. `DateTimeFormatter`의 인스턴스는 날짜, 시간 객체의 형식을 지정한다. `DateTimeFormatter`는 이전에 설명했던 `java.util.DateFormat` 클래스를 대체하는 클래스다. 문자열을 `LocalDate`나 `LocalTime`으로 파싱할 수 없을 때 `parse` 메서드는 `DateTimeParseException (RuntimeException을 상속받은 예외)`을 일으킨다.
|
||||
|
||||
### 12.1.2 날짜와 시간 조합
|
||||
`LocalDateTime`은 `LocalDate`와 `LocalTime`을 쌍으로 갖는 복합 클래스다. 즉, `LocalDateTime`은 날짜와 시간을 모두 표현할 수 있으며 다음 코드에서 보여주는 것처럼 직접 `LocalDateTime`을 만드는 방법도 있고 날짜와 시간을 조합하는 방법도 있다.
|
||||
|
||||
###### 예제 12-4. LocalDateTime을 직접 만드는 방법과 날짜와 시간을 조합하는 방법
|
||||
```java
|
||||
// 2017-09-21T13:45:20
|
||||
LocalDateTime dt1 = LocalDateTime.of(2017, Month.SEPTEMBER, 21, 13, 45, 20);
|
||||
LocalDateTime dt2 = LocalDateTime.of(date, time);
|
||||
LocalDateTime dt3 = date.atTime(13, 45, 20);
|
||||
LocalDateTime dt4 = date.atTime(time);
|
||||
LocalDateTime dt5 = time.atDate(date);
|
||||
```
|
||||
|
||||
`LocalDate`의 `atTime` 메서드에 시간을 제공하거나 `LocalTime`의 `atDate` 메서드에 날짜를 제공해서 `LocalDateTime`을 만드는 방법도 있다. `LocalDateTime`의 `toLocalDate`나 `toLocalTime` 메서드로 `LocalDate`나 `LocalTime` 인스턴스를 추출할 수 있다.
|
||||
|
||||
```java
|
||||
LocalDate date1 = dt1.toLocalDate(); // 2017-09-21
|
||||
LocalTime time1 = dt1.toLocalTime(); // 13:45:30
|
||||
```
|
||||
|
||||
### 12.1.3 Instant 클래스 : 기계의 날짜와 시간
|
||||
사람은 보통 주, 날짜, 시간, 분으로 날짜와 시간을 계산한다. 하지만 기계에서는 이와 같은 단위로 시간을 표현하기가 어렵다. 기계의 관점에서는 연속된 시간에서 특정 지점을 하나의 큰 수로 표현하는 것이 가장 자연스러운 시간 표현 방법이다. 새로운 `java.util.Instant` 클래스에서는 이와 같은 기계적인 관점에서 시간을 표현한다. 즉, `Instant` 클래스는 `유닉스 에포크 시간(Unix epoch time - 1970년 1월 1일 0시 0분 0초 UTC)`을 기준으로 특정 지점까지의 시간을 초로 표현한다.
|
||||
|
||||
팩토리 메서드 `ofEpochSecond`에 초를 넘겨줘서 `Instant` 클래스 인스턴스를 만들 수 있다. `Instant` 클래스는 나노초(10억분의 1초)의 정밀도를 제공한다. 또한 오버로드된 `ofEpochSecond` 메서드 버전에서는 두 번째 인수를 이용해서 나노초 단위로 시간을 보정할 수 있다. 두 번째 인수에는 0에서 999,999,999 사이의 값을 지정할 수 있다. 따라서 다음 네 가지 `ofEpochSecond` 호출 코드는 같은 `Instant`를 반환한다.
|
||||
|
||||
```java
|
||||
Instant.ofEpochSecond(3);
|
||||
Instant.ofEpochSecond(3, 0);
|
||||
Instant.ofEpochSecond(2, 1_000_000_000); // 2초 이후의 1억 나노초(1초)
|
||||
Instant.ofEpochSecond(4, -1_000_000_000); // 4초 이전의 1억 나노초(1초)
|
||||
```
|
||||
|
||||
`LocalDate` 등을 포함하여 사람이 읽을 수 있는 날짜 시간 클래스에서 그랬던 것처럼 `Instant` 클래스도 사람이 확인할 수 있도록 시간을 표시해주는 정적 팩토리 메서드 `now`를 제공한다. 하지만 `Instant`는 기계 전용의 유틸리티라는 점을 기억하자. 즉, `Instant`는 초와 나노초 정보를 포함한다. 따라서 `Instant`는 사람이 읽을 수 있는 시간 정보를 제공하지 않는다. 예를 들어 다음 코드를 보자.
|
||||
|
||||
```java
|
||||
int day = Instant.now().get(ChronoField.DAY_OF_MONTH);
|
||||
```
|
||||
|
||||
위 코드는 다음과 같은 예외를 일으킨다.
|
||||
|
||||
`java.time.temporal.UnsupportedTemporalTypeException: Unsupported field: DayOfMonth`
|
||||
|
||||
`Instant`에서는 `Duration`과 `Period` 클래스를 함께 활용할 수 있다.
|
||||
|
||||
### 12.1.4 Duration과 Period 정의
|
||||
지금까지 살펴본 모든 클래스는 `Temporal` 인터페이스를 구현하는데, `Temporal` 인터페이스는 특정 시간을 모델링하는 객체의 값을 어떻게 읽고 조작할지 정의한다. 이번에는 두 시간 객체 사이의 지속시간 `duration`을 만들어볼 차례다. `Duration` 클래스의 정적 팩토리 메서드 `between`으로 두 시간 객체 사이의 지속시간을 만들 수 있다. 다음 코드에서 보여주는 것처럼 두 개의 `LocalTime`, 두 개의 `LocalDateTime`, 또는 두 개의 `Instant`로 `Duration`을 만들 수 있다.
|
||||
|
||||
```java
|
||||
Duration d1 = Duration.between(time1, time2);
|
||||
Duration d2 = Duration.between(dateTime1, dateTime2);
|
||||
Duration d3 = Duration.between(instant1, instant2);
|
||||
```
|
||||
|
||||
`LocalDateTime`은 사람이 사용하도록, `Instant`는 기계가 사용하도록 만들어진 클래스로 두 인스턴스는 서로 혼합할 수 없다. 또한 `Duration` 클래스는 초와 나노초로 시간 단위를 표현하므로 `between` 메서드에 `LocalDate`를 전달할 수 없다. 년, 월, 일로 시간을 표현할 때는 `Period` 클래스를 사용한다. 즉, `Period` 클래스의 팩토리 메서드 `between`을 이용하면 두 `LocalDate`의 차이를 확인할 수 있다.
|
||||
|
||||
```java
|
||||
Period tenDays = Period.between(LocalDate.of(2017, 9, 11), LocalDate.of(2017, 9, 21));
|
||||
```
|
||||
|
||||
마지막으로 `Duration`과 `Period` 클래스는 자신의 인스턴스를 만들 수 있도록 다양한 팩토리 메서드를 제공한다. 즉, 다음 예제에서 보여주는 것처럼 두 시간 객체를 사용하지 않고도 `Duration`과 `Period` 클래스를 만들 수 있다.
|
||||
|
||||
###### 예제 12-5. Duration과 Period 만들기
|
||||
```java
|
||||
Duration threeMinutes = Duration.ofMinutes(3);
|
||||
Duration threeMinutes = Duration.of(3, ChronoUnit.MINUTES);
|
||||
|
||||
Period tenDays = Period.ofDays(10);
|
||||
Period threeWeeks = Period.ofWeeks(3);
|
||||
Period twoYearsSixMonthsOneDay = Period.of(2, 6, 1);
|
||||
```
|
||||
|
||||
`표 12-1`은 `Duration`과 `Period` 클래스가 공통으로 제공하는 메서드를 보여준다.
|
||||
|
||||
##### 표 12-1. 간격을 표현하는 날짜와 시간 클래스의 공통 메서드
|
||||
|메서드|정적|설명|
|
||||
|-|-|-|
|
||||
|between|네|두 시간 사이의 간격을 생성함|
|
||||
|from|네|시간 단위로 간격을 생성함|
|
||||
|of|네|주어진 구성 요소에서 간격 인스턴스를 생성함|
|
||||
|parse|네|문자열을 파싱해서 간격 인스턴스를 생성함|
|
||||
|addTo|아니오|현재 값의 복사본을 생성한 다음에 지정된 `Temporal` 객체에 추가함|
|
||||
|get|아니오|현재 간격 정보값을 읽음|
|
||||
|isNegative|아니오|간격이 음수인지 확인함|
|
||||
|isZero|아니오|간격이 0인지 확인함|
|
||||
|minus|아니오|현재값에서 주어진 시간을 뺀 복사본을 생성함|
|
||||
|multipliedBy|아니오|현재값에 주어진 값을 곱한 복사본을 생성함|
|
||||
|negated|아니오|주어진 값의 부호를 반전한 복사본을 생성함|
|
||||
|plus|아니오|현재값에 주어진 시간을 더한 복사본을 생성함|
|
||||
|subtractFrom|아니오|지정된 `Temporal` 객체에서 간격을 뺌|
|
||||
|
||||
지금까지 살펴본 모든 클래스는 불변이다. 불변 클래스는 함수형 프로그래밍 그리고 스레드 안전성과 도메인 모델의 일관성을 유지하는 데 좋은 특징이다. 하지만 새로운 날짜와 시간 API에서는 변경된 객체 버전을 만들 수 있는 메서드를 제공한다. 예를 들어 기존 `LocalDate` 인스턴스에 3일을 더해야 하는 상황이 발생할 수 있다. 또한 `dd/MM/yyyy` 같은 형식으로 날짜와 시간 포매터를 만드는 방법, 프로그램적으로 포매터를 만드는 방법, 포매터로 날짜를 파싱하고 출력하는 방법도 살펴본다.
|
||||
|
||||
---
|
||||
|
||||
## 12.2 날짜 조정, 파싱, 포매팅
|
||||
`withAttribute` 메서드로 기존의 `LocalDate`를 바꾼 버전을 직접 간단하게 만들 수 있다. 다음 코드에서는 바뀐 속성을 포함하는 새로운 객체를 반환하는 메서드를 보여준다. 모든 메서드는 기존 객체를 바꾸지 않는다.
|
||||
|
||||
###### 예제 12-6. 절대적인 방식으로 LocalDate의 속성 바꾸기
|
||||
```java
|
||||
LocalDate date1 = LocalDate.of(2017, 9, 21); // 2017-09-21
|
||||
LocalDate date2 = date1.withYear(2011); // 2011-09-21
|
||||
LocalDate date3 = date1.withDayOfMonth(25); // 2011-09-25
|
||||
LocalDate date4 = date1.with(ChronoField.MONTH_OF_YEAR, 2); // 2011-02-25
|
||||
```
|
||||
|
||||
`예제 12-6`의 마지막 행에서 보여주는 것처럼 첫 번째 인수로 `TemporalField`를 갖는 메서드를 사용하면 좀 더 범용적으로 메서드를 활용할 수 있다. 마지막 `with` 메서드는 `예제 12-2`의 `get` 메서드와 쌍을 이룬다. 이들 두 메서드는 날짜와 시간 API의 모든 클래스가 구현하는 `Temporal` 인터페이스에 정의되어 있다. `Temporal` 인터페이스는 `LocalDate`, `LocalTime`, `LocalDateTime`, `Instant`처럼 특정 시간을 정의한다. 정확히 표현하자면 `get`과 `with` 메서드로 `Temporal` 객체의 필드값을 읽거나 고칠 수 있다. 어떤 `Temporal` 객체가 지정된 필드를 지원하지 않으면 `UnsupportedTemporalTypeException`이 발생한다. 예를 들어 `Instant`에 `ChronoField.MONTH_OF_YEAR`를 사용하거나 `LocalDate`에 `ChronoField.NANO_OF_SECOND`를 사용하면 예외가 발생한다.
|
||||
|
||||
선언형으로 `LocalDate`를 사용하는 방법도 있다. 예를 들어 다음 예제처럼 지정된 시간을 추가하거나 뺄 수 있다.
|
||||
|
||||
###### 예제 12-7. 상대적인 방식으로 LocalDate 속성 바꾸기
|
||||
```java
|
||||
LocalDate date1 = LocalDate.of(2017, 9, 21); // 2017-09-21
|
||||
LocalDate date2 = date1.plusWeeks(1); // 2017-09-28
|
||||
LocalDate date3 = date2.minusYears(6); // 2011-09-28
|
||||
LocalDate date4 = date3.plus(6, ChronoUnit.MONTHS); // 2012-03-28
|
||||
```
|
||||
|
||||
`예제 12-7`에서는 `with`, `get` 메서드와 비슷한 `plus`, `minus` 메서드를 사용했다. `plus`, `minus` 메서드도 `Temporal` 인터페이스에 정의되어 있다. 이들 메서드를 이용해서 `Temporal`을 특정 시간만큼 앞뒤로 이동시킬 수 있다. 메서드의 인수에 숫자와 `TemporalUnit`을 활용할 수 있다. `ChronoUnit` 열거형은 `TemporalUnit` 인터페이스를 쉽게 활용할 수 있는 구현을 제공한다.
|
||||
|
||||
`LocalDate`, `LocalTime`, `LocalDateTime`, `Instant` 등 날짜와 시간을 표현하는 모든 클래스는 서로 비슷한 메서드를 제공한다. `표 12-2`는 이들 공통 메서드를 설명한다.
|
||||
|
||||
##### 표 12-2 특정 시점을 표현하는 날짜 시간 클래스의 공통 메서드
|
||||
|메서드|정적|설명|
|
||||
|-|-|-|
|
||||
|from|예|주어진 `Temporal` 객체를 이용해서 클래스의 인스턴스를 생성함|
|
||||
|now|예|시스템 시계로 `Temporal` 객체를 생성함|
|
||||
|of|예|주어진 구성 요소에서 `Temporal` 객체의 인스턴스를 생성함|
|
||||
|parse|예|문자열을 파싱해서 `Temporal` 객체를 생성함|
|
||||
|atOffset|아니오|시간대 오프셋과 `Temporal` 객체를 합침|
|
||||
|atZone|아니오|시간대 오프셋과 `Temporal` 객체를 합침|
|
||||
|format|아니오|지정된 포매터를 이용해서 `Temporal` 객체를 문자열로 변환함(`Instant`는 지원하지 않음)|
|
||||
|get|아니오|`Temporal` 객체의 상태를 읽음|
|
||||
|minus|아니오|특정 시간을 뺀 `Temporal` 객체의 복사본을 생성함|
|
||||
|plus|아니오|특정 시간을 더한 `Temporal` 객체의 복사본을 생성함|
|
||||
|with|아니오|일부 상태를 바꾼 `Temporal` 객체의 복사본을 생성함|
|
||||
|
||||
##### 퀴즈 12-1. LocalDate 조정
|
||||
다음 코드를 실행했을 때 `date`의 변숫값은?
|
||||
```java
|
||||
LocalDate date = LocalDate.of(2014, 3, 18);
|
||||
date = date.with(ChronoField.MONTH_OF_YEAR, 9);
|
||||
date = date.plusYears(2).minusDays(10);
|
||||
date.withYear(2011);
|
||||
```
|
||||
|
||||
`정답 : 2016-09-08`
|
||||
|
||||
### 12.2.1 TemporalAdjusters 사용하기
|
||||
지금까지 살펴본 날짜 조정 기능은 비교적 간단한 편에 속한다. 때로는 다음 주 일요일, 돌아오는 평일, 어떤 달의 마지막 날 등 좀 더 복잡한 날짜 조정 기능이 필요할 것이다. 이때는 오버로드된 버전의 `with` 메서드에 좀 더 다양한 동작을 수행할 수 있도록 하는 기능을 제공하는 `TemporalAdjuster`를 전달하는 방법으로 문제를 해결할 수 있다. 날짜와 시간 API는 다양한 상황에서 사용할 수 있도록 다양한 `TemporalAdjuster`를 제공한다. `예제 12-8`에서 보여주는 것처럼 `TemporalAdjusters`에서 정의하는 정적 팩토리 메서드로 이들 기능을 이용할 수 있다.
|
||||
|
||||
###### 예제 12-8. 미리 정의된 TemporalAdjusters 사용하기
|
||||
```java
|
||||
import static java.time.temporal.TemporalAdjusters.*;
|
||||
LocalDate date1 = LocalDate.of(2014, 3, 18); // 2014-03-18
|
||||
LocalDate date2 = date1.with(nextOrSame(DayOfWeek.SUNDAY)); // 2014-03-23
|
||||
LocalDate date3 = date2.with(lastDayOfMonth()); // 2014-03-31
|
||||
```
|
||||
|
||||
- `TemporalAdjuster`는 인터페이스며, `TemporalAdjusters`는 여러 `TemporalAdjuster`를 반환하는 정적 팩토리 메서드를 포함하는 클래스이므로 혼동하지 않도록 주의하자. 둘 다 `java.time.temporal` 패키지에 포함되어 있다.
|
||||
|
||||
`표 12-3`은 다양한 `TemporalAdjusters`의 팩토리 메서드로 만들 수 있는 `TemporalAdjuster` 리스트를 보여준다.
|
||||
|
||||
##### 표 12-3. TemporalAdjusters 클래스의 팩토리 메서드
|
||||
|메서드|설명|
|
||||
|-|-|
|
||||
|dayOfWeekInMonth|서수 요일에 해당하는 날짜를 반환하는 `TemporalAdjuster`를 반환함(음수를 사용하면 월의 끝에서 거꾸로 계산)|
|
||||
|firstDayOfMonth|현재 달의 첫 번째 날짜를 반환하는 `TemporalAdjuster`를 반환함|
|
||||
|firstDayOfNextMonth|다음 달의 첫 번째 날짜를 반환하는 `TemporalAdjuster`를 반환함|
|
||||
|firstDayOfNextYear|내년의 첫 번째 날짜를 반환하는 `TemporalAdjuster`를 반환함|
|
||||
|firstDayOfYear|올해의 첫 번째 날짜를 반환하는 `TemporalAdjuster`를 반환함|
|
||||
|firstInMonth|현재 달의 첫 번째 요일에 해당하는 날짜를 반환하는 `TemporalAdjuster`를 반환함|
|
||||
|lastDayOfMonth|현재 달의 마지막 날짜를 반환하는 `TemporalAdjuster`를 반환함|
|
||||
|lastDayOfNextMonth|다음 달의 마지막 날짜를 반환하는 `TemporalAdjuster`를 반환함|
|
||||
|lastDayOfNextYear|다음 해의 마지막 날짜를 반환하는 `TemporalAdjuster`를 반환함|
|
||||
|lastDayOfYear|올해의 마지막 날짜를 반환하는 `TemporalAdjuster`를 반환함|
|
||||
|lastInMonth|현재 달의 마지막 요일에 해당하는 날짜를 반환하는 `TemporalAdjuster`를 반환함|
|
||||
|next|현재 달에서 현재 날짜 이후로 지정한 요일이 처음으로 나타나는 날짜를 반환하는 `TemporalAdjuster`를 반환함|
|
||||
|previous|현재 달에서 현재 날짜 이후로 지정한 요일이 이전으로 나타나는 날짜를 반환하는 `TemporalAdjuster`를 반환함|
|
||||
|nextOrSame|현재 날짜 이후로 지정한 요일이 처음으로 나타나는 날짜를 반환하는 `TemporalAdjuster`를 반환함(현재 날짜도 포함)|
|
||||
|previousOrSame|현재 날짜 이후로 지정한 요일이 이전으로 나타나는 날짜를 반환하는 `TemporalAdjuster`를 반환함(현재 날짜도 포함)|
|
||||
|
||||
위 예제에서 확인할 수 있는 것처럼 `TemporalAdjuster`를 이용하면 좀 더 복잡한 날짜 조정 기능을 직관적으로 해결할 수 있다. 그뿐만 아니라 필요한 기능이 정의되어 있지 않을 때는 비교적 쉽게 커스텀 `TemporalAdjuster` 구현을 만들 수 있다. 실제로 `TemporalAdjuster` 인터페이스는 다음처럼 하나의 메서드만 정의한다(하나의 메서드만 정의하므로 함수형 인터페이스다).
|
||||
|
||||
###### 예제 12-9. TemporalAdjuster 인터페이스
|
||||
```java
|
||||
@FunctionalInterface
|
||||
public interface TemporalAdjuster {
|
||||
Temporal adjustInto(Temporal temporal);
|
||||
}
|
||||
```
|
||||
|
||||
- 표의 설명만으로 메서드의 기능이 이해되지 않는다면 다양한 예제가 포함되어 있는 [API 문서](http://goo.gl/e1krg1)를 참고하자.
|
||||
|
||||
`TemporalAdjuster` 인터페이스 구현은 `Temporal` 객체를 어떻게 다른 `Temporal` 객체로 변환할지 정의한다. 결국 `TemporalAdjuster` 인터페이스를 `UnaryOperator<Temporal>`과 같은 형식으로 간주할 수 있다.
|
||||
|
||||
##### 퀴즈 12-2. 커스텀 TemporalAdjuster 구현하기
|
||||
`TemporalAdjuster` 인터페이스를 구현하는 `NextWorkingDay` 클래스를 구현하시오. 이 클래스는 날짜를 하루씩 다음날로 바꾸는데 이때 토요일과 일요일은 건너뛴다. 즉, 다음 코드를 실행하면 다음날로 이동한다.
|
||||
|
||||
```java
|
||||
date = date.with(new NextWorkingDay());
|
||||
```
|
||||
|
||||
`정답`
|
||||
```java
|
||||
public class NextWorkingDay implements TemporalAdjuster {
|
||||
|
||||
@Override
|
||||
public Temporal adjustInto(Temporal temporal) {
|
||||
DayOfWeek dow = DayOfWeek.of(temporal.get(ChronoField.DAY_OF_WEEK)); // 현재 날짜 읽기
|
||||
int dayToAdd = 1; // 보통은 하루 추가
|
||||
if (dow == DayOfWeek.FRIDAY) {
|
||||
dayToAdd = 3; // 그러나 오늘이 금요일이면 3일 추가
|
||||
} else if (dow == DayOfWeek.SATURDAY) {
|
||||
dayToAdd = 2; // 토요일이면 2일 추가
|
||||
}
|
||||
return temporal.plus(dayToAdd, ChronoUnit.DAYS); // 적정한 날 수만큼 추가된 날짜를 반환
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
`TemporalAdjuster`는 함수형 인터페이스이므로 람다 표현식을 이용할 수 있다. 만일 `TemporalAdjuster`를 람다 표현식으로 정의하고 싶다면 다음 코드에서 보여주는 것처럼 `UnaryOperator<LocalDate>`를 인수로 받는 `TemporalAdjusters` 클래스의 정적 팩토리 메서드 `ofDateAdjuster`를 사용하는 것이 좋다.
|
||||
|
||||
```java
|
||||
TemporalAdjuster nextWorkingDay = TemporalAdjusters.ofDateAdjuster(
|
||||
temporal -> {
|
||||
...
|
||||
});
|
||||
date = date.with(nextWorkingDay);
|
||||
```
|
||||
|
||||
자주 사용하는 또 다른 동작으로 각자의 상황에 맞는 다양한 형식으로 날짜와 시간 객체를 출력해야 할 때가 있다. 반면 문자열로 표현된 날짜를 날짜 객체로 다시 변환해야 할 때도 있다. 다음으로는 새로운 날짜와 시간 API로 이와 같은 변환을 수행하는 방법을 살펴본다.
|
||||
|
||||
### 12.2.2 날짜와 시간 객체 출력과 파싱
|
||||
날짜와 시간 관련 작업에서 포매팅과 파싱은 서로 떨어질 수 없는 관계다. 심지어 포매팅과 파싱 전용 패키지인 `java.time.format`이 새로 추가되었다. 이 패키지에서 가장 중요한 클래스는 `DateTimeFormatter`다. 정적 팩토리 메서드와 상수를 이용해서 손쉽게 포매터를 만들 수 있다. `DateTimeFormatter` 클래스는 `BASIC_ISO_DATE`와 `ISO_LOCAL_DATE` 등의 상수를 미리 정의하고 있다. `DateTimeFormatter`를 이용해서 날짜나 시간을 특정 형식의 문자열로 만들 수 있다. 다음은 두 개의 서로 다른 포매터로 문자열을 만드는 예제다.
|
||||
|
||||
```java
|
||||
LocalDate date = LocalDate.of(2014, 3, 18);
|
||||
String s1 = date.format(DateTimeFormatter.BASIC_ISO_DATE); // 20140318
|
||||
String s2 = date.format(DateTimeFormatter.ISO_LOCAL_DATE); // 2014-03-18
|
||||
```
|
||||
|
||||
반대로 날짜나 시간을 표현하는 문자열을 파싱해서 날짜 객체를 다시 만들 수 있다. 날짜와 시간 API에서 특정 시점이나 간격을 표현하는 모든 클래스의 팩토리 메서드 `parse`를 이용해서 문자열을 날짜 객체로 만들 수 있다.
|
||||
|
||||
```java
|
||||
LocalDate date1 = LocalDate.parse("20140318", DateTimeFormatter.BASIC_ISO_DATE);
|
||||
LocalDate date2 = LocalDate.parse("2014-03-18", DateTimeFormatter.ISO_LOCAL_DATE);
|
||||
```
|
||||
|
||||
기존의 `java.util.DateFormat` 클래스와 달리 모든 `DateTimeFormatter`는 스레드에서 안전하게 사용할 수 있는 클래스다. 또한 다음 예제에서 보여주는 것처럼 `DateTimeFormatter` 클래스는 특정 패턴으로 포매터를 만들 수 있는 정적 팩토리 메서드도 제공한다.
|
||||
|
||||
###### 예제 12-10. 패턴으로 DateTimeFormatter 만들기
|
||||
```java
|
||||
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("dd/MM/yyyy");
|
||||
LocalDate date1 = LocalDate.of(2014, 3, 18);
|
||||
String formattedDate = date1.format(formatter);
|
||||
LocalDate date2 = LocalDate.parse(formattedDate, formatter);
|
||||
```
|
||||
|
||||
`LocalDate`의 `format` 메서드는 요청 형식의 패턴에 해당하는 문자열을 생성한다. 그리고 정적 메서드 `parse`는 같은 포매터를 적용해서 생성된 문자열을 파싱함으로써 다시 날짜를 생성한다. 다음 코드에서 보여주는 것처럼 `ofPattern` 메서드도 `Locale`로 포매터를 만들 수 있도록 오버로드된 메서드를 제공한다.
|
||||
|
||||
###### 예제 12-11. 지역화된 DateTimeFormatter 만들기
|
||||
```java
|
||||
DateTimeFormatter italianFormatter =
|
||||
DateTimeFormatter.ofPattern("d. MMMM yyyy", Locale.ITALIAN);
|
||||
LocalDate date1 = LocalDate.of(2014, 3, 18);
|
||||
String formattedDate = date1.format(italianFormatter); // 18. marzo 2014
|
||||
LocalDate date2 = LocalDate.parse(formattedDate, italianFormatter);
|
||||
```
|
||||
|
||||
`DateTimeFormatterBuilder` 클래스로 복합적인 포매터를 정의해서 좀 더 세부적으로 포매터를 제어할 수 있다. 즉, `DateTimeFormatterBuilder` 클래스로 대소문자를 구분하는 파싱, 관대한 규칙을 적용하는 파싱(정해진 형식과 정확하게 일치하지 않는 입력을 해석할 수 있도록 체험적 방식의 파서 사용), 패딩, 포매터의 선택사항 등을 활용할 수 있다. 예를 들어 `예제 12-11`에서 사용한 `italianFormatter`를 `DateTimeFormatterBuilder`에 이용하면 프로그램적으로 포매터를 만들 수 있다.
|
||||
|
||||
###### 예제 12-12. DateTimeFormatter 만들기
|
||||
```java
|
||||
DateTimeFormatter italianFormatter = new DateTimeFormatterBuilder()
|
||||
.appendText(ChronoField.DAY_OF_MONTH)
|
||||
.appendLiteral(". ")
|
||||
.appendText(ChronoField.MONTH_OF_YEAR)
|
||||
.appendLiteral(" ")
|
||||
.appendText(ChronoField.YEAR)
|
||||
.parseCaseInsensitive()
|
||||
.toFormatter(Locale.ITALIAN);
|
||||
```
|
||||
|
||||
지금까지 시간과 간격으로 날짜를 만들고, 조작하고, 포맷하는 방법을 살펴봤다. 그러나 날짜와 시간 관련 세부사항을 처리하는 방법(예를 들면 다양한 시간대를 처리하거나 다른 캘린더 시스템 사용)은 아직 살펴보지 않았다. 다음으로는 새로운 날짜와 시간 API로 다양한 시간대와 캘린더를 활용하는 방법을 설명한다.
|
||||
|
||||
---
|
||||
|
||||
## 12.3 다양한 시간대와 캘린더 활용 방법
|
||||
지금까지 살펴본 모든 클래스에서는 시간대와 관련한 정보가 없었다. 새로운 날짜와 시간 API의 큰 편리함 중 하나는 시간대를 간단하게 처리할 수 있다는 것이다. 기존의 `java.util.TimeZone`을 대체할 수 있는 `java.time.ZoneId` 클래스가 새롭게 등장햇다. 새로운 클래스를 이용하면 `서머타임(Daylight Saving Time - DST)` 같은 복잡한 사항이 자동으로 처리된다. 날짜와 시간 API에서 제공하는 다른 클래스와 마찬가지로 `ZoneId`는 불변 클래스다.
|
||||
|
||||
### 12.3.1 시간대 사용하기
|
||||
표준 시간이 같은 지역을 묶어서 **시간대(time zone)** 규칙 집합을 정의한다. `ZoneRules` 클래스에는 약 40개 정도의 시간대가 있다. `ZoneId`의 `getRules()`를 이용해서 해당 시간대의 규정을 획득할 수 있다. 다음처럼 지역 ID로 특정 `ZoneId`를 구분한다.
|
||||
|
||||
```java
|
||||
ZoneId romeZone = ZoneId.of("Europe/Rome");
|
||||
```
|
||||
|
||||
지역 ID는 `{지역}/{도시}` 형식으로 이루어지며 `IANA Time Zone Database`에서 제공하는 지역 집합 정보를 사용한다(https://www.iana.org/time-zones 참고). 다음 코드에서 보여주는 것처럼 `ZoneId`의 새로운 메서드인 `toZoneId`로 기존의 `TimeZone` 객체를 `ZoneId` 객체로 변환할 수 있다.
|
||||
|
||||
```java
|
||||
ZoneId zoneId = TimeZone.getDefault().toZoneId();
|
||||
```
|
||||
|
||||
다음 코드에서 보여주는 것처럼 `ZoneId` 객체를 얻은 다음에는 `LocalDate`, `LocalDateTime`, `Instant`를 이용해서 `ZonedDateTime` 인스턴스로 변환할 수 있다. `ZonedDateTime`은 지정한 시간대에 상대적인 시점을 표현한다.
|
||||
|
||||
###### 예제 12-13. 특정 시점에 시간대 적용
|
||||
```java
|
||||
LocalDate date = LocalDate.of(2014, 3, 18);
|
||||
ZonedDateTime zdt1 = date.atStartOfDay(romeZone);
|
||||
LocalDateTime dateTime = LocalDateTime.of(2014, Month.MARCH, 18, 13, 45);
|
||||
ZonedDateTime zdt2 = dateTime.atZone(romeZone);
|
||||
Instant instant = Instant.now();
|
||||
ZonedDateTime zdt3 = instant.atZone(romeZone);
|
||||
```
|
||||
|
||||
`그림 12-1`에서 보여주는 `ZonedDateTime`의 컴포넌트를 보면 `LocalDate`, `LocalTime`, `LocalDateTime`, `ZoneId(ZoneRegion)`의 차이를 쉽게 이해할 수 있다.
|
||||
|
||||
##### 그림 12-1. ZonedDateTime의 개념
|
||||
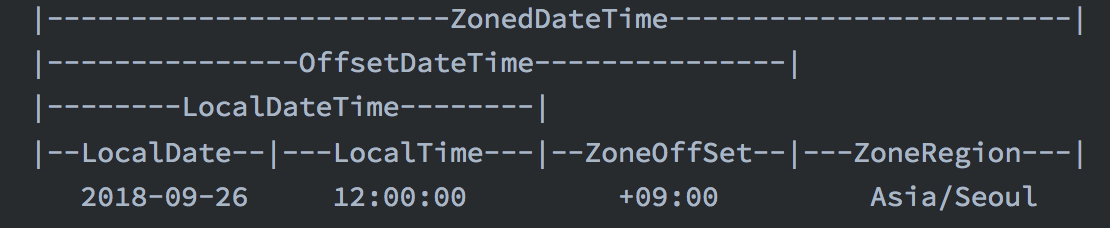
|
||||
[ZonedDateTime 참고 링크](https://perfectacle.github.io/2018/09/26/java8-date-time/)
|
||||
|
||||
`ZoneId`를 이용해서 `LocalDateTime`을 `Instant`로 바꾸는 방법도 있다.
|
||||
|
||||
다음처럼 변환하는 방법도 있다.
|
||||
|
||||
```java
|
||||
Instant instant = Instant.now();
|
||||
LocalDateTime timeFromInstant = LocalDateTime.ofInstant(instant, romeZone);
|
||||
```
|
||||
|
||||
기존의 `Date` 클래스를 처리하는 코드를 사용해야 하는 상황이 있을 수 있으므로 `Instant`로 작업하는 것이 유리하다. 폐기된 API와 새 날짜와 시간 API 간의 동작에 도움이 되는 `toInstant()`, 정적 메서드 `fromInstant()` 두 개의 메서드가 있다.
|
||||
|
||||
### 12.3.2 UTC/Greenwich 기준의 고정 오프셋
|
||||
때로는 `UTC(Universal Time Coordinated - 협정 세계시)/GMT(Greenwich Mean Time - 그리니치 표준시)`를 기준으로 시간대를 표현하기도 한다. 예를 들어 '뉴욕은 런던보다 5시간 느리다'라고 표현할 수 있다. `ZoneId`의 서브클래스인 `ZoneOffset` 클래스로 런던의 그리니치 0도 자오선과 시간값의 차이를 표현할 수 있다.
|
||||
|
||||
```java
|
||||
ZoneOffset newYorkOffset = ZoneOffset.of("-05:00");
|
||||
```
|
||||
|
||||
실제로 미국 동부 표준시의 오프셋값은 `-05:00`이다. 하지만 위 예제에서 정의한 `ZoneOffset`으로는 서머타임을 제대로 처리할 수 없으므로 권장하지 않는 방식이다. `ZoneOffset`은 `ZoneId`이므로 `예제 12-13`처럼 `ZoneOffset`을 사용할 수 있다. 또한 `ISO-8601` 캘린더 시스템에서 정의하는 `UTC/GMT`와 오프셋으로 날짜와 시간을 표현하는 `OffsetDateTime`을 만드는 방법도 있다.
|
||||
|
||||
```java
|
||||
LocalDateTime dateTime = LocalDateTime.of(2014, Month.MARCH, 18, 13, 45);
|
||||
OffsetDateTime dateTimeInNewYork = OffsetDateTime.of(date, newYorkOffset);
|
||||
```
|
||||
|
||||
새로운 날짜와 시간 API는 ISO 캘린더 시스템에 기반하지 않은 정보도 처리할 수 있는 기능을 제공한다.
|
||||
|
||||
- `ISO-8601`과 관련한 자세한 정보는 `http://en.wikipedia.org/wiki/ISO_8601`을 참고하자.
|
||||
|
||||
### 12.3.3 대안 캘린더 시스템 사용하기
|
||||
`ISO-8601` 캘린더 시스템은 실질적으로 전 세계에서 통용된다. 하지만 자바 8에서는 추가로 4개의 캘린더 시스템을 제공한다. `ThaiBuddhistDate`, `MinguoDate`,`JapaneseDate`, `HijrahDate` 4개의 클래스가 각각의 캘린더 시스템을 대표한다. 위 4개의 클래스와 `LocalDate` 클래스는 `ChronoLocalDate` 인터페이스를 구현하는데, `ChronoLocalDate`는 임의의 연대기에서 특정 날짜를 표현할 수 있는 기능을 제공하는 인터페이스다. `LocalDate`를 이용해서 이들 4개의 클래스 중 하나의 인스턴스를 만들 수 있다. 일반적으로 다음 코드에서 보여주는 것처럼 정적 메서드로 `Temporal` 인스턴스를 만들 수 있다.
|
||||
|
||||
```java
|
||||
LocalDate date = LocalDate.of(2014, Month.MARCH, 18);
|
||||
JapaneseDate japaneseDate = JapaneseDate.from(date);
|
||||
```
|
||||
|
||||
또는 특정 `Locale`과 `Locale`에 대한 날짜 인스턴스로 캘린더 시스템을 만드는 방법도 있다. 새로운 날짜와 시간 API에서 `Chronology`는 캘린더 시스템을 의미하며 정적 팩토리 메서드 `ofLocale`을 이용해서 `Chronology`의 인스턴스를 획득할 수 있다.
|
||||
|
||||
```java
|
||||
Chronology japaneseChronology = Chronology.ofLocale(Locale.JAPAN);
|
||||
ChronoLocalDate now = japaneseChronology.dateNow();
|
||||
```
|
||||
|
||||
날짜와 시간 API의 설계자는 `ChronoLocalDate`보다는 `LocalDate`를 사용하라고 권고한다. 예를 들어 개발자는 1년은 12개월로 이루어져 있으며 1달은 31일 이하이거나, 최소한 1년은 정해진 수의 달로 이루어졌을 것이라고 가정할 수 있다. 하지만 이와 같은 가정은 특히 멀티캘린더 시스템에서는 적용되지 않는다. 따라서 프로그램의 입출력을 지역화하는 상황을 제외하고는 모든 데이터 저장, 조작, 비즈니스 규칙 해석 등의 작업에서 `LocalDate`를 사용해야 한다.
|
||||
|
||||
#### 이슬람력
|
||||
자바 8에 추가된 새로운 캘린더 중 `HijrahDate(이슬람력)`가 가장 복잡한데 이슬람력에서는 변형(variant)이 있기 때문이다. `Hijrah` 캘린더 시스템은 태음월(lunar month)에 기초한다. 새로운 달(month)을 결정할 때 새로운 달(month)을 전 세계 어디에서나 볼 수 있는지 아니면 사우디아라비아에서 처음으로 새로운 달을 볼 수 있는지 등의 변형 방법을 결정하는 메서드가 있다. `withVariant` 메서드로 원하는 변형 방법을 선택할 수 있다. 자바 8에는 `HijrahDate`의 표준 변형 방법으로 `UmmAl-Qura`를 제공한다.
|
||||
|
||||
다음 코드는 현재 이슬람 연도의 시작과 끝을 ISO 날짜로 출력하는 예제다.
|
||||
|
||||
```java
|
||||
HijrahDate ramadanDate = HijrahDate.now()
|
||||
.with(ChronoField.DAY_OF_MONTH, 1)
|
||||
.with(ChronoField.MONTH_OF_YEAR, 9); // 현재 Hijrah 날짜를 얻음. 얻은 날짜를 Ramadan의 첫 번째 날, 즉 9번째 달로 바꿈
|
||||
System.out.println("Ramadan starts on " +
|
||||
IsoChronology.INSTANCE.date(ramadanDate) + // INSTANCE는 IsoChronology 클래스의 정적 인스턴스임
|
||||
" and ends on " +
|
||||
IsoChronology.INSTANCE.date(ramadanDate.with(TemporalAdjusters.lastDayOfMonth()))); // Ramadan 1438은 2017-05-26에 시작해서 2017-06-24에 종료됨.
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 12.4 마치며
|
||||
- 자바 8 이전 버전에서 제공하는 기존의 `java.util.Date` 클래스와 관련 클래스에서는 여러 불일치점들과 가변성, 어설픈 오프셋, 기본값, 잘못된 이름 결정 등의 설계 결함이 존재했다.
|
||||
- 새로운 날짜와 시간 API에서 날짜와 시간 객체는 모두 불변이다.
|
||||
- 새로운 API는 각각 사람과 기계가 편리하게 날짜와 시간 정보를 관리할 수 있도록 두 가지 표현 방식을 제공한다.
|
||||
- 날짜와 시간 객체를 절대적인 방법과 상대적인 방법으로 처리할 수 있으며 기존 인스턴스를 변환하지 않도록 처리 결과로 새로운 인스턴스가 생성된다.
|
||||
- `TemporalAdjuster`를 이용하면 단순히 값을 바꾸는 것 이상의 복잡한 동작을 수행할 수 있으며 자신만의 커스텀 날짜 변환 기능을 정의할 수 있다.
|
||||
- 날짜와 시간 객체를 특정 포맷으로 출력하고 파싱하는 포매터를 정의할 수 있다. 패턴을 이용하거나 프로그램으로 포매터를 만들 수 있으며 포매터는 스레드 안정성을 보장한다.
|
||||
- 특정 지역/장소에 상대적인 시간대 또는 `UTC/GMT` 기준의 오프셋을 이용해서 시간대를 정의할 수 있으며 이 시간대를 날짜와 시간 객체에 적용해서 지역화할 수 있다.
|
||||
- `ISO-8601` 표준 시스템을 준수하지 않는 캘린더 시스템도 사용할 수 있다.
|
||||
|
||||
---
|
||||
@@ -0,0 +1,21 @@
|
||||
package Chapter12;
|
||||
|
||||
import java.time.DayOfWeek;
|
||||
import java.time.LocalDate;
|
||||
import java.time.Month;
|
||||
|
||||
public class Ex12_1 {
|
||||
public static void main(String[] args) {
|
||||
LocalDate date = LocalDate.of(2017, 9, 21);
|
||||
int year = date.getYear();
|
||||
Month month = date.getMonth();
|
||||
int day = date.getDayOfMonth();
|
||||
DayOfWeek dow = date.getDayOfWeek();
|
||||
int len = date.lengthOfMonth();
|
||||
boolean leap = date.isLeapYear();
|
||||
|
||||
LocalDate today = LocalDate.now();
|
||||
|
||||
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,13 @@
|
||||
package Chapter12;
|
||||
|
||||
import java.time.LocalDate;
|
||||
import java.time.format.DateTimeFormatter;
|
||||
|
||||
public class Ex12_10 {
|
||||
public static void main(String[] args) {
|
||||
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("dd/MM/yyyy");
|
||||
LocalDate date1 = LocalDate.of(2014, 3, 18);
|
||||
String formattedDate = date1.format(formatter);
|
||||
LocalDate date2 = LocalDate.parse(formattedDate, formatter);
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,14 @@
|
||||
package Chapter12;
|
||||
|
||||
import java.time.LocalDate;
|
||||
import java.time.format.DateTimeFormatter;
|
||||
import java.util.Locale;
|
||||
|
||||
public class Ex12_11 {
|
||||
public static void main(String[] args) {
|
||||
DateTimeFormatter italianFormatter = DateTimeFormatter.ofPattern("d. MMMM yyyy", Locale.ITALIAN);
|
||||
LocalDate date1 = LocalDate.of(2014, 3, 18);
|
||||
String formattedDate = date1.format(italianFormatter); // 18. marzo 2014
|
||||
LocalDate date2 = LocalDate.parse(formattedDate, italianFormatter);
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,19 @@
|
||||
package Chapter12;
|
||||
|
||||
import java.time.format.DateTimeFormatter;
|
||||
import java.time.format.DateTimeFormatterBuilder;
|
||||
import java.time.temporal.ChronoField;
|
||||
import java.util.Locale;
|
||||
|
||||
public class Ex12_12 {
|
||||
public static void main(String[] args) {
|
||||
DateTimeFormatter italianFormatter = new DateTimeFormatterBuilder()
|
||||
.appendText(ChronoField.DAY_OF_MONTH)
|
||||
.appendLiteral(". ")
|
||||
.appendText(ChronoField.MONTH_OF_YEAR)
|
||||
.appendLiteral(" ")
|
||||
.appendText(ChronoField.YEAR)
|
||||
.parseCaseInsensitive()
|
||||
.toFormatter(Locale.ITALIAN);
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,29 @@
|
||||
package Chapter12;
|
||||
|
||||
import java.time.*;
|
||||
import java.time.chrono.HijrahDate;
|
||||
import java.time.chrono.IsoChronology;
|
||||
import java.time.temporal.ChronoField;
|
||||
import java.time.temporal.TemporalAdjusters;
|
||||
|
||||
public class Ex12_13 {
|
||||
public static void main(String[] args) {
|
||||
ZoneId romeZone = ZoneId.of("Europe/Rome");
|
||||
LocalDate date = LocalDate.of(2014, 3, 18);
|
||||
ZonedDateTime zdt1 = date.atStartOfDay(romeZone);
|
||||
LocalDateTime dateTime = LocalDateTime.of(2014, Month.MARCH, 18, 13, 45);
|
||||
ZonedDateTime zdt2 = dateTime.atZone(romeZone);
|
||||
Instant instant = Instant.now();
|
||||
ZonedDateTime zdt3 = instant.atZone(romeZone);
|
||||
|
||||
LocalDateTime timeFromInstant = LocalDateTime.ofInstant(instant, romeZone);
|
||||
|
||||
HijrahDate ramadanDate = HijrahDate.now()
|
||||
.with(ChronoField.DAY_OF_MONTH, 1)
|
||||
.with(ChronoField.MONTH_OF_YEAR, 9);
|
||||
System.out.println("Ramadan starts on " +
|
||||
IsoChronology.INSTANCE.date(ramadanDate) +
|
||||
" and ends on " +
|
||||
IsoChronology.INSTANCE.date(ramadanDate.with(TemporalAdjusters.lastDayOfMonth())));
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,14 @@
|
||||
package Chapter12;
|
||||
|
||||
import java.time.LocalDate;
|
||||
import java.time.temporal.ChronoField;
|
||||
|
||||
public class Ex12_2 {
|
||||
public static void main(String[] args) {
|
||||
LocalDate date = LocalDate.of(2017, 9, 21);
|
||||
|
||||
int year = date.get(ChronoField.YEAR);
|
||||
int month = date.get(ChronoField.MONTH_OF_YEAR);
|
||||
int day = date.get(ChronoField.DAY_OF_MONTH);
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,16 @@
|
||||
package Chapter12;
|
||||
|
||||
import java.time.LocalDate;
|
||||
import java.time.LocalTime;
|
||||
|
||||
public class Ex12_3 {
|
||||
public static void main(String[] args) {
|
||||
LocalTime time = LocalTime.of(13, 45, 20);
|
||||
int hour = time.getHour();
|
||||
int minute = time.getMinute();
|
||||
int second = time.getSecond();
|
||||
|
||||
LocalDate date = LocalDate.parse("2017-09-21");
|
||||
LocalTime time1 = LocalTime.parse("13:45:20");
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,26 @@
|
||||
package Chapter12;
|
||||
|
||||
import java.time.*;
|
||||
|
||||
public class Ex12_4 {
|
||||
public static void main(String[] args) {
|
||||
LocalDate date = LocalDate.of(2017, 9, 21);
|
||||
LocalTime time = LocalTime.of(13, 45, 20);
|
||||
|
||||
// 2017-09-21T13:45:20
|
||||
LocalDateTime dt1 = LocalDateTime.of(2017, Month.SEPTEMBER, 21, 13, 45, 20);
|
||||
LocalDateTime dt2 = LocalDateTime.of(date, time);
|
||||
LocalDateTime dt3 = date.atTime(13, 45, 20);
|
||||
LocalDateTime dt4 = date.atTime(time);
|
||||
LocalDateTime dt5 = time.atDate(date);
|
||||
|
||||
LocalDate date1 = dt1.toLocalDate(); // 2017-09-21
|
||||
LocalTime time1 = dt1.toLocalTime(); // 13:45:30
|
||||
|
||||
Instant.ofEpochSecond(3);
|
||||
Instant.ofEpochSecond(3, 0);
|
||||
Instant.ofEpochSecond(2, 1_000_000_000);
|
||||
Instant.ofEpochSecond(4, -1_000_000_000);
|
||||
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,13 @@
|
||||
package Chapter12;
|
||||
|
||||
import java.time.LocalDate;
|
||||
import java.time.temporal.ChronoField;
|
||||
|
||||
public class Ex12_6 {
|
||||
public static void main(String[] args) {
|
||||
LocalDate date1 = LocalDate.of(2017, 9, 21);
|
||||
LocalDate date2 = date1.withYear(2011);
|
||||
LocalDate date3 = date1.withDayOfMonth(25);
|
||||
LocalDate date4 = date1.with(ChronoField.MONTH_OF_YEAR, 2);
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,13 @@
|
||||
package Chapter12;
|
||||
|
||||
import java.time.LocalDate;
|
||||
import java.time.temporal.ChronoUnit;
|
||||
|
||||
public class Ex12_7 {
|
||||
public static void main(String[] args) {
|
||||
LocalDate date1 = LocalDate.of(2017, 9, 21); // 2017-09-21
|
||||
LocalDate date2 = date1.plusWeeks(1); // 2017-09-28
|
||||
LocalDate date3 = date2.minusYears(6); // 2011-09-28
|
||||
LocalDate date4 = date3.plus(6, ChronoUnit.MONTHS); // 2012-03-28
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,23 @@
|
||||
package Chapter12;
|
||||
|
||||
import java.time.DayOfWeek;
|
||||
import java.time.LocalDate;
|
||||
import java.time.temporal.ChronoField;
|
||||
import java.time.temporal.ChronoUnit;
|
||||
import java.time.temporal.Temporal;
|
||||
import java.time.temporal.TemporalAdjuster;
|
||||
|
||||
public class NextWorkingDay implements TemporalAdjuster {
|
||||
|
||||
@Override
|
||||
public Temporal adjustInto(Temporal temporal) {
|
||||
DayOfWeek dow = DayOfWeek.of(temporal.get(ChronoField.DAY_OF_WEEK));
|
||||
int dayToAdd = 1;
|
||||
if (dow == DayOfWeek.FRIDAY) {
|
||||
dayToAdd = 3;
|
||||
} else if (dow == DayOfWeek.SATURDAY) {
|
||||
dayToAdd = 2;
|
||||
}
|
||||
return temporal.plus(dayToAdd, ChronoUnit.DAYS);
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,13 @@
|
||||
package Chapter12;
|
||||
|
||||
import java.time.LocalDate;
|
||||
import java.time.temporal.ChronoField;
|
||||
|
||||
public class Quiz12_1 {
|
||||
public static void main(String[] args) {
|
||||
LocalDate date = LocalDate.of(2014, 3, 18);
|
||||
date = date.with(ChronoField.MONTH_OF_YEAR, 9);
|
||||
date = date.plusYears(2).minusDays(10);
|
||||
date.withYear(2011);
|
||||
}
|
||||
}
|
||||
{kind=link}
|
After Width: | Height: | Size: 44 KiB |
545
도서/모던 자바 인 액션 (Modern Java In Action)/src/Chapter13/Chapter13.md
Normal file
@@ -0,0 +1,545 @@
|
||||
# Chapter13. 디폴트 메서드
|
||||
- 전통적인 자바에서 인터페이스와 관련 메서드는 한 몸처럼 구성된다.
|
||||
- 인터페이스를 구현하는 클래스는 인터페이스에서 정의하는 모든 메서드 구현을 제공하거나 아니면 슈퍼클래스의 구현을 상속받아야 한다.
|
||||
- 평소에는 이 규칙을 지키는 데 아무 문제가 없지만 라이브러리 설계자 입장에서 인터페이스에 새로운 메서드를 추가하는 등 인터페이스를 바꾸고 싶을 때는 문제가 발생한다.
|
||||
- 인터페이스를 바꾸면 이전에 해당 인터페이스를 구현했던 모든 클래스의 구현도 고쳐야 하기 때문이다.
|
||||
- 하지만 자바 8에서는 이 문제를 해결하는 새로운 기능을 제공한다.
|
||||
- 자바 8에서는 기본 구현을 포함하는 인터페이스를 정의하는 두 가지 방법을 제공한다.
|
||||
- 첫 번째는 인터페이스 내부에 `정적 메서드(static method)`를 사용하는 것이다.
|
||||
- 두 번째는 인터페이스의 기본 구현을 제공할 수 있도록 `디폴트 메서드(default method)` 기능을 사용하는 것이다.
|
||||
- 즉, 자바 8에서는 메서드 구현을 포함하는 인터페이스를 정의할 수 있다.
|
||||
- 결과적으로 기존 인터페이스를 구현하는 클래스는 자동으로 인터페이스에 추가된 새로운 메서드의 디폴트 메서드를 상속받게 된다. 이렇게 하면 기존의 코드 구현을 바꾸도록 강요하지 않으면서도 인터페이스를 바꿀 수 있다.
|
||||
- 이와 같은 방식으로 추가된 두 가지 예로 `List` 인터페이스의 `sort`와 `Collection` 인터페이스의 `stream` 메서드를 살펴봤다.
|
||||
|
||||
1장에서 살펴본 `List` 인터페이스의 `sort` 메서드는 자바 8에서 새로 추가된 메서드다. 다음은 `sort`의 구현 코드다.
|
||||
|
||||
```java
|
||||
default void sort(Comparator<? super E> c) {
|
||||
Collections.sort(this, c);
|
||||
}
|
||||
```
|
||||
|
||||
반환형식 `void` 앞에 `default`라는 새로운 키워드가 등장했다. `default` 키워드는 해당 메서드가 디폴트 메서드임을 가리킨다. 여기서 `sort` 메서드는 `Collections.sort` 메서드를 호출한다. 이 새로운 디폴트 메서드 덕분에 리스트에 직접 `sort`를 호출할 수 있게 되었다.
|
||||
|
||||
```java
|
||||
List<Integer> numbers = Arrays.asList(3, 5, 1, 2, 6);
|
||||
numbers.sort(Comparator.naturalOrder()); // sort는 List 인터페이스의 디폴트 메서드다.
|
||||
```
|
||||
|
||||
위 코드에서 `Comparator.naturalOrder`라는 새로운 메서드가 등장했다. `naturalOrder`는 자연순서(표준 알파벳 순서)로 요소를 정렬할 수 있도록 `Comparator` 객체를 반환하는 `Comparator` 인터페이스에 추가된 새로운 정적 메서드다. 다음은 4장에서 사용한 `Collection`의 `stream` 메서드 정의 코드다.
|
||||
|
||||
```java
|
||||
default Stream<E> stream() {
|
||||
return StreamSupport.stream(spliterator(), false);
|
||||
}
|
||||
```
|
||||
|
||||
우리가 자주 사용했던 `stream` 메서드는 내부적으로 `StreamSupport.stream`이라는 메서드를 호출해서 스트림을 반환한다. `stream` 메서드의 내부에서는 `Collection` 인터페이스의 다른 디폴트 메서드 `spliterator`도 호출한다.
|
||||
|
||||
결국 인터페이스가 아니라 추상 클래스 아닌가? 인터페이스와 추상 클래스는 같은 점이 많아졌지만 여전히 다른 점도 있다. 어떤 점이 다른지는 곧 살펴볼 것이다. 디폴트 메서드를 사용하는 이유는 뭘까? 디폴트 메서드는 주로 라이브러리 설계자들이 사용한다. 디폴트 메서드를 이용하면 자바 API의 호환성을 유지하면서 라이브러리를 바꿀 수 있다.
|
||||
|
||||
디폴트 메서드가 없던 시절에는 인터페이스에 메서드를 추가하면서 여러 문제가 발생했다. 인터페이스에 새로 추가된 메서드를 구현하도록 인터페이스를 구현하는 기존 클래스를 고쳐야했기 때문이었다. 본인이 직접 인터페이스와 이를 구현하는 클래스를 관리할 수 있는 상황이라면 이 문제를 어렵지 않게 해결할 수 있지만 인터페이스를 대중에 공개했을 때는 상황이 다르다. 그래서 디폴트 메서드가 탄생했다. 디폴트 메서드를 이용하면 인터페이스의 기본 구현을 그대로 상속하므로 인터페이스에 자유롭게 새로운 메서드를 추가할 수 있게 된다.
|
||||
|
||||
만약 라이브러리 설계자라면 기존 구현을 고치지 않고도 인터페이스를 바꿀 수 있으므로 디폴트 메서드를 잘 이해하는 것이 중요하다. 또한 디폴트 메서드는 다중 상속 동작이라는 유연성을 제공하면서 프로그램 구성에도 도움을 준다(이제 클래스는 여러 디폴트 메서드를 상속받을 수 있게 되었다). 물론 라이브러리 설계자가 아닌 일반 개발자도 디폴트 메서드를 이해한다면 언젠가 도움이 될 것이다.
|
||||
|
||||
>**정적 메서드와 인터페이스**
|
||||
>
|
||||
>- 보통 자바에서는 인터페이스 그리고 인터페이스의 인스턴스를 활용할 수 있는 다양한 정적 메서드를 정의하는 유틸리티 클래스를 활용한다.
|
||||
>- 예를 들어 `Collections`는 `Collection` 객체를 활용할 수 있는 유틸리티 클래스다. 자바 8에서는 인터페이스에 직접 정적 메서드를 선언할 수 있으므로 유틸리티 클래스를 없애고 직접 인터페이스 내부에 정적 메서드를 구현할 수 있다.
|
||||
>- 그럼에도 불구하고 과거 버전과의 호환성을 유지할 수 있도록 자바 API에는 유틸리티 클래스가 남아있다.
|
||||
|
||||
우선 API가 바뀌면서 어떤 문제가 생기는지 확인한다. 또한 디폴트 메서드란 무엇이며 API가 바뀌면서 발생한 문제를 디폴트 메서드로 어떻게 해결할 수 있는지 설명한다. 그리고 디폴트 메서드를 만들어 다중 상속을 달성하는 방법을 보여준다. 마지막으로 같은 시그니처를 갖는 여러 디폴트 메서드를 상속받으면서 발생하는 모호성 문제를 자바 컴파일러가 어떻게 해결하는지 살펴본다.
|
||||
|
||||
---
|
||||
|
||||
## 13.1 변화하는 API
|
||||
API를 바꾸는 것이 왜 어려운지 예제를 통해 살펴보자. 우리가 인기 있는 자바 그리기 라이브러리 설계자가 되었다고 가정하자. 우리가 만든 라이브러리에는 모양의 크기를 조절하는 데 필요한 `setHeight`, `setWidth`, `getHeight`, `getWidth`, `setAbsoluteSize` 등의 메서드를 정의하는 `Resizable` 인터페이스가 있다. 그뿐만 아니라 `Rectangle`이나 `Square`처럼 `Resizable`을 구현하는 클래스도 제공한다. 라이브러리가 인기를 얻으면서 일부 사용자는 직접 `Resizable` 인터페이스를 구현하는 `Ellipse`라는 클래스를 구현하기도 했다.
|
||||
|
||||
API를 릴리스한 지 몇 개월이 지나면서 `Resizable`에 몇 가지 기능이 부족하다는 사실을 알게되었다. 예를 들어 `Resizable` 인터페이스에 크기 조절 인수로 모양의 크기를 조절할 수 있는 `setRelativeSize`라는 메서드가 있으면 좋을 것 같다. 그래서 `Resizable`에 `setRelativeSize`를 추가한 다음에 `Square`와 `Rectangle` 구현도 고쳤다. 이제 모든 문제가 해결된 걸까? 이전에 우리의 `Resizable` 인터페이스를 구현한 사용자는 어떻게 되는 걸까? 안타깝게도 라이브러리 사용자가 만든 클래스를 우리가 어떻게 할 수는 없다. 바로 자바 라이브러리 설계자가 라이브러리를 바꾸고 싶을 때 같은 문제가 발생한다. 이미 릴리스된 인터페이스를 고치면 어떤 문제가 발생하는지 더 자세히 알아보자.
|
||||
|
||||
### 13.1.1 API 버전 1
|
||||
`Resizable` 인터페이스 초기 버전은 다음과 같은 메서드를 포함한다.
|
||||
|
||||
```java
|
||||
public interface Resizable extends Drawable {
|
||||
int getWidth();
|
||||
int getHeight();
|
||||
void setWidth();
|
||||
void setHeight();
|
||||
void setAbsoluteSize(int width, int height);
|
||||
}
|
||||
```
|
||||
|
||||
#### 사용자 구현
|
||||
우리 라이브러리를 즐겨 사용하는 사용자 중 한 명은 직접 `Resizable`을 구현하는 `Ellipse` 클래스를 만들었다.
|
||||
|
||||
```java
|
||||
public class Ellipse implements Resizable {
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
이 사용자는 다양한 `Resizable` 모양(자신이 만든 `Ellipse`를 포함해서)을 처리하는 게임을 만들었다.
|
||||
|
||||
```java
|
||||
public class Game {
|
||||
public static void main(String... args) {
|
||||
List<Resizable> resizableShapes =
|
||||
Arrays.asList(new Square(), new Rectangle(), new Ellipse()); // 크기를 조절할 수 있는 모양 리스트
|
||||
Utils.paint(resizableShapes);
|
||||
}
|
||||
}
|
||||
|
||||
public class Utils {
|
||||
public static void paint(List<Resizable> l) {
|
||||
l.forEach(r -> {
|
||||
r.setAbsoluteSize(42, 42); // 각 모양에 setAbsoluteSize 호출
|
||||
r.draw();
|
||||
});
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 13.1.2 API 버전 2
|
||||
몇 개월이 지나자 `Resizable`을 구현하는 `Square`와 `Rectangle` 구현을 개선해달라는 많은 요청을 받았다. 그래서 다음 코드에서 보여주는 것처럼 API 버전 2를 만들었다.
|
||||
|
||||
```java
|
||||
public interface Resizable extends Drawable {
|
||||
int getWidth();
|
||||
int getHeight();
|
||||
void setWidth();
|
||||
void setHeight();
|
||||
void setAbsoluteSize(int width, int height);
|
||||
void setRelativeSize(int wFactor, int hFactor); // API 버전 2에 추가된 새로운 메서드
|
||||
}
|
||||
```
|
||||
|
||||
- `Resizable`에 메서드를 추가하면서 API가 바뀌었다. 따라서 인터페이스를 바꾼 다음에 애플리케이션을 재컴파일하면 에러가 발생한다.
|
||||
|
||||
#### 사용자가 겪는 문제
|
||||
`Resizable`을 고치면 몇 가지 문제가 발생한다. 첫 번째로 `Resizable`을 구현하는 모든 클래스는 `setRelativeSize` 메서드를 구현해야 한다. 하지만 라이브러리 사용자가 직접 구현한 `Ellipse`는 `setRelativeSize` 메서드를 구현하지 않는다. 인터페이스에 새로운 메서드를 추가하면 `바이너리 호환성`은 유지된다. `바이너리 호환성`이란 새로 추가된 메서드를 호출하지만 않으면 새로운 메서드 구현이 없이도 기존 클래스 파일 구현이 잘 동작한다는 의미다. 하지만 언젠가는 누군가가 `Resizable`을 인수로 받는 `Utils.paint`에서 `setRelativeSize`를 사용하도록 코드를 바꿀 수 있다. 이때 `Ellipse` 객체가 인수로 전달되면 `Ellipse`는 `setRelativeSize` 메서드를 정의하지 않았으므로 런타임에 다음과 같은 에러가 발생할 것이다.
|
||||
|
||||
```
|
||||
Exception in thread "main" java.lang.AbstractMethodError:
|
||||
lambdasinaction.chap9.Ellipse.setRelativeSize(II)V
|
||||
```
|
||||
|
||||
두 번째로 사용자가 `Ellipse`를 포함하는 전체 애플리케이션을 재빌드할 때 다음과 같은 컴파일 에러가 발생한다.
|
||||
|
||||
```
|
||||
lambdasinaction/chap9/Ellipse.java:6: error:
|
||||
Ellipse is not abstract and does not override abstract method setRelativeSize(int, int) in Resizable
|
||||
```
|
||||
|
||||
공개된 API를 고치면 기존 버전과의 호환성 문제가 발생한다. 이런 이유 때문에 공식 자바 컬렉션 API 같은 기존의 API는 고치기 어렵다. 물론 API를 바꿀 수 있는 몇 가지 대안이 있지만 완벽한 해결책은 될 수 없다. 예를 들어 자신만의 API를 별도로 만든 다음에 예전 버전과 새로운 버전을 직접 관리하는 방법도 있다. 하지만 이는 여러 가지로 불편하다. 첫째, 라이브러리를 관리하기가 복잡하다. 둘째, 사용자는 같은 코드에 예전 버전과 새로운 버전 두 가지 라이브러리를 모두 사용해야 하는 상황이 생긴다. 결국 프로젝트에서 로딩해야 할 클래스 파일이 많아지면서 메모리 사용과 로딩 시간 문제가 발생한다.
|
||||
|
||||
디폴트 메서드로 이 모든 문제를 해결할 수 있다. 디폴트 메서드를 이용해서 API를 바꾸면 새롭게 바뀐 인터페이스에서 자동으로 기본 구현을 제공하므로 기존 코드를 고치지 않아도 된다.
|
||||
|
||||
>**바이너리 호환성, 소스 호환성, 동작 호환성**
|
||||
>
|
||||
>- 자바 프로그램을 바꾸는 것과 관련된 호환성 문제는 크게 바이너리 호환성, 소스 호환성, 동작 호환성 세 가지로 분류할 수 있다(더 자세한 사항은 http://goo.gl/JNn4vm 함고)
|
||||
>- 인터페이스에 메서드를 추가했을 때는 바이너리 호환성을 유지하지만 인터페이스를 구현하는 클래스를 재컴파일하면 에러가 발생한다.
|
||||
>- 즉, 다양한 호환성이 있다는 사실을 이해해야한다.
|
||||
>- 뭔가를 바꾼 이후에도 에러 없이 기존 바이너리가 실행될 수 있는 상황을 `바이너리 호환성`이라고 한다(바이너리 실행에는 인증, 준비, 해석 등의 과정이 포함된다). 예를 들어 인터페이스에 메서드를 추가했을 때 추가된 메서드를 호출하지 않는 한 문제가 일어나지 않는데 이를 바이너리 호환성이라고 한다.
|
||||
>- 간단히 말해, `소스 호환성`이란 코드를 고쳐도 기존 프로그램을 성공적으로 재컴파일할 수 있음을 의미한다. 예를 들어 인터페이스에 메서드를 추가하면 소스 호환성이 아니다. 추가한 메서드를 구현하도록 클래스를 고쳐야 하기 때문이다.
|
||||
>- 마지막으로 `동작 호환성`이란 코드를 바꾼 다음에도 같은 입력값이 주어지면 프로그램이 같은 동작을 실행한다는 의미다. 예를 들어 인터페이스에 메서드를 추가하더라도 프로그램에서 추가된 메서드를 호출할 일은 없으므로(혹은 우연히 구현 클래스가 이를 오버라이드했을 수도 있다) 동작 호환성은 유지된다.
|
||||
|
||||
---
|
||||
|
||||
## 13.2 디폴트 메서드란 무엇인가?
|
||||
공개된 API에 새로운 메서드를 추가하면 기존 구현에 어떤 문제가 생기는지 살펴봤다. 자바 8에서는 호환성을 유지하면서 API를 바꿀 수 있도록 새로운 기능인 **디폴트 메서드**(default method)를 제공한다. 이제 인터페이스는 자신을 구현하는 클래스에서 메서드를 구현하지 않을 수 있는 새로운 메서드 시그니처를 제공한다. 그럼 디폴트 메서드는 누가 구현할까? 인터페이스를 구현하는 클래스에서 구현하지 않은 메서드는 인터페이스 자체에서 기본으로 제공한다(그래서 이를 디폴트 메서드라고 부른다).
|
||||
|
||||
디폴트 메서드인지 어떻게 알 수 있을까? 디폴트 메서드는 간단하게 알아볼 수 있다. 우선 디폴트 메서드는 `default`라는 키워드로 시작하며 다른 클래스에 선언된 메서드처럼 메서드 바디를 포함한다. 예를 들어 컬렉션 라이브러리에 `Sized`라는 인터페이스를 정의했다고 가정하자. 다음 코드에서 보여주는 것처럼 `Sized` 인터페이스는 추상 메서드 `size`와 디폴트 메서드 `isEmpty`를 포함한다.
|
||||
|
||||
```java
|
||||
public interface Sized {
|
||||
int size();
|
||||
default boolean isEmpty() { // 디폴트 메서드
|
||||
return size() == 0;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
이제 `Sized` 인터페이스를 구현하는 모든 클래스는 `isEmpty`의 구현도 상속받는다. 즉, 인터페이스에 디폴트 메서드를 추가하면 소스 호환성이 유지된다.
|
||||
|
||||
자바 그리기 라이브러리와 게임 예제로 돌아가자. 결론적으로 말해서 디폴트 메서드를 이용해서 `setRelativeSize`의 디폴트 구현을 제공한다면 호환성을 유지하면서 라이브러리를 고칠 수 있다(즉, 우리 라이브러리 사용자는 `Resizable` 인터페이스를 구현하는 클래스를 고칠 필요가 없다).
|
||||
|
||||
```java
|
||||
default void setRelativeSize(int wFactor, int hFactor) {
|
||||
setAbsoluteSize(getWidth() / wFactor, getHeight() / hFactor);
|
||||
}
|
||||
```
|
||||
|
||||
인터페이스가 구현을 가질 수 있고 클래스는 여러 인터페이스를 동시에 구현할 수 있으므로 결국 자바도 다중 상속을 지원하는 걸까? 인터페이스를 구현하는 클래스가 디폴트 메서드와 같은 메서드 시그니처를 정의하거나 아니면 디폴트 메서드를 오버라이드한다면 어떻게 될까? 이런 문제는 아직 걱정하지 않아도 된다. 이 문제를 해결할 수 있는 몇 가지 규칙이 있는데 이후에 살펴본다.
|
||||
|
||||
자바 8 API에서 디폴트 메서드가 상당히 많이 활용되었을 것임을 추측할 수 있다. 예를 들어 `Collection` 인터페이스의 `stream` 메서드처럼 부지불식간에 많은 디폴트 메서드를 사용했다. `List` 인터페이스의 `sort` 메서드도 디폴트 메서드다. `Predicate`, `Function`, `Comparator` 등 많은 함수형 인터페이스도 `Predicate.and` 또는 `Function.andThen` 같은 다양한 디폴트 메서드를 포함한다(함수형 인터페이스는 오직 하나의 추상 메서드를 포함한다. 디폴트 메서드는 추상 메서드에 해당하지 않는다는 점을 기억하자).
|
||||
|
||||
>**추상 클래스와 자바 8의 인터페이스**
|
||||
>
|
||||
>추상 클래스와 인터페이스는 뭐가 다를까? 둘 다 추상 메서드와 바디를 포함하는 메서드를 정의할 수 있다.
|
||||
>첫째, 클래스는 하나의 추상 클래스만 상속받을 수 있지만 인터페이스를 여러 개 구현할 수 있다.
|
||||
>둘째, 추상 클래스는 인스턴스 변수(필드)로 공통 상태를 가질 수 있다. 하지만 인터페이스는 인스턴스 변수를 가질 수 없다.
|
||||
|
||||
##### ----- 퀴즈 13-1. removeIf ------
|
||||
여러분이 자바 언어와 API의 달인이라고 가정하자. 어느 날 다수의 사용자로부터 `ArrayList`, `TreeSet`, `LinkedList` 및 다른 모든 컬렉션에서 사용할 수 있는 `removeIf` 메서드를 추가해달라는 요청을 받았다. `removeIf` 메서드는 주어진 프레디케이트와 일치하는 모든 요소를 컬렉션에서 제거하는 기능을 수행한다. 새로운 `removeIf`를 기존 컬렉션 API에 가장 적절하게 추가하는 방법은 무엇일까?
|
||||
|
||||
`정답`
|
||||
모든 컬렉션 클래스는 `java.util.Collection` 인터페이스를 구현한다. 그러면 `Collection` 인터페이스에 메서드를 추가할 수 있을까? 지금까지 확인한 것처럼 디폴트 메서드를 인터페이스에 추가함으로써 소스 호환성을 유지할 수 있다. 그러면 `Collection`을 구현하는 모든 클래스(물론 컬렉션 라이브러리의 클래스뿐 아니라 `Collection` 인터페이스를 직접 구현한 모든 사용자의 클래스도 포함)는 자동으로 `removeIf`를 사용할 수 있게 된다.
|
||||
|
||||
```java
|
||||
default boolean removeIf(Predicate<? super E> filter) {
|
||||
boolean removed = false;
|
||||
Iterator<E> each = iterator();
|
||||
while(each.hasNext()) {
|
||||
if(filter.test(each.next())) {
|
||||
each.remove();
|
||||
removed = true;
|
||||
}
|
||||
}
|
||||
return removed;
|
||||
}
|
||||
```
|
||||
|
||||
##### -----------------------------------------
|
||||
|
||||
---
|
||||
|
||||
## 13.3 디폴트 메서드 활용 패턴
|
||||
여러분은 이미 디폴트 메서드를 이용하면 라이브러리를 바꿔도 호환성을 유지할 수 있음을 확인했다. 디폴트 메서드를 다른 방식으로도 활용할 수 있을까? 우리가 만드는 인터페이스에도 디폴트 메서드를 추가할 수 있다. 이 절에서는 디폴트 메서드를 이용하는 두 가지 방식, 즉 `선택형 메서드(optional method)`와 `동작 다중 상속(multiple inheritance of behavior)`을 설명한다.
|
||||
|
||||
### 13.3.1 선택형 메서드
|
||||
여러분은 아마 인터페이스를 구현하는 클래스에서 메서드의 내용이 비어있는 상황을 본 적이 있을 것이다. 예를 들어 `Iterator` 인터페이스를 보자. `Iterator`는 `hasNext`와 `next`뿐 아니라 `remove` 메서드도 정의한다. 사용자들이 `remove` 기능은 잘 사용하지 않으므로 자바 8 이전에는 `remove` 기능을 무시했다. 결과적으로 `Iterator`를 구현하는 많은 클래스에서는 `remove`에 빈 구현을 제공했다.
|
||||
|
||||
디폴트 메서드를 이용하면 `remove` 같은 메서드에 기본 구현을 제공할 수 있으므로 인터페이스를 구현하는 클래스에서 빈 구현을 제공할 필요가 없다. 예를 들어 자바 8의 `Iterator` 인터페이스는 다음처럼 `remove` 메서드를 정의한다.
|
||||
|
||||
```java
|
||||
interface Iterator<T> {
|
||||
boolean hasNext();
|
||||
T next();
|
||||
default void remove() {
|
||||
throw new UnsupportedOperationException();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
기본 구현이 제공되므로 `Iterator` 인터페이스를 구현하는 클래스는 빈 `remove` 메서드를 구현할 필요가 없어졌고, 불필요한 코드를 줄일 수 있다.
|
||||
|
||||
### 13.3.2 동작 다중 상속
|
||||
디폴트 메서드를 이용하면 기존에는 불가능했던 동작 다중 상속 기능도 구현할 수 있다. 클래스는 다중 상속을 이용해서 기존 코드를 재사용할 수 있다.
|
||||
|
||||
자바에서 클래스는 한 개의 다른 클래스만 상속할 수 있지만 인터페이스는 여러 개 구현할 수 있다. 다음은 자바 API에 정의된 `ArrayList` 클래스다.
|
||||
|
||||
```java
|
||||
public class ArrayList<E> extends AbstractList<E> // 한 개의 클래스를 상속받는다.
|
||||
implements List<E>, RandomAccess, Cloneable, Serializable { // 네 개의 인터페이스를 구현한다.
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
#### 다중 상속 형식
|
||||
여기서 `ArrayList`는 한 개의 클래스를 상속받고, 여섯 개의 인터페이스를 구현한다. 결과적으로 `ArrayList`는 `AbstractList`, `List`, `RandomAccess`, `Cloneable`, `Serializable`, `Iterable`, `Collection`의 **서브형식**(subtype)이 된다. 따라서 디플트 메서드를 사용하지 않아도 다중 상속을 활용할 수 있다.
|
||||
|
||||
자바 8에서는 인터페이스가 구현을 포함할 수 있으므로 클래스는 여러 인터페이스에서 동작(구현 코드)을 상속받을 수 있따. 다중 동작 상속이 어떤 장점을 제공하는지 예제로 살펴보자. 중복되지 않는 최소한의 인터페이스를 유지한다면 우리 코드에서 동작을 쉽게 재사용하고 조합할 수 있다.
|
||||
|
||||
#### 기능이 중복되지 않는 최소의 인터페이스
|
||||
우리가 만든느 게임에 다양한 특성을 갖는 여러 모양을 정의한다고 가정하자. 어떤 모양은 회전할 수 없지만 크기는 조절할 수 있다. 어떤 모양은 회전할 수 있으며 움직일 수 있지만 크기는 조절할 수 없다. 최대한 기존 코드를 재사용해서 이 기능을 구현하려면 어떻게 해야 할까?
|
||||
|
||||
먼저 `setRotationAngle`과 `getRatationAngle` 두 개의 추상 메서드를 포함하는 `Rotatable` 인터페이스를 정의한다. 인터페이스는 다음 코드에서 보여주는 것처럼 `setRotationAngle`과 `getRotationAngle` 메서드를 이용해서 디폴트 메서드 `rotateBy`도 구현한다.
|
||||
|
||||
```java
|
||||
public interface Rotatable {
|
||||
void setRotationAngle(int angleInDegrees);
|
||||
int getRotationAngle();
|
||||
default void rotateBy(int angleInDegrees) { // rotateBy 메서드의 기본 구현
|
||||
setRotationAngle((getRotationAngle() + angleInDegrees) % 360);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
위 인터페이스는 구현해야 할 다른 메서드에 따라 뼈대 알고리즘이 결정되는 템플릿 디자인 패턴과 비슷해 보인다.
|
||||
|
||||
`Rotatable`을 구현하는 모든 클래스는 `setRotationAngle`과 `getRotationAngle`의 구현을 제공해야 한다. 하지만 `rotateBy`는 기본 구현이 제공되므로 따로 구현을 제공하지 않아도 된다.
|
||||
|
||||
마찬가지로 이전에 살펴본 두 가지 인터페이스 `Moveable`과 `Resizable`을 정의해야 한다. 두 인터페이스 모두 디폴트 구현을 제공한다. 다음은 `Moveable` 코드다.
|
||||
|
||||
```java
|
||||
public interface Moveable {
|
||||
int getX();
|
||||
int getY();
|
||||
void setX(int x);
|
||||
void setY(int y);
|
||||
|
||||
default void moveHorizontally(int distance) {
|
||||
setX(getX() + distance);
|
||||
}
|
||||
|
||||
default void moveVertically(int distance) {
|
||||
setY(getY() + distance);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
다음은 `Resizable` 코드다.
|
||||
|
||||
```java
|
||||
public interface Resizable {
|
||||
int getWidth();
|
||||
int getHeight();
|
||||
void setWidth(int width);
|
||||
void setHeight(int height);
|
||||
void setAbsoluteSize(int width, int height);
|
||||
|
||||
default void setRelativeSize(int wFactor, int hFactor) {
|
||||
setAbsoluteSize(getWidth() / wFactor, getHeight() / hFactor);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### 인터페이스 조합
|
||||
이제 이들 인터페이스를 조합해서 게임에 필요한 다양한 클래스를 구현할 수 있다.예를 들어 다음 코드처럼 움직일 수 있고(moveable), 회전할 수 있으며(rotatable), 크기를 조절할 수 있는(resizable) 괴물(Monster) 클래스를 구현할 수 있다.
|
||||
|
||||
```java
|
||||
public class Monster implements Rotatable, Moveable, Resizable{
|
||||
... // 모든 추상 메서드의 구현은 제공해야 하지만 디폴트 메서드의 구현은 제공할 필요가 없다.
|
||||
}
|
||||
```
|
||||
|
||||
`Monster` 클래스는 `Rotatable`, `Moveable`, `Resizable` 인터페이스의 디폴트 메서드를 자동으로 상속받는다. 즉, `Monster` 클래스는 `rotateBy`, `moveHorizontally`, `moveVertically`, `setRelativeSize` 구현을 상속받는다.
|
||||
|
||||
상속받은 다양한 메서드를 직접 호출할 수 있다.
|
||||
|
||||
```java
|
||||
Monster m = new Monster(); // 생성자는 내부적으로 좌표, 높이, 기본 각도를 설정한다.
|
||||
m.rotateBy(180); // Rotatable의 rotateBy 호출
|
||||
m.moveVertically(10); // Moveable의 moveVertically 호출
|
||||
```
|
||||
|
||||
이번에는 움직일 수 있으며 회전할 수 있지만, 크기는 조절할 수 없는 `Sun` 클래스를 정의한다. 이때 코드를 복사&붙여넣기할 필요가 전혀 없다. `Moveable`과 `Rotatable`을 구현할 때 자동으로 디폴트 메서드를 재사용할 수 있기 때문이다.
|
||||
|
||||
```java
|
||||
public class Sun implements Moveable, Rotatable{
|
||||
... // 모든 추상 메서드의 구현은 제공해야 하지만 디폴트 메서드의 구현은 제공할 필요가 없다.
|
||||
}
|
||||
```
|
||||
|
||||
인터페이스에 디폴트 구현을 포함시키면 또 다른 장점이 생긴다. 예를 들어 `moveVertically`의 구현을 더 효율적으로 고쳐야 한다고 가정하자. 디폴트 메서드 덕분에 `Moveable` 인터페이스를 직접 고칠 수 있고 따라서 `Moveable`을 구현하는 모든 클래스도 자동으로 변경한 코드를 상속받는다(물론 구현 클래스에서 메서드를 정의하지 않은 상황에 한해서다).
|
||||
|
||||
>**옳지 못한 상속**
|
||||
>
|
||||
>상속으로 코드 재사용 문제를 모두 해결할 수 있는 것은 아니다. 예를 들면 한 개의 메서드를 재사용하려고 100개의 메서드와 필드가 정의되어 있는 클래스를 상속받는 것은 좋은 생각이 아니다. 이럴 때는 **델리게이션**(delegation), 즉 멤버 변수를 이용해서 클래스에서 필요한 메서드를 직접 호출하는 메서드를 작성하는 것이 좋다. 종종 `final`로 선언된 클래스를 볼 수 있다. 다른 클래스가 이 클래스를 상속받지 못하게 함으로써 원래 동작이 바뀌지 않길 원하기 때문이다. 예를 들어 `String` 클래스도 `final`로 선언되어 있다. 이렇게 해서 다른 누군가가 `String`의 핵심 기능을 바꾸지 못하도록 제한할 수 있다.
|
||||
>
|
||||
>우리의 디폴트 메서드에도 이 규칙을 적용할 수 있다. 필요한 기능만 포함하도록 인터페이스를 최소한으로 유지한다면 필요한 기능만 선택할 수 있으므로 쉽게 기능을 조립할 수 있다.
|
||||
|
||||
지금까지 다양한 방법으로 디폴트 메서드를 활용할 수 있음을 살펴봤다. 만약 어떤 클래스가 같은 디폴트 메서드 시그니처를 포함하는 두 인터페이스를 구현하는 상황이라면 어떻게 될까? 클래스는 어떤 인터페이스의 디폴트 메서드를 사용하게 될까? 다음으로는 이 문제를 자세히 살펴본다.
|
||||
|
||||
---
|
||||
|
||||
## 13.4 해석 규칙
|
||||
이미 살펴봤듯이, 자바의 클래스는 하나의 부모 클래스만 상속받을 수 있지만 여러 인터페이스를 동시에 구현할 수 있다. 자바 8에는 디폴트 메서드가 추가되었으므로 같은 시그니처를 갖는 디폴트 메서드를 상속받는 상황이 생길 수 있다. 이런 상황에서는 어떤 인터페이스의 디폴트 메서드를 사용하게 될까? 실전에서 자주 일어나는 일은 아니지만 이를 해결할 수 있는 규칙이 필요하다. 이 절에서는 자바 컴파일러가 이러한 충돌을 어떻게 해결하는지 설명한다. 이 절을 통해 '다음 예제에서 클래스 C는 누구의 hello를 호출할까?'라는 질문에 대한 답을 찾을 수 있을 것이다.
|
||||
|
||||
다음 코드는 의도적으로 문제를 보여주려고 만든 예제일 뿐 실제로는 자주 일어나지 않는다.
|
||||
|
||||
```java
|
||||
public interface A {
|
||||
default void hello() {
|
||||
System.out.println("Hello from A");
|
||||
}
|
||||
}
|
||||
|
||||
public interface B extends A {
|
||||
default void hello() {
|
||||
System.out.println("Hello from B");
|
||||
}
|
||||
}
|
||||
|
||||
public class C implements B, A {
|
||||
public static void main(String... args) {
|
||||
new C().hello(); // 무엇이 출력될까?
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
`C++`의 다이아몬드 문제, 즉 같은 시그니처를 갖는 두 메서드를 상속받는 클래스를 들어본 독자도 있을 것이다. 이때 어떤 메서드가 사용될까? 자바 8은 이러한 문제에 대한 해결 규칙을 제공한다. 다음 절에서 대답을 찾을 수 있다.
|
||||
|
||||
### 13.4.1 알아야 할 세 가지 해결 규칙
|
||||
다른 클래스나 인터페이스로부터 같은 시그니처를 갖는 메서드를 상속받을 때는 세 가지 규칙을 따라야 한다.
|
||||
|
||||
1. 클래스가 항상 이긴다. 클래스나 슈퍼클래스에서 정의한 메서드가 디폴트 메서드보다 우선권을 갖는다.
|
||||
2. 1번 규칙 이외의 상황에서는 서브인터페이스가 이긴다. 상속관계를 갖는 인터페이스에서 같은 시그니처를 갖는 메서드를 정의할 때는 서브인터페이스가 이긴다. 즉, B가 A를 상속받는다면 B가 A를 이긴다.
|
||||
3. 여전히 디폴트 메서드의 우선순위가 결정되지 않았다면 여러 인터페이스를 상속받는 클래스가 명시적으로 디폴트 메서드를 오버라이드하고 호출해야 한다.
|
||||
|
||||
이 세 가지 규칙만 알면 모든 디폴트 메서드 해석 문제가 해결된다. 이제 예제로 더 자세히 알아보자.
|
||||
|
||||
### 13.4.2 디폴트 메서드를 제공하는 서브인터페이스가 이긴다.
|
||||
13.4절의 시작 부분에서 B와 A를 구현하는 클래스 C가 등장했던 예제를 살펴보자. B와 A는 `hello`라는 디폴트 메서드를 정의한다. 또한 B는 A를 상속받는다.
|
||||
|
||||
- 디폴트 메서드를 제공하는 가장 하위의 서브인터페이스가 이긴다.
|
||||
|
||||
컴파일러는 누구의 `hello` 메서드 정의를 사용할까? 2번 규칙에서는 서브인터페이스가 이긴다고 설명한다. 즉, B가 A를 상속받았으므로 컴파일러는 B의 `hello`를 선택한다. 따라서 프로그램은 'Hello from B'를 출력한다.
|
||||
|
||||
이번에는 C가 D를 상속받는다면 어떤 일이 일어날지 생각해보자.
|
||||
|
||||
```java
|
||||
public class D implements A{ }
|
||||
public class C extends D implements B, A {
|
||||
public static void main(String... args) {
|
||||
new C().hello(); // 무엇이 출력될까?
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
1번 규칙은 클래스의 메서드 구현이 이긴다고 설명한다. D는 `hello`를 오버라이드하지 않았고 단순히 인터페이스 A를 구현했다. 따라서 D는 인터페이스 A의 디폴트 메서드 구현을 상속받는다. 2번 규칙에서는 클래스나 슈퍼클래스에 메서드 정의가 없을 때는 디폴트 메서드를 정의하는 서브인터페이스가 선택된다. 따라서 컴파일러는 인터페이스 A의 `hello`나 인터페이스 B의 `hello` 둘 중 하나를 선택해야 한다. 여기서 B가 A를 상속받는 관계이므로 이번에도 'Hello from B'가 출력된다.
|
||||
|
||||
##### -----퀴즈 13-2. 해석 규칙을 기억하라-----
|
||||
이전 예제를 그대로 활용하자. 다만 퀴즈에서는 D가 명시적으로 A의 `hello` 메서드를 오버라이드한다. 프로그램의 실행 결과는 무엇일까?
|
||||
|
||||
```java
|
||||
public class D implements A {
|
||||
void hello() {
|
||||
System.out.println("Hello from D");
|
||||
}
|
||||
}
|
||||
|
||||
public class C extends D implements B, A {
|
||||
public static void main(String... args) {
|
||||
new C().hello();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
`정답`
|
||||
프로그램의 실행 결과는 'Hello from D'다. 규칙 1에 의해 슈퍼클래스의 메서드 정의가 우선권을 갖기 때문이다.
|
||||
|
||||
D가 다음처럼 구현되었다고 가정하자.
|
||||
|
||||
```java
|
||||
public abstract class D implements A {
|
||||
public abstract void hello();
|
||||
}
|
||||
```
|
||||
|
||||
그러면 A에서 디폴트 메서드를 제공함에도 불구하고 C는 `hello`를 구현해야 한다.
|
||||
|
||||
##### ------------------------------------------------------
|
||||
|
||||
### 13.4.3 충돌 그리고 명시적인 문제해결
|
||||
지금까지는 1번과 2번 규칙으로 문제를 해결할 수 있었다. 이번에는 B가 A를 상속받지 않는 상황이라고 가정하자.
|
||||
|
||||
```java
|
||||
public interface A {
|
||||
default void hello() {
|
||||
System.out.println("Hello from A");
|
||||
}
|
||||
}
|
||||
|
||||
public interface B {
|
||||
default void hello() {
|
||||
System.out.println("Hello from B");
|
||||
}
|
||||
}
|
||||
|
||||
public class C implements B, A { }
|
||||
```
|
||||
|
||||
이번에는 인터페이스 간에 상속관계가 없으므로 2번 규칙을 적용할 수 없다. 그러므로 A와 B의 `hello` 메서드를 구별할 기준이 없다. 따라서 자바 컴파일러는 어떤 메서드를 호출해야 할지 알 수 없으므로 `"Error: class C imherits unrelated defaults for hello() from types B and A."` 같은 에러가 발생한다.
|
||||
|
||||
#### 충돌 해결
|
||||
클래스와 메서드 관계로 디폴트 메서드를 선택할 수 없는 상황에서는 선택할 수 있는 방법이 없다. 개발자가 직접 클래스 C에서 사용하려는 메서드를 명시적으로 선택해야 한다. 즉, 클래스 C에서 `hello` 메서드를 오버라이드한 다음에 호출하려는 메서드를 명시적으로 선택해야 한다. 자바 8에서는 `X.super.m(...)` 형태의 새로운 문법을 제공한다. 여기서 `X`는 호출하려는 메서드 `m`의 슈퍼인터페이스다. 예를 들어 다음처럼 C에서 B의 인터페이스를 호출할 수 있다.
|
||||
|
||||
```java
|
||||
public class C implements B, A {
|
||||
void hello() {
|
||||
B.super.hello(); // 명시적으로 인터페이스 B의 메서드를 선택한다.
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
##### -----퀴즈 13-3. 거의 비슷한 시그니처-----
|
||||
이 퀴즈에서는 인터페이스 A와 B가 다음처럼 정의되어 있다고 가정하자.
|
||||
|
||||
```java
|
||||
public interface A {
|
||||
default Number getNumber() {
|
||||
return 10;
|
||||
}
|
||||
}
|
||||
|
||||
public interface B {
|
||||
default Number getNumber() {
|
||||
return 42;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
다음은 클래스 C의 정의다.
|
||||
|
||||
```java
|
||||
public class C implements B, A {
|
||||
public static void main(String... args) {
|
||||
System.out.println(new C().getNumber());
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
프로그램 출력 결과는?
|
||||
|
||||
`정답`
|
||||
C는 A와 B의 메서드를 구분할 수 없다. 따라서 클래스 C에서 컴파일 에러가 발생한다.
|
||||
|
||||
##### ------------------------------------------------------
|
||||
|
||||
### 13.4.4 다이아몬드 문제
|
||||
`C++` 커뮤니티를 긴장시킬 만한 마지막 시나리오를 살펴보자.
|
||||
|
||||
```java
|
||||
public interface A {
|
||||
default void hello() {
|
||||
System.out.println("Hello from A");
|
||||
}
|
||||
}
|
||||
public interface B extends A { }
|
||||
public interface C extends A { }
|
||||
public class D implements B, C {
|
||||
public static void main(String... args) {
|
||||
new D().hello(); // 무엇이 출력될까?
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
이 시나리오의 다이어그램은 모양이 다이아몬드를 닮았으므로 이를 **다이아몬드 문제**(diamond problem)라고 부른다. D는 B와 C 중 누구의 디폴트 메서드 정의를 상속받을까? 실제로 선택할 수 있는 메서드 선언은 하나뿐이다. A만 디폴트 메서드를 정의하고 있다. 따라서 결국 프로그램 출력 결과는 'Hello from A'가 된다.
|
||||
|
||||
B에도 같은 시그니처의 디폴트 메서드 `hello`가 있다면 어떻게 될까? 2번 규칙은 디폴트 메서드를 제공하는 가장 하위의 인터페이스가 선택된다고 했다. B는 A를 상속받으므로 B가 선택된다. B와 C가 모두 디폴트 메서드 `hello` 메서드를 정의한다면 충돌이 발생하므로 이전에 설명한 것처럼 둘 중 하나의 메서드를 명시적으로 호출해야 한다.
|
||||
|
||||
다음처럼 인터페이스 C에 추상 메서드 `hello`(디폴트 메서드가 아님!)를 추가하면 어떤 일이 벌어질까(A와 B에는 아무 메서드도 정의하지 않는다)?
|
||||
|
||||
```java
|
||||
public interface C extends A {
|
||||
void hello();
|
||||
}
|
||||
```
|
||||
|
||||
C는 A를 상속받으므로 C의 추상 메서드 `hello`가 A의 디폴트 메서드 `hello`보다 우선권을 갖는다. 따라서 컴파일 에러가 발생하며, 클래스 D가 어떤 `hello`를 사용할지 명시적으로 선택해서 에러를 해결해야 한다.
|
||||
|
||||
>**C++ 다이아몬드 문제**
|
||||
>
|
||||
>`C++`의 다이아몬드 문제는 이보다 더 복잡하다. 우선 `C++`는 클래스의 다중 상속을 지원한다. 클래스 D가 클래스 B와 C를 상속받고 B와 C는 클래스 A를 상속받는다고 가정하자. 그러면 클래스 D는 B 객체와 C 객체의 복사본에 접근할 수 있다. 결과적으로 A의 메서드를 사용할 때 B의 메서드인지 C의 메서드인지 명시적으로 해결해야 한다. 또한 클래스는 상태를 가질 수 있으므로 B의 멤버 변수를 고쳐도 C 객체의 복사본에 반영되지 않는다.
|
||||
|
||||
같은 디폴트 메서드 시그니처를 갖는 여러 메서드를 상속받는 문제를 쉽게 해결할 수 있음을 살펴봤다. 다음과 같은 세 가지 규칙만 적용하면 모든 충돌 문제를 해결할 수 있다.
|
||||
|
||||
1. 클래스가 항상 이긴다. 클래스나 슈퍼클래스에서 정의한 메서드가 디폴트 메서드보다 우선권을 갖는다.
|
||||
2. 1번 규칙 이외의 상황에서는 서브인터페이스가 이긴다. 상속관계를 갖는 인터페이스에서 같은 시그니처를 갖는 메서드를 정의할 때는 서브인터페이스가 이긴다. 즉, B가 A를 상속받는다면 B가 A를 이긴다.
|
||||
3. 여전히 디폴트 메서드의 우선순위가 결정되지 않았다면 여러 인터페이스를 상속받는 클래스가 명시적으로 디폴트 메서드를 오버라이드하고 호출해야 한다.
|
||||
|
||||
---
|
||||
|
||||
## 13.5 마치며
|
||||
- 자바 8의 인터페이스는 구현 코드를 포함하는 디폴트 메서드, 정적 메서드를 정의할 수 있다.
|
||||
- 디폴트 메서드의 정의는 `default` 키워드로 시작하며 일반 클래스 메서드처럼 바디를 갖는다.
|
||||
- 공개된 인터페이스에 추상 메서드를 추가하면 소스 호환성이 깨진다.
|
||||
- 디폴트 메서드 덕분에 라이브러리 설계자가 API를 바꿔도 기존 버전과 호환성을 유지할 수 있다.
|
||||
- 선택형 메서드와 동작 다중 상속에도 디폴트 메서드를 사용할 수 있다.
|
||||
- 클래스가 같은 시그니처를 갖는 여러 디폴트 메서드를 상속하면서 생기는 충돌 문제를 해결하는 규칙이 있다.
|
||||
- 클래스나 슈퍼클래스에 정의된 메서드가 다른 디폴트 메서드 정의보다 우선한다. 이 외의 상황에서는 서브인터페이스에서 제공하는 디폴트 메서드가 선택된다.
|
||||
- 두 메서드의 시그니처가 같고, 상속관계로도 충돌 문제를 해결할 수 없을 때는 디폴트 메서드를 사용하는 클래스에서 메서드를 오버라이드해서 어떤 디폴트 메서드를 호출할지 명시적으로 결정해야 한다.
|
||||
|
||||
---
|
||||
@@ -0,0 +1,65 @@
|
||||
package Chapter13;
|
||||
|
||||
public class Monster implements Rotatable, Moveable, Resizable{
|
||||
|
||||
@Override
|
||||
public int getX() {
|
||||
return 0;
|
||||
}
|
||||
|
||||
@Override
|
||||
public int getY() {
|
||||
return 0;
|
||||
}
|
||||
|
||||
@Override
|
||||
public void setX(int x) {
|
||||
|
||||
}
|
||||
|
||||
@Override
|
||||
public void setY(int y) {
|
||||
|
||||
}
|
||||
|
||||
@Override
|
||||
public int getWidth() {
|
||||
return 0;
|
||||
}
|
||||
|
||||
@Override
|
||||
public int getHeight() {
|
||||
return 0;
|
||||
}
|
||||
|
||||
@Override
|
||||
public void setWidth(int width) {
|
||||
|
||||
}
|
||||
|
||||
@Override
|
||||
public void setHeight(int height) {
|
||||
|
||||
}
|
||||
|
||||
@Override
|
||||
public void setAbsoluteSize(int width, int height) {
|
||||
|
||||
}
|
||||
|
||||
@Override
|
||||
public void setRotationAngle(int angleInDegrees) {
|
||||
|
||||
}
|
||||
|
||||
@Override
|
||||
public int getRotationAngle() {
|
||||
return 0;
|
||||
}
|
||||
|
||||
public static void main(String[] args) {
|
||||
Monster m = new Monster();
|
||||
m.rotateBy(180);
|
||||
m.moveVertically(10);
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,16 @@
|
||||
package Chapter13;
|
||||
|
||||
public interface Moveable {
|
||||
int getX();
|
||||
int getY();
|
||||
void setX(int x);
|
||||
void setY(int y);
|
||||
|
||||
default void moveHorizontally(int distance) {
|
||||
setX(getX() + distance);
|
||||
}
|
||||
|
||||
default void moveVertically(int distance) {
|
||||
setY(getY() + distance);
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,13 @@
|
||||
package Chapter13;
|
||||
|
||||
public interface Resizable {
|
||||
int getWidth();
|
||||
int getHeight();
|
||||
void setWidth(int width);
|
||||
void setHeight(int height);
|
||||
void setAbsoluteSize(int width, int height);
|
||||
|
||||
default void setRelativeSize(int wFactor, int hFactor) {
|
||||
setAbsoluteSize(getWidth() / wFactor, getHeight() / hFactor);
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,9 @@
|
||||
package Chapter13;
|
||||
|
||||
public interface Rotatable {
|
||||
void setRotationAngle(int angleInDegrees);
|
||||
int getRotationAngle();
|
||||
default void rotateBy(int angleInDegrees) { // rotateBy 메서드의 기본 구현
|
||||
setRotationAngle((getRotationAngle() + angleInDegrees) % 360);
|
||||
}
|
||||
}
|
||||
33
도서/모던 자바 인 액션 (Modern Java In Action)/src/Chapter13/Sun.java
Normal file
@@ -0,0 +1,33 @@
|
||||
package Chapter13;
|
||||
|
||||
public class Sun implements Moveable, Rotatable{
|
||||
@Override
|
||||
public int getX() {
|
||||
return 0;
|
||||
}
|
||||
|
||||
@Override
|
||||
public int getY() {
|
||||
return 0;
|
||||
}
|
||||
|
||||
@Override
|
||||
public void setX(int x) {
|
||||
|
||||
}
|
||||
|
||||
@Override
|
||||
public void setY(int y) {
|
||||
|
||||
}
|
||||
|
||||
@Override
|
||||
public void setRotationAngle(int angleInDegrees) {
|
||||
|
||||
}
|
||||
|
||||
@Override
|
||||
public int getRotationAngle() {
|
||||
return 0;
|
||||
}
|
||||
}
|
||||
682
도서/모던 자바 인 액션 (Modern Java In Action)/src/Chapter14/Chapter14.md
Normal file
@@ -0,0 +1,682 @@
|
||||
# Chapter14. 자바 모듈 시스템
|
||||
- 자바 모듈 시스템에 대해서, [`니콜라이 팔로그 저, 『The Java Module System』(Manning Publications, 2019)`](https://www.manning.com/books/the-java-module-system) 를 살펴보길 권장한다.
|
||||
|
||||
---
|
||||
|
||||
## 14.1 압력 : 소프트웨어 유추
|
||||
- 모듈화란 무엇인가?
|
||||
- 모듈 시스템은 어떤 문제를 해결할 수 있는가?
|
||||
- 궁극적으로 소프트웨어 아키텍처 즉 고수준에서는 기반 코드를 바꿔야 할 때 유추하기 쉬우므로 생산성을 높일 수 있는 소프트웨어 프로젝트가 필요하다.
|
||||
- 추론하기 쉬운 소프트웨어를 만드는 데 도움을 주는 **`관심사분리(separation fo concerns)`**와 **`정보 은닉(information hiding)`**을 살펴보자.
|
||||
|
||||
### 14.1.1 관심사분리
|
||||
`관심사분리(SoC, Separation of concerns)`는 컴퓨터 프로그램을 고유의 기능으로 나누는 동작을 권장하는 원칙이다.
|
||||
- `SoC`를 적용함으로 각각의 기능들을 모듈이라는 각각의 부분 즉, 서로 거의 겹치지 않는 코드 그룹으로 분리할 수 있다.
|
||||
- 다시 말해 클래스를 그룹화한 모듈을 이용해 애플리케이션의 클래스 간의 관계를 시각적으로 보여줄 수 있다.
|
||||
- 자바 9 모듈은 클래스가 어떤 다른 클래스를 볼 수 있는지를 컴파일 시간에 정교하게 제어할 수 있다. 특히 자바 패키지는 모듈성을 지원하지 않는다(자바 패키지와 모듈은 다르다는 것을 말하는 듯 하다).
|
||||
|
||||
`SoC` 원칙은 모델, 뷰, 컨트롤러 같은 아키텍처 관점 그리고 복구 기법을 비즈니스 로직과 분리하는 등의 하위 수준 접근 등의 상황에 유용하다. `SoC` 원칙은 다음과 같은 장점을 제공한다.
|
||||
- 개별 기능을 따로 작업할 수 있으므로 팀이 쉽게 협업할 수 있다.
|
||||
- 개별 부분을 재사용하기 쉽다.
|
||||
- 전체 시스템을 쉽게 유지보수할 수 있다.
|
||||
|
||||
### 14.1.2 정보 은닉
|
||||
**`정보 은닉`**은 세부 구현을 숨기도록 장려하는 원칙이다.
|
||||
- 소프트웨어를 개발할 때 요구사항은 자주 바뀐다. 세부 구현을 숨김으로 프로그램의 어떤 부분을 바꿨을 때 다른 부분까지 영향을 미칠 가능성을 줄일 수 있다.
|
||||
- 즉 코드를 관리하고 보호하는 데 유용한 원칙이다.
|
||||
- **`캡슐화(encapsulation)`**는 특정 코드 조각이 애플리케이션의 다른 부분과 고립되어 있음을 의미한다.
|
||||
- 캡슐화된 코드의 내부적인 변화가 의도치 않게 외부에 영향을 미칠 가능성이 줄어든다.
|
||||
- 자바에서는 클래스 내의 컴포넌트에 적절하게 `private` 키워드를 사용했는지를 기준으로 컴파일러를 이용해 캡슐화를 확인할 수 있다.
|
||||
- 하지만 자바 9 이전까지는 **클래스와 패키지가 의도된 대로 공개되었는지**를 컴파일러로 확인할 수 있는 기능이 없었다.
|
||||
|
||||
### 14.1.3 자바 소프트웨어
|
||||
잘 설계된 소프트웨어를 만들려면 이 두 가지 원칙을 따르는 것이 필수다.
|
||||
- 자바는 객체 지향 언어로 클래스, 인터페이스를 이용한다.
|
||||
- 특정 문제와 관련된 패키지, 클래스, 인터페이스를 그룹으로 만들어 코드를 그룹화할 수 있다.
|
||||
- 코드 자체를 보고 소프트웨어의 동작을 추론하긴 현실적으로 어렵다.
|
||||
- 따라서 `UML 다이어그램`같은 도구를 이용하면 그룹 코드 간의 의존성을 시각적으로 보여줌으로써 소프트웨어를 추론하는데 도움을 받을 수 있다.
|
||||
|
||||
정보 은닉을 살펴보자.
|
||||
- 자바에서는 `public`, `protected`, `private` 등의 접근 제한자와 패키지 수준 접근 권한 등을 이용해 메서드, 필드 클래스의 접근을 제어했다.
|
||||
- 하지만 이런 방식으로는 원하는 접근 제한을 달성하기 어려우며 심지어 최종 사용자에게 원하지 않는 메서드도 공개해야 하는 상황이 발생했다.
|
||||
- 설계자는 자신의 클래스에서 개인적으로 사용할 용도라고 생각할 수 있으나, 결과적으로 클래스에 `public` 필드가 있다면 사용자 입장에서는 당연히 사용할 수 있다고 생각할 것이다.
|
||||
|
||||
모듈화의 장점을 살펴봤는데 다음으로는 자바의 모듈 지원이 어떤 변화를 가져왔는지 살펴보자.
|
||||
|
||||
---
|
||||
|
||||
## 14.2 자바 모듈 시스템을 설계한 이유
|
||||
여기서는 자바 언어와 컴파일러에 새로운 모듈 시스템이 추가된 이유를 설명한다. 먼저 자바 9 이전의 모듈화 한계를 살펴본다. 그리고 JDK 라이브러리와 관련한 배경 지식을 제공하고 모듈화가 왜 중요한지 설명한다.
|
||||
|
||||
### 14.2.1 모듈화의 한계
|
||||
안타깝게도, 자바 9 이전까지는 모듈화된 소프트웨어 프로젝트를 만드는 데 한계가 있었다.
|
||||
- 자바는 클래스, 패키지 `JAR` 세 가지 수준의 코드 그룹화를 제공한다.
|
||||
- 클래스와 관련해 자바는 접근 제한자와 캡슐화를 지원했다.
|
||||
- 하지만 패키지와 `JAR` 수준에서는 캡슐화를 거의 지원하지 않았다.
|
||||
|
||||
#### 제한된 가시성 제어
|
||||
자바는 정보를 감출 수 있는 접근자를 제공한다.
|
||||
- `public`, `protected`, 패키지 수준, `private` 이렇게 네 가지 가시성 접근자가 있다.
|
||||
- 한 패키지의 클래스와 인터페이스를 다른 패키지로 공겨하려면 `public`으로 이들을 선언해야 한다.
|
||||
- 결과적으로 이들 클래스와 인터페이스는 모두에게 공개된다. 이런 상황에서 보통 패키지 내부의 접근자가 `public`이므로 사용자가 이 내부 구현을 마음대로 사용할 수 있다.
|
||||
- 내부적으로 사용할 목적으로 만든 구현을 다른 프로그래머가 임시적으로 사용해서 정착해버릴 수 있으므로 결국 기존의 애플리케이션을 망가뜨리지 않고 라이브러리 코드를 바꾸기가 어려워진다.
|
||||
- 보안 측면에서 볼 때 코드가 노출되었으므로 코드를 임의로 조작하는 위협에 더 많이 노출될 수 있다.
|
||||
|
||||
#### 클래스 경로
|
||||
안타깝게도 애플리케이션을 번들하고 실행하는 기능과 관련해 자바는 태생적으로 약점을 갖고 있다.
|
||||
- 클래스를 모두 컴파일한 다음 보통 한 개의 평범한 `JAR` 파일에 넣고 클래스 경로(`class path`)에 이 `JAR` 파일을 추가해 사용할 수 있다.
|
||||
- 그러면 `JVM`이 동적으로 클래스 경로에 정의된 클래스를 필요할 때 읽는다.
|
||||
|
||||
안타깝게도 클래스 경로와 `JAR` 조합에는 몇 가지 약점이 존재한다.
|
||||
|
||||
##### 첫째. 클래스 경로에는 같은 클래스를 구분하는 버전 개념이 없다.
|
||||
예를 들어 파싱 라이브러리의 `JSONParser` 클래스를 지정할 때 버전 1.0을 사용하는지 버전 2.0을 사용하는지 지정할 수가 없으므로 클래스 경로에 두 가지 버전의 같은 라이브러리가 존재할 때 어떤 일이 일어날지 예측할 수 없다.
|
||||
다양한 컴포넌트가 같은 라이브러리의 다른 버전을 사용하는 상황이 발생할 수 있는 큰 애플리케이션에서 이런 문제가 두드러진다.
|
||||
|
||||
##### 둘째. 클래스 경로는 명시적인 의존성을 지원하지 않는다.
|
||||
각각의 `JAR` 안에 있는 모든 클래스는 `classes`라는 한 주머니로 합쳐진다.
|
||||
즉 한 `JAR`가 다른 `JAR`에 포함된 클래스 집합을 사용하라고 명시적으로 의존성을 정의하는 기능을 제공하지 않는다.
|
||||
이 상황에서는 클래스 경로 때문에 어떤 일이 일어나는지 파악하기 어려우며, 다음과 같은 의문이 든다.
|
||||
|
||||
- 빠진 게 있는가?
|
||||
- 충돌이 있는가?
|
||||
|
||||
메이븐이나 그레이들(`Gradle`) 같은 빌드 도구는 이런 문제를 해결하는 데 도움을 준다. 하지만 자바 9 이전에는 자바, `JVM` 누구도 명시적인 의존성 정의를 지원하지 않았다.
|
||||
결국 `JVM`이 `ClassNotFoundException` 같은 에러를 발생시키지 않고 애플리케이션을 정상적으로 실행할 때까지 클래스 경로에 클래스 파일을 더하거나 클래스 경로에서 클래스를 제거해보는 수밖에 없다.
|
||||
자바 9 모듈 시스템을 이용하면 컴파일 타임에 이런 종류의 에러를 모두 검출할 수 있다.
|
||||
|
||||
하지만 캡슐화, 클래스 경로 지옥 문제가 소프트웨어에만 발생하는 것은 아니다. `JDK` 자체는 괜찮을까?
|
||||
|
||||
### 14.2.2 거대한 JDK
|
||||
**`자바 개발 키트(JDK)`** 는 자바 프로그램을 만들고 실행하는 데 도움을 주는 도구의 집합이다.
|
||||
가장 익숙한 도구로 자바 프로그램을 컴파일하는 `javac`, 자바 애플리케이션을 로드하고 실행하는 `java`, 입출력을 포함해 런타임 지원을 제공하는 `JDK` 라이브러리, 컬렉션, 스트림 등이 있다.
|
||||
|
||||
하지만 때론 `JDK`가 애플리케이션에 불필요한 클래스를 포함하고 있는 경우가 있었고 이는 나중에 모바일에서 실행되는 애플리케이션이나 `JDK` 전부를 필요로 하지 않는 클라우드에서 문제가 되었다.
|
||||
자바 8에서는 **`컴팩트 프로파일(compact profiles)`**이라는 기법을 제시했다. 관련 분야에 따라 `JDK` 라이브러리가 세 가지 프로파일로 나뉘어 각각 다른 메모리 풋프린트를 제공했다.
|
||||
하지만 컴팩트 프로파일은 땜질식 처방일 뿐이다. `JDK` 라이브러리의 많은 내부 `API`는 공개되지 않아야 한다. 안타깝게도 자바 언어의 낮은 캡슐화 지원 때문에 내부 `API`가 외부에 공개되었다.
|
||||
예를 들어 `스프링(Spring)`, `네티(Netty)`, `모키토(Mockito)` 등 여러 라이브러리에서 `sun.misc.Unsafe`라는 클래스를 사용했는데 이 클래스는 `JDK` 내부에서만 사용하도록 만든 클래스다.
|
||||
결과적으로 호환성을 깨지않고는 관련 `API`를 바꾸기가 아주 어려운 상황이 되었다.
|
||||
|
||||
이런 문제들 때문에 `JDK` 자체도 모듈화할 수 있는 자바 모듈 시스템 설계의 필요성이 제기되었다.
|
||||
즉 `JDK`에서 필요한 부분만 골라 사용하고, 클래스 경로를 쉽게 유추할 수 있으며, 플랫폼을 진화시킬 수 있는 강력한 캡슐화를 제공할 새로운 건축 구조가 필요했다.
|
||||
|
||||
### 14.2.3 OSGi와 비교
|
||||
여기서는 자바 9 모듈을 `OSGi`와 비교한다. `OSGi`를 들어본 적이 없으므로 스킵한다.
|
||||
|
||||
---
|
||||
|
||||
## 14.3 자바 모듈 : 큰 그림
|
||||
자바 8은 **`모듈`**이라는 새로운 자바 프로그램 구조 단위를 제공한다. 모듈은 `module`이라는 새 키워드에 이름과 바디를 추가해서 정의한다.
|
||||
**`모듈 디스크립터(module descriptor)`**는 `module-info.java`라는 특별한 파일에 저장된다.
|
||||
|
||||
모듈 디스크립터는 보통 패키지와 같은 폴더에 위치하며 한 개 이상의 패키지를 서술하고 캡슐화할 수 있지만 단순한 상황에서는 이들 패키지 중 한 개만 외부로 노출시킨다.
|
||||
|
||||
`[그림 14-2]`는 자바 모듈 디스크립터의 핵심 구조를 보여준다.
|
||||
|
||||
##### 그림 14-2 자바 모듈 디스크립터의 핵심 구조(module-info.java)
|
||||
|
||||
|
||||
직소 퍼즐에 비유하자면 `exports`는 돌출부, `requires`는 패인 부분으로 생각할 수 있다.
|
||||
`[그림 14-3]`은 여러 모듈의 예를 보여준다.
|
||||
|
||||
##### 그림 14-3 A, B, C, D 네 개의 모듈로 만든 자바 시스템의 직소 퍼즐 형식 예제
|
||||
|
||||
|
||||
모듈 A는 모듈 B와 C를 필요로 하며 이들은 패키지 모듈 B와 모듈 C를 이용해 각각 pkgB와 pkgC에 접근할 수 있다.
|
||||
모듈 C는 비슷한 방법으로 pkgD를 사용하는데 pkgD는 모듈 C에서 필요로 하지만 모듈 B에서는 pkgD를 사용할 수 없다.
|
||||
|
||||
메이븐 같은 도구를 사용할 때 모듈의 많은 세부 사항을 IDE가 처리하며 사용자에게는 잘 드러나지 않는다.
|
||||
|
||||
---
|
||||
|
||||
## 14.4 자바 모듈 시스템으로 애플리케이션 개발하기
|
||||
여기서는 간단한 모듈화 애플리케이션을 기초부터 만들면서 자바 9 모듈 시스템 전반을 살펴본다.
|
||||
|
||||
### 14.4.1 애플리케이션 셋업
|
||||
다음과 같은 여러 작업을 처리해주는 애플리케이션을 구현해보자.
|
||||
- 파일이나 URL에서 비용 목록을 읽는다.
|
||||
- 비용의 문자열 표현을 파싱한다.
|
||||
- 통계를 계산한다.
|
||||
- 유용한 요약 정보를 표시한다.
|
||||
- 각 태스크의 시작, 마무리 지점을 제공한다.
|
||||
|
||||
애플리케이션의 개념을 모델링할 여러 클래스와 인터페이스를 정의해야 한다.
|
||||
먼저 `Reader` 인터페이스는 소스에서 얻어온 직렬화된 지출을 읽는 역할을 한다.
|
||||
소스가 어디냐에 따라 `HttpReader`, `FileReader` 등 여러 구현을 제공해야 한다.
|
||||
또한 `JSON` 객체를 자바 애플리케이션에서 사용할 수 있는 도메인 객체 `Expense`로 재구성할 `Parser` 인터페이스도 필요하다.
|
||||
마지막으로 주어진 `Expense` 객체 목록으로 통계를 계산하고 `SummaryStatistics` 객체를 반환하는 `SummaryCalculator` 클래스가 필요하다.
|
||||
|
||||
프로젝트에는 다음처럼 분리할 수 있는 여러 기능(관심사)이 있다.
|
||||
- 다양한 소스에서 데이터를 읽음(`Reader`, `HttpReader`, `FileReader`)
|
||||
- 다양한 포맷으로 구성된 데이터를 파싱(`Parser`, `JSONParser`, `ExpenseJSON - Parser`)
|
||||
- 도메인 객체를 구체화(`Expense`)
|
||||
- 통계를 계산하고 반환(`SummaryCalculator`, `SummaryStatistics`)
|
||||
- 다양한 기능을 분리 조정(`ExpensesApplication`)
|
||||
|
||||
교수법에 따라 아주 세부적으로 문제를 나누는 접근 방법을 이용한다.
|
||||
다음처럼 각 기능을 그룹화할 수 있다(모듈을 명명한 배경은 나중에 설명한다).
|
||||
- expense.readers
|
||||
- expense.readers.http
|
||||
- expense.readers.file
|
||||
- expense.parsers
|
||||
- expense.parsers.json
|
||||
- expense.model
|
||||
- expense.statistics
|
||||
- expense.application
|
||||
|
||||
이 간단한 애플리케이션에서는 모듈 시스템의 여러 부분이 두드러질 수 있도록 잘게 분해했다.
|
||||
실생활에서 단순한 프로젝트를 이처럼 잘게 분해해 작은 기능까지 캡슐화한다면 장점에 비해 초기 비용이 높아지고, 논란이 생길 수 있다.
|
||||
하지만 프로젝트가 점점 커지면서 많은 내부 구현이 추가되면 이때부터 캡슐화와 추론의 장점이 두드러진다.
|
||||
위에서 나열한 목록을 애플리케이션 경계에 의존하는 패키지 목록으로 생각할 수 있으며, 아마 각 모듈은 다른 모듈로 노출하고 싶지 않은 내부 구현을 포함할 것이다.
|
||||
예를 들어 `expenses.statistics` 모듈은 실험적인 통계 방법을 다른 방법으로 구현한 여러 패키지를 포함할 수 있다.
|
||||
이들 패키지에서 어떤 것을 사용자에게 릴리스할지는 나중에 결정할 수 있다.
|
||||
|
||||
### 14.4.2 세부적인 모듈화와 거친 모듈화
|
||||
시스템을 모듈화할 때 모듈 크기를 결정해야 한다.
|
||||
세부적인 모듈화 기법 대부분은 모든 패키지가 자신의 모듈을 갖는다.
|
||||
거친 모듈화 기법 대부분은 한 모듈이 시스템의 모든 패키지를 포함한다.
|
||||
첫 번째 기법은 이득에 비해 설계 비용이 증가하는 반면 두 번째 기법은 모듈화의 모든 장점을 잃는다.
|
||||
가장 좋은 방법은 시스템을 실용적으로 분해하면서 진화하는 소프트웨어 프로젝트가 이해하기 쉽고 고치기 쉬운 수준으로 적절하게 모듈화되어 있는지 주기적으로 확인하는 프로세스를 갖는 것이다.
|
||||
요약하면 모듈화는 소프트웨어 부식의 적이다.
|
||||
|
||||
### 14.4.3 자바 모듈 시스템 기초
|
||||
메인 애플리케이션을 지원하는 한 개의 모듈만 갖는 기본적인 모듈화 애플리케이션부터 시작하자. 다음은 디릭터리 안에 중첩된 프로젝트 디렉터리 구조를 보여준다.
|
||||
|
||||
```
|
||||
|-- expenses.application
|
||||
|-- module-info.java
|
||||
|-- com
|
||||
|-- example
|
||||
|-- expenses
|
||||
|-- application
|
||||
|-- ExpensesApplication.java
|
||||
```
|
||||
|
||||
정체를 알 수 없는 `module-info.java`라는 파일이 프로젝트 구조의 일부에 포함되어 있다.
|
||||
이 파일은 앞에서 설명한 모듈 디스크립터로 모듈의 소스 코드 파일 루트에 위치해야 하며 모듈의 의존성 그리고 어떤 기능을 외부로 노출할지를 정의한다.
|
||||
지출 애플리케이션 예제에서는 아직 다른 모듈에 의존하거나 외부로 노출하는 기능이 없으므로 최상위 수준의 `module-info.java` 파일에 이름만 정의되어 있을 뿐 내용은 비어있다.
|
||||
다음은 현재 `module-info.java`의 내용이다.
|
||||
|
||||
```java
|
||||
module expenses.application {
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
모듈화 애플리케이션은 어떻게 실행시킬 수 있을까? 하위 수준의 동작을 이해할 수 있는 일부 명령을 살펴보자.
|
||||
보통 IDE와 빌드 시스템에서 이들 명령을 자동으로 처리하지만 이들 명령이 어떤 동작을 수행하는지 확인하는 것은 내부적으로 어떤 일이 일어나는지 이해하는 데 도움이 된다.
|
||||
프로젝트의 모듈 소스 디렉터리에서 다음 명령을 실행한다.
|
||||
|
||||
```shell script
|
||||
javac module-info.java com/example/expenses/application/ExpensesApplication.java -d target
|
||||
|
||||
jar cvfe expenses-application.jar com.example.expenses.application.ExpensesApplication -C target
|
||||
```
|
||||
|
||||
그럼 어떤 폴더와 클래스 파일이 생성된 `JAR(expenses-application.jar)`에 포함되어 있는지를 보여주는 다음과 같은 결과가 출력된다.
|
||||
|
||||
```jvm
|
||||
added manifest
|
||||
added module-info: module-info.class adding: com/(in = 0) (out = 0)(stored 0%)
|
||||
adding: com/example/(in = 0) (out = 0)(stored 0%)
|
||||
adding: com/example/expenses/(in = 0) (out = 0)(stored 0%)
|
||||
adding: com/example/expenses/application/(in = 0) (out = 0)(stored 0%)
|
||||
adding: com/example/expenses/application/ExpensesApplication.class(in = 456) (out = 306)(deflated 32%)
|
||||
```
|
||||
|
||||
마지막으로 생성된 `JAR`를 모듈화 애플리케이션으로 실행한다.
|
||||
|
||||
```shell script
|
||||
java --module-path expenses-application.jar \
|
||||
--module expenses/com.example.expenses.application.ExpensesApplication
|
||||
```
|
||||
|
||||
처음 두 과정은 자바 애플리케이션을 `JAR`로 패키징하는 표준 방법이다.
|
||||
새로운 부분은 컴파일 과정에 새로 추가된 `module-info.java`다.
|
||||
|
||||
`java` 프로그램으로 자바 `.class` 파일을 실행할 때 다음과 같은 두 가지 옵션이 새로 추가되었다.
|
||||
- `--module-path` : 어떤 모듈을 로드할 수 있는지 지정한다. 이 옵션은 클래스 파일을 지정하는 `--classpath` 인수와는 다르다.
|
||||
- `--module` : 이 옵션은 실행할 메인 모듈과 클래스를 지정한다.
|
||||
|
||||
모듈 정의는 버전 문자열을 포함하지 않는다. 자바 9 모듈 시스템에서 버전 선택 문제를 크게 고려하지 않았고 따라서 버전 기능은 지원하지 않는다.
|
||||
대신 버전 문제는 빌드 도구나 컨테이너 애플리케이션에서 해결해야 할 문제로 넘겼다.
|
||||
|
||||
---
|
||||
|
||||
## 14.5 여러 모듈 활용하기
|
||||
모듈을 이용한 기본 애플리케이션을 실행했으므로 이제 다양한 모듈과 관련된 실용적인 예제를 살펴볼 수 있다.
|
||||
비용 애플리케이션이 소스에서 비용을 읽을 수 있어야 한다. 이 기능을 캡슐화한 `expense.reader`라는 새 모듈을 만들 것이다.
|
||||
`expenses.application`와 `expenses.readers` 두 모듈간의 상호 작용은 자바 9에서 지정한 `export`, `requires`를 이용해 이루어진다.
|
||||
|
||||
### 14.5.1 exports 구문
|
||||
다음은 `expenses.readers` 모듈의 선언이다
|
||||
|
||||
```java
|
||||
module expenses.readers {
|
||||
exports com.example.expenses.readers; // 모듈명이 아니라 패키지명이다.
|
||||
exports com.example.expenses.readers.file; // 모듈명이 아니라 패키지명이다.
|
||||
exports com.example.expenses.readers.http; // 모듈명이 아니라 패키지명이다.
|
||||
}
|
||||
```
|
||||
|
||||
`exports`라는 구문이 새로 등장했는데 `exports`는 다른 모듈에서 사용할 수 있도록 특정 패키지를 공개 형식으로 만든다.
|
||||
기본적으로 모듈 내의 모든 것은 캡슐화된다. 모듈 시스템은 화이트 리스트 기법을 이용해 강력한 캡슐화를 제공하므로 다른 모듈에서 사용할 수 있는 기능이 무엇인지 명시적으로 결정해야 한다(이 접근법은 실수로 어떤 기능을 외부로 노출함으로 몇 년이 지난 뒤에 해커가 시스템을 남용할 여지를 방지한다).
|
||||
|
||||
프로젝트의 두 모듈의 디렉터리 구조는 다음과 같다.
|
||||
|
||||
```jvm
|
||||
|-- expenses.application
|
||||
|-- module-info.java
|
||||
|-- com
|
||||
|-- example
|
||||
|-- expenses
|
||||
|-- application
|
||||
|-- ExpensesApplication.java
|
||||
|
||||
|-- expenses.readers
|
||||
|-- module-info.java
|
||||
|-- com
|
||||
|-- example
|
||||
|-- expenses
|
||||
|-- readers
|
||||
|-- Reader.java
|
||||
|-- file
|
||||
|-- FileReader.java
|
||||
|-- http
|
||||
|-- HttpReader.java
|
||||
```
|
||||
|
||||
### 14.5.2 requires 구문
|
||||
또는 다음처럼 `module-info.java`를 구현할 수 있다.
|
||||
|
||||
```java
|
||||
module expenses.readers {
|
||||
requires java.base; // 패키지명이 아니라 모듈명이다.
|
||||
|
||||
exports com.example.expenses.readers; // 모듈명이 아니라 패키지명이다.
|
||||
exports com.example.expenses.readers.file; // 모듈명이 아니라 패키지명이다.
|
||||
exports com.example.expenses.readers.http; // 모듈명이 아니라 패키지명이다.
|
||||
}
|
||||
```
|
||||
|
||||
`requires`라는 구문이 새로 등장했는데 `requires`는 의존하고 있는 모듈을 지정한다.
|
||||
기본적으로 모든 모듈은 `java.base`라는 플랫폼 모듈에 의존하는데 이 플랫폼 모듈은 `net`, `io`, `util` 등의 자바 메인 패키지를 포함한다.
|
||||
항상 기본적으로 필요한 모듈이므로 `java.base`는 명시적으로 정의할 필요가 없다.
|
||||
자바에서 `"class Foo extends Object { ... }"`처럼 하지 않고 `"class Foo { ... }"`처럼 클래스를 정의하는 것과 같은 원리다.
|
||||
|
||||
따라서 `java.base` 외의 모듈을 임포트할 때 `requires`를 사용한다.
|
||||
|
||||
자바 9에서는 `requires`와 `exports` 구문을 이용해 좀 더 정교하게 클래스 접근을 제어할 수 있다.
|
||||
|
||||
##### 표 14-2 자바 9는 클래스 가시성을 더 잘 제어할 수 있는 기능을 제공
|
||||
|클래스 가시성|자바 9 이전| 자바 9 이후|
|
||||
|--|--|--|
|
||||
|모든 클래스가 모두에 공개됨|O|O (`exports`와 `requires` 구분 혼합)|
|
||||
|제한된 클래스만 공개됨|X|O (`exports`와 `requires` 구분 혼합)|
|
||||
|한 모듈의 내에서만 공개|X|O (`export` 구문 없음)|
|
||||
|Protected|O|O|
|
||||
|Package|O|O|
|
||||
|Private|O|O|
|
||||
|
||||
### 14.5.3 이름 정하기
|
||||
지금까지 `expenses.application`처럼 모듈과 패키지의 개념이 혼동되지 않도록 단순한 접근 방식을 사용했다(모듈은 여러 패키지를 노출시킬 수 있다).
|
||||
하지만 이 방법은 권장 사항과 일치하지 않는다.
|
||||
|
||||
오라클은 패키지명처럼 인터넷 도메인명을 역순(예를 들어 `com.iteratrlearning.training`)으로 모듈의 이름을 정하도록 권고한다.
|
||||
더욱이 모듈명은 노출된 주요 `API` 패키지와 이름이 같아야 한다는 규칙도 따라야 한다.
|
||||
모듈이 패키지를 포함하지 않거나 어떤 다른 이유로 노출된 패키지 중 하나와 이름이 일치하지 않는 상황을 제외하면 모듈명은 작성자의 도메인명을 역순으로 시작해야 한다.
|
||||
|
||||
여러 모듈을 프로젝트에 설정하는 방법을 살펴봤으므로 이제 이들을 패키지하고 실행하는 방법을 살펴보자.
|
||||
|
||||
---
|
||||
|
||||
## 14.6 컴파일과 패키징
|
||||
프로젝트를 설정하고 모듈을 정의하는 방법을 이해했으므로 메이븐 등의 빌드 도구를 이용해 프로젝트를 컴파일할 수 있다.
|
||||
|
||||
먼저 각 모듈에 `pom.xml`을 추가해야 한다. 사실 각 모듈은 독립적으로 컴파일되므로 자체적으로 각각이 한 개의 프로젝트다.
|
||||
전체 프로젝트 빌드를 조정할 수 있도록 모든 모듈의 부모 모듈에도 `pom.xml`을 추가한다. 전체 구조는 다음과 같다.
|
||||
|
||||
```jvm
|
||||
|-- pom.xml
|
||||
|-- expenses.application
|
||||
|-- pom.xml
|
||||
|-- src
|
||||
|-- main
|
||||
|-- java
|
||||
|-- module-info.java
|
||||
|-- com
|
||||
|-- example
|
||||
|-- expenses
|
||||
|-- application
|
||||
|-- ExpensesApplication.java
|
||||
|-- expenses.readers
|
||||
|-- pom.xml
|
||||
|-- src
|
||||
|-- main
|
||||
|-- java
|
||||
|-- module-info.java
|
||||
|-- com
|
||||
|-- example
|
||||
|-- expenses
|
||||
|-- readers
|
||||
|-- Reader.java
|
||||
|-- file
|
||||
|-- FileReader.java
|
||||
|--http
|
||||
|-- HttpReader.java
|
||||
```
|
||||
|
||||
이렇게 세 개의 `pom.xml` 파일을 추가해 메이븐 디렉터리 프로젝트 구조를 완성했다.
|
||||
모듈 디스크립터(`module-info.java`)는 `src/main/java` 디렉터리에 위치해야 한다.
|
||||
올바른 모듈 소스 경로를 이용하도록 메이븐이 `javac`를 설정한다.
|
||||
|
||||
다음은 `expenses.readers` 프로젝트의 `pom.xml`이다.
|
||||
|
||||
```xml
|
||||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<project xmlns="http://maven.apache.org/POM/4.0.0">
|
||||
<modelVersion>4.0.0</modelVersion>
|
||||
|
||||
<groupId>com.example</groupId>
|
||||
<artifactId>expenses.readers</artifactId>
|
||||
<version>1.0</version>
|
||||
<packaging>jar</packaging>
|
||||
<parent>
|
||||
<groupId>com.example</groupId>
|
||||
<artifactId>expenses</artifactId>
|
||||
<version>1.0</version>
|
||||
</parent>
|
||||
</project>
|
||||
```
|
||||
|
||||
순조롭게 빌드될 수 있도록 명시적으로 부모 모듈을 지정한 코드를 주목하자.
|
||||
부모는 `ID expenses`를 포함하는 `부산물(artifact)`이다. 곧 살펴보겠지만 `pom.xml`에 부모를 정의해야 한다.
|
||||
|
||||
다음으로 `expenses.application` 모듈의 `pom.xml`을 정의한다.
|
||||
이 파일을 이전 파일과 비슷하지만 `ExpenseApplication`이 필요로 하는 클래스와 인터페이스가 있으므로 `expenses.readers`를 의존성으로 추가해야 한다.
|
||||
|
||||
```xml
|
||||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<project xmlns="http://maven.apache.org/POM/4.0.0">
|
||||
<modelVersion>4.0.0</modelVersion>
|
||||
|
||||
<groupId>com.example</groupId>
|
||||
<artifactId>expenses.application</artifactId>
|
||||
<version>1.0</version>
|
||||
<packaging>jar</packaging>
|
||||
|
||||
<parent>
|
||||
<groupId>com.example</groupId>
|
||||
<artifactId>expenses</artifactId>
|
||||
<version>1.0</version>
|
||||
</parent>
|
||||
|
||||
<dependencies>
|
||||
<dependency>
|
||||
<groupId>com.example</groupId>
|
||||
<artifactId>expenses.readers</artifactId>
|
||||
<version>1.0</version>
|
||||
</dependency>
|
||||
</dependencies>
|
||||
|
||||
</project>
|
||||
```
|
||||
|
||||
`expenses.application`와 `expenses.readers` 두 모듈에 `pom.xml`을 추가했으므로 이제 빌드 과정을 가이드할 전역 `pom.xml`을 설정할 차례다.
|
||||
메이븐은 특별한 `XML` 요소 `<module>(자식의 부산물 ID를 참조)`을 가진 여러 메이븐 모듈을 가진 프로젝트를 지원한다.
|
||||
다음은 두 개의 자식 모듈 `expenses.application`와 `expenses.readers`를 참조하도록 완성한 `pom.xml` 정의다.
|
||||
|
||||
```xml
|
||||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<project xmlns="http://maven.apache.org/POM/4.0.0">
|
||||
<modelVersion>4.0.0</modelVersion>
|
||||
|
||||
<groupId>com.example</groupId>
|
||||
<artifactId>expenses</artifactId>
|
||||
<packaging>pom</packaging>
|
||||
<version>1.0</version>
|
||||
|
||||
<modules>
|
||||
<module>expenses.application</module>
|
||||
<module>expenses.readers</module>
|
||||
</modules>
|
||||
|
||||
<build>
|
||||
<pluginManagement>
|
||||
<plugins>
|
||||
<plugin>
|
||||
<groupId>org.apache.maven.plugins</groupId>
|
||||
<artifactId>maven-compiler-plugin</artifactId>
|
||||
<version>3.7.0</version>
|
||||
<configuration>
|
||||
<source>9</source>
|
||||
<target>9</target>
|
||||
</configuration>
|
||||
</plugin>
|
||||
</plugins>
|
||||
</pluginManagement>
|
||||
</build>
|
||||
|
||||
</project>
|
||||
```
|
||||
|
||||
이제 `mvn clean package` 명령을 실행해서 프로젝트의 모듈을 `JAR`로 만들 수 있다. 다음과 같은 부산물이 만들어진다.
|
||||
|
||||
```shell script
|
||||
./expenses.application/target/expenses.application-1.0.jar
|
||||
./expenses.readers/target/expenses.readers-1.0.jar
|
||||
```
|
||||
|
||||
두 `JAR`를 다음처럼 모듈 경로에 포함해서 모듈 애플리케이션을 실행할 수 있다.
|
||||
|
||||
```shell script
|
||||
java --module-path \
|
||||
./expenses.application/target/expenses.application-1.0.jar:\
|
||||
./expenses.readers/target/expenses.readers-1.0.jar \
|
||||
--module \
|
||||
expenses.application/com.example.expenses.application.ExpensesApplication
|
||||
```
|
||||
|
||||
지금까지 모듈을 만드는 방법을 배웠으며 `requires`로 `java.base`를 참조하는 방법도 살펴봤다.
|
||||
하지만 실세계에서는 `java.base` 대신 외부 모듈과 라이브러리를 참조해야 한다.
|
||||
이 과정은 어떻게 동작하며 기존 라이브러리가 명시적으로 `module-info.java`를 사용하도록 업데이트되지 않았을 때 어떤 일이 일어나는지 알아보자.
|
||||
|
||||
---
|
||||
|
||||
## 14.7 자동 모듈
|
||||
`HttpReader`를 저수준으로 구현하지 않고 아파치 프로젝트의 `httpclient` 같은 특화 라이브러리를 사용해 구현한다고 가정하자.
|
||||
이런 라이브러리는 어떻게 프로젝트에 추가할 수 있을까?
|
||||
`requires` 구문을 배웠으므로 `expenses.readers` 프로젝트의 `module-info.java`에 이 구문을 추가한다.
|
||||
`mvn clean package`를 다시 실행해서 어떤 일이 일어나는지 확인하자. 안타깝게도 나쁜 일이 일어난다.
|
||||
|
||||
`[ERROR] module not found: httpclient`
|
||||
|
||||
의존성을 기술하도록 `pom.xml`도 갱신해야 하므로 에러가 발생한다.
|
||||
메이븐 컴파일러 플러그인은 `module-info.java`를 포함하는 프로젝트를 빌드할 때 모든 의존성 모듈을 경로에 놓아 적절한 `JAR`를 내려받고 이들이 프로젝트에 인식되도록 한다.
|
||||
다음과 같은 의존성이 필요하다.
|
||||
|
||||
```xml
|
||||
<dependencies>
|
||||
<dependency>
|
||||
<groupId>org.apache.httpcomponents</groupId>
|
||||
<artifactId>httpclient</artifactId>
|
||||
<version>4.5.3</version>
|
||||
</dependency>
|
||||
</dependencies>
|
||||
```
|
||||
|
||||
이제 `mvn clean package`를 실행하면 프로젝트가 올바로 빌드된다. 하지만 `httpclient`는 자바 모듈이 아니다.
|
||||
`httpclient`는 자바 모듈로 사용하려는 외부 라이브러리인데 모듈화가 되어 있지 않은 라이브러리다.
|
||||
자바는 `JAR`를 자동 모듈이라는 형태로 적절하게 변환한다. 모듈 경로상에 있으나 `module-info` 파일을 가지지 않은 모든 `JAR`는 자동 모듈이 된다.
|
||||
자동 모듈은 암묵적으로 자신의 모든 패키지를 노출시킨다. 자동 모듈의 이름은 `JAR` 이름을 이용해 정해진다.
|
||||
`jar` 도구의 `--describe-module` 인수를 이용해 자동으로 정해지는 이름을 바꿀 수 있다.
|
||||
|
||||
```shell script
|
||||
jar --file=./expenses.readers/target/dependency/httpclient-4.5.3.jar \
|
||||
--describe-module httpclient@4.5.3 automatic
|
||||
```
|
||||
|
||||
그러면 `httpclient`라는 이름으로 정의된다.
|
||||
|
||||
마지막으로 `httpclient JAR`를 모듈 경로에 추가한 다음 애플리케이션을 실행한다.
|
||||
|
||||
```shell script
|
||||
java --module-path \
|
||||
./expenses.application/target/expenses.application-1.0.jar:\
|
||||
./expenses.readers/target/expenses.readers-1.0.jar \
|
||||
./expenses.readers/target/dependency/httpclient-4.5.3.jar \
|
||||
--module \
|
||||
expenses.application/com.example.expenses.application.ExpensesApplication
|
||||
```
|
||||
|
||||
>**NOTE**
|
||||
>
|
||||
>메이븐에는 자바 9 모듈 시스템을 더 잘 지원하는 프로젝트(https://github.com/moditect/moditect)가 있다. 이 프로젝트는 `module-info` 파일을 자동으로 생성한다.
|
||||
|
||||
---
|
||||
|
||||
## 14.8 모듈 정의와 구문들
|
||||
여기서는 모듈 정의 언어에서 사용할 수 있는 몇 가지 키워드를 간단하게 소개한다.
|
||||
|
||||
앞에서 서술한 것처럼 `module` 지시어를 이용해 모듈을 정의할 수 있다. 다음은 `com.iteratrlearning.application`이라는 모듈명의 예제다.
|
||||
|
||||
```java
|
||||
module com.iteratrlearning.application {
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
모듈 정의에는 어떤 내용을 넣을 수 있을까?
|
||||
`requires`, `exports` 구문을 배웠지만 이 외에 `requires-transitive`, `exports-to`, `open`, `opens`, `uses`, `provides` 같은 다른 구문들도 있다.
|
||||
지금부터 이들 구문을 하나씩 살펴본다.
|
||||
|
||||
### 14.8.1 requires
|
||||
`requires` 구문은 컴파일 타임과 런타임에 한 모듈이 다른 모듈에 의존함을 정의한다. 예를 들어 `com.iteratrlearning.application`은 `com.iteratrlearning.ui` 모듈에 의존한다.
|
||||
|
||||
```java
|
||||
module com.iteratrlearning.application {
|
||||
requires com.iteratrlearning.ui;
|
||||
}
|
||||
```
|
||||
|
||||
그러면 `com.iteratrlearning.ui`에서 외부로 노출한 공개 형식을 `com.iteratrlearning.application`에서 사용할 수 있다.
|
||||
|
||||
### 14.8.2 exports
|
||||
`exports` 구문은 지정한 패키지를 다른 모듈에서 이용할 수 있도록 공개 형식으로 만든다. 아무 패키지도 공개하지 않는 것이 기본 설정이다.
|
||||
어떤 패키지를 공개할 것인지를 명시적으로 지정함으로 캡슐화를 높일 수 있다.
|
||||
다음 예제에서는 `com.iteratrlearning.ui.panels`와 `com.iteratrlearning.ui.widgets`를 공개했다
|
||||
(참고로 문법이 비슷함에도 불구하고 `exports`는 **패키지명**을 인수로 받지만 `requires`는 **모듈명**을 인수로 받는다는 사실에 주의하자).
|
||||
|
||||
```java
|
||||
module com.iteratrlearning.ui {
|
||||
requires com.iteratrlearning.core;
|
||||
exports com.iteratrlearning.ui.panels;
|
||||
exports com.iteratrlearning.ui.widgets;
|
||||
}
|
||||
```
|
||||
|
||||
### 14.8.3 requires transitive
|
||||
다른 모듈이 제공하는 공개 형식을 한 모듈에서 사용할 수 있다고 지정할 수 있다.
|
||||
예를 들어 `com.iteratrlearning.ui` 모듈의 정의에서 `requires`를 `requires-transitive`로 바꿀 수 있다.
|
||||
|
||||
```java
|
||||
module com.iteratrlearning.ui {
|
||||
requires transitive com.iterartlearning.core;
|
||||
|
||||
exports com.iteratrlearning.ui.panels;
|
||||
exports com.iteratrlearning.ui.widgets;
|
||||
}
|
||||
|
||||
module com.iteratrlearning.application {
|
||||
requires com.iteratrlearning.ui;
|
||||
}
|
||||
```
|
||||
|
||||
결과적으로 `com.iteratrlearning.application` 모듈은 `com.iteratrlearning.core`에서 노출한 공개 형식에 접근할 수 있다.
|
||||
필요로 하는 모듈(`com.iteratrlearning.ui`)이 다른 모듈(`com.iteratrlearning.core`)의 형식을 변환하는 상황에서 `전이성(transitivity)` 선언을 유용하게 사용할 수 있다.
|
||||
`com.iteratrlearning.application` 모듈의 내부에 `com.iteratrlearning.core` 모듈을 다시 선언하는 것은 성가신 일이기 때문이다.
|
||||
따라서 이런 상황에서는 `transitive`를 이용해 문제를 해결할 수 있다.
|
||||
`com.iteratrlearning.io` 모듈에 의존하는 모든 모듈은 자동으로 `com.iteratrlearning.core` 모듈을 읽을 수 있게 된다.
|
||||
|
||||
### 14.8.4 exports to
|
||||
`exports to` 구문을 이용해 사용자에게 공개할 기능을 제한함으로 가시성을 좀 더 정교하게 제어할 수 있다.
|
||||
`14.8.2`에서 살펴본 예제에서 다음처럼 `exports to`를 이용하면 `com.iteratrlearning.ui.widgets`의 접근 권한을 가진 사용자의 권한을 `com.iteratrlearning.ui.widgetuser`로 제한할 수 있다.
|
||||
|
||||
```java
|
||||
module com.iteratrlearning.ui {
|
||||
requires com.iteratrlearning.core;
|
||||
|
||||
exports com.iteratrlearning.ui.panels;
|
||||
exports com.iteratrlearning.ui.widgets to com.iteratrlearning.ui.widgetuser;
|
||||
}
|
||||
```
|
||||
|
||||
### 14.8.5 open과 opens
|
||||
모듈 선언에 `open` 한정자를 이용하면 모든 패키지를 다른 모듈에 반사적으로 접근을 허용할 수 있다.
|
||||
다음 예제에서 보여주는 것처럼 반사적인 접근 권한을 주는 것 이외에 `open` 한정자는 모듈의 가시성에 다른 영향을 미치지 않는다.
|
||||
|
||||
```java
|
||||
open module com.iteratrlearning.ui {
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
자바 9 이전에는 리플렉션으로 객체의 비공개 상태를 확인할 수 있었다. 즉 진정한 캡슐화는 존재하지 않았다.
|
||||
하이버네이트(`Hibernate`) 같은 객체 관계 매핑(`Object-relational mapping`-`ORM`) 도구에서는 이런 기능을 이용해 상태를 직접 고치곤 한다.
|
||||
자바 9에서는 기본적으로 리플렉션이 이런 기능을 허용하지 않는다. 이제 그런 기능이 필요하면 이전 코드에서 설명한 `open` 구문을 명시적으로 사용해야 한다.
|
||||
|
||||
리플렉션 떄문에 전체 모듈을 개방하지 않고도 `opens` 구문을 모듈 선언에 이용해 필요한 개별 패키지만 개방할 수 있다.
|
||||
`exports-to`로 노출한 패키지를 사용할 수 있는 모듈을 한정했던 것처럼, `open`에 `to`를 붙여서 반사적인 접근을 특정 모듈에만 허용할 수 있다.
|
||||
|
||||
### 14.8.6 uses와 provides
|
||||
자바 모듈 시스템은 `provides` 구문으로 서비스 제공자를 `uses` 구문으로 서비스 소비자를 지정할 수 있는 기능을 제공하는데 서비스와 `ServiceLoader`를 알고 있다면 친숙한 내용일 것이다.
|
||||
만약 모듈과 서비스 로더를 합치는 기법에 관심이 있다면 앞서 언급했던 `『The Java Module System』`을 살펴보길 추천한다.
|
||||
|
||||
---
|
||||
|
||||
## 14.9 더 큰 예제 그리고 더 배울 수 있는 방법
|
||||
오라클의 자바 문서에서 가져온 다음 예제로 모듈 시스템이 어떤 것인지 더 확인할 수 있다.
|
||||
아래 예제는 여기서 설명한 기능의 대부분을 모듈 선언에 사용한다.
|
||||
|
||||
```java
|
||||
module com.example.foo {
|
||||
requires com.example.foo.http;
|
||||
requires java.logging;
|
||||
requires transitive com.example.foo.network;
|
||||
|
||||
exports com.example.foo.bar;
|
||||
exports com.example.foo.internal to com.example.foo.probe;
|
||||
|
||||
opens com.example.foo.quux;
|
||||
opens com.example.foo.internal to com.example.foo.network, com.example.foo.probe;
|
||||
|
||||
uses com.example.foo.spi.Intf;
|
||||
provides com.example.foo.spi.Intf with com.example.foo.Impl;
|
||||
}
|
||||
```
|
||||
|
||||
이때까지 새로운 자바 모듈 시스템의 필요성을 설명하고 주요 기능을 간단하게 소개했다.
|
||||
이 외에도 서비스 로더나 추가 모듈 서술자, `jeps`, `jlink` 같은 모듈 관련 도구들이 있다.
|
||||
`자바 EE` 개발자라면 애플리케이션을 자바 9로 이전할 때 `EE`와 관련한 여러 패키지가 모듈화된 자바 9 가상 머신에서 기본적으로 로드되지 않는다는 사실을 기억해야 한다.
|
||||
예를 들어 `JAXB API` 클래스는 이제 `자바 EE API`로 간주되므로 `자바 SE 9`의 기본 클래스 경로에 더는 포함되지 않는다.
|
||||
따라서 호환성을 유지하려면 `--add-modules` 명령행을 이용해 명시적으로 필요한 모듈을 추가해야 한다.
|
||||
예를 들어 `java.xml.bind`가 필요하면 `--add-modules java.xml.bind`를 지정해야 한다.
|
||||
|
||||
---
|
||||
|
||||
## 14.10 마치며
|
||||
- 관심사분리와 정보 은닉은 추론하기 쉬운 소프트웨어를 만드는 중요한 두 가지 원칙이다.
|
||||
- 자바 9 이전에는 각각의 기능을 담당하는 패키지, 클래스, 인터페이스로 모듈화를 구현했는데 효과적인 캡슐화를 달성하기에는 역부족이었다.
|
||||
- 클래스 경로 지옥 문제는 애플리케이션의 의존성을 추론하기 더욱 어렵게 만들었다.
|
||||
- 자바 9 이전의 `JDK`는 거대했으며 높은 유지 비용과 진화를 방해하는 문제가 존재했다.
|
||||
- 자바 9에서는 새로운 모듈 시스템을 제공하는데 `module-info.java` 파일은 모듈의 이름을 지정하며 `필요한 의존성(requires)`과 `공개 API(exports)`를 정의한다.
|
||||
- `requires` 구문으로 필요한 다른 모듈을 정의할 수 있다.
|
||||
- `exports` 구문으로 특정 패키지를 다른 모듈에서 사용할 수 있는 공개 형식으로 지정할 수 있다.
|
||||
- 인터넷 도메인명을 역순으로 사용하는 것이 권장 모듈 이름 규칙이다.
|
||||
- 모듈 경로에 포함된 `JAR` 중에 `module-info` 파일을 포함하지 않는 모든 `JAR`는 자동 모듈이 된다.
|
||||
- 자동 모듈은 암묵적으로 모든 패키지를 공개한다.
|
||||
- 메이븐은 자바 9 모듈 시스템으로 구조화된 애플리케이션을 지원한다.
|
||||
|
||||
---
|
||||
|
||||
|
||||
{kind=link}
|
After Width: | Height: | Size: 20 KiB |
{kind=link}
|
After Width: | Height: | Size: 14 KiB |
940
도서/모던 자바 인 액션 (Modern Java In Action)/src/Chapter15/Chapter15.md
Normal file
@@ -0,0 +1,940 @@
|
||||
# Chapter15. CompletableFuture와 리액티브 프로그래밍 컨셉의 기초
|
||||
- 요즘에는 독립적으로만 동작하는 웹사이트나 네트워크 애플리케이션을 찾아보기 힘들다.
|
||||
- 즉 앞으로 만들 웹 애플리케이션은 다양한 소스의 콘텐츠를 가져와서 사용자가 삶을 풍요롭게 만들도록 합치는 `매시업(mashup)` 형태가 될 가능성이 크다.
|
||||
|
||||
##### 그림 15-1 일반 매시업 애플리케이션
|
||||
|
||||
|
||||
이런 애플리케이션을 구현하려면 인터넷으로 여러 웹 서비스에 접근해야 한다. 하지만 이들 서비스의 응답을 기다리는 동안 연산이 블록되거나 귀중한 CPU 클록 사이클 자원을 낭비하고 싶진 않다.
|
||||
예를 들어 페이스북의 데이터를 기다리는 동안 트위터 데이터를 처리하지 말란 법은 없다.
|
||||
|
||||
이 상황은 멀티태스크 프로그래밍의 양면성을 보여준다. 이전에 설명한 포크/조인 프레임워크와 병렬 스트림은 병렬성의 귀중한 도구다. 이들은 한 태스크를
|
||||
여러 하위 태스크로 나눠서 CPU의 다른 코어 또는 다른 머신에서 이들 하위 태스크를 병렬로 실행한다.
|
||||
|
||||
반면 병렬성이 아니라 동시성을 필요로 하는 상황 즉 조금씩 연관된 작업을 같은 CPU에서 동작하는 것 또는 애플리케이션을 생산성을 극대화할 수 있도록
|
||||
코어를 바쁘게 유지하는 것이 목표라면, 원격 서비스나 데이터베이스 결과를 기다리는 스레드를 블록함으로 연산 자원을 낭비하는 일은 피해야 한다.
|
||||
|
||||
자바는 이런 환경에서 사용할 수 있는 두 가지 주요 도구를 제공한다.
|
||||
- 첫 번째는 `Future` 인터페이스로, 자바 8의 `CompletableFuture` 구현은 간단하고 효율적인 문제 해결사다.
|
||||
- 최근 자바 9에 추가된 발행 구독 프로토콜에 기반한 리액티브 프로그래밍 개념을 따르는 플로 API는 조금 더 정교한 프로그래밍 접근 방법을 제공한다.
|
||||
|
||||
[그림 15-2]는 동시성과 별렬성의 차이를 보여준다. 동시성은 단일 코어 머신에서 발생할 수 있는 프로그래밍 속성으로 실행이 서로 겹칠 수 있는 반면
|
||||
병렬성은 실행을 하드웨어 수준에서 지원한다.
|
||||
|
||||
##### 그림 15-2 동시성 대 병렬성
|
||||
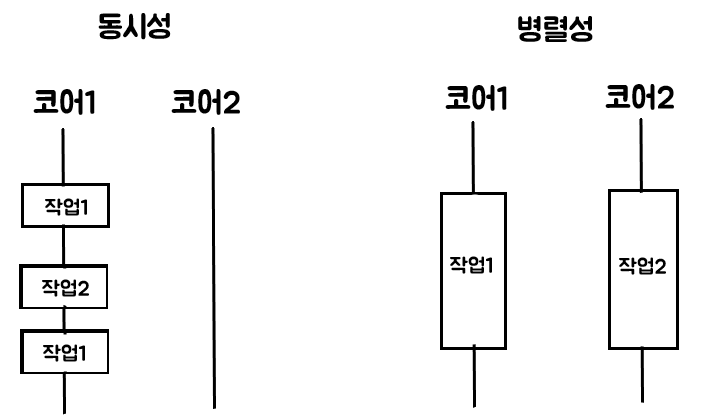
|
||||
|
||||
여기서는 자바의 새로운 기능인 `CompletableFuture`와 `플로 API`의 기초를 구성하는 내용을 설명한다.
|
||||
다양한 자바 동시성 기능을 이용해 결과를 얻는지 등의 예제를 이용해 대부분의 개념을 설명한다.
|
||||
|
||||
---
|
||||
|
||||
## 15.1 동시성을 구현하는 자바 지원의 진화
|
||||
처음에 자바는 `Runnable`과 `Thread`를 동기화된 클래스와 메서드를 이용해 잠갔다.
|
||||
2004년, 자바 5는 좀 더 표현력 있는 동시성을 지원하는 특히 스레드 실행과 태스크 제출을 분리하는 `ExecutorService` 인터페이스,
|
||||
높은 수준의 결과 즉, `Runnable`, `Thread`의 변형을 반환하는 `Callable<T> and Future<T>`, `제네릭` 등을 지원했다.
|
||||
`ExecutorServices`는 `Runnable`과 `Callable` 둘 다 실행할 수 있다. 이런 기능들 덕분에 다음 해부터 등장한 멀티코어 CPU에서
|
||||
쉽게 병렬 프로그래밍을 구현할 수 있게 되었다.
|
||||
|
||||
멀티코어 CPU에서 효과적으로 프로그래밍을 실행할 필요성이 커지면서 이후 자바 버전에서는 개선된 동시성 지원이 추가되었다.
|
||||
자바 7에서는 분할 그리고 정복 알고리즘의 포크/조인 구현을 지원하는 `java.util.concurrent.RecursiveTask`가 추가되었고
|
||||
자바 8에서는 스트림과 새로 추가된 람다 지원에 기반한 병렬 프로세싱이 추가되었다.
|
||||
|
||||
자바는 `Future`를 조합하는 기능을 추가하면서 동시성을 강화(`Future`구현인 자바 8 `CompletableFuture`)했고,
|
||||
자바 9에서는 분산 비동기 프로그래밍을 명시적으로 지원한다. 이들 API는 15장 처음 부분에서 언급했던 매쉬업 애플리케이션 즉, 다양한 웹 서비스를 이용하고
|
||||
이들 정보를 실시간으로 조합해 사용자에게 제공하거나 추가 웹 서비스를 통해 제공하는 종류의 애플리케이션을 개발하는데 필수적인 기초 모델과 툴킷을 제공한다.
|
||||
이 과정을 리액티브 프로그래밍이라 부르며 자바 9에서는 발행-구독 프로토콜(`java.util.concurrent.Flow` 인터페이스 추가)로 이를 지원한다.
|
||||
`CompletableFuture`와 `java.util.concurrent.Flow`의 궁극적인 목표는 가능한한 동시에 실행할 수 있는 독립적인 태스크를 가능하게 만들면서
|
||||
멀티코어 또는 여러 기기를 통해 제공되는 병렬성을 쉽게 이용하는 것이다.'
|
||||
|
||||
### 15.1.1 스레드와 높은 수준의 추상화
|
||||
단일 CPU 컴퓨터도 여러 사용자를 지원할 수 있는데 이는 운영체제가 각 사용자에 프로세스 하나를 할당하기 때문이다.
|
||||
운영체제는 두 사용자가 각각 자신만의 공간에 있다고 생각할 수 있도록 가상 주소 공간을 각각의 프로세스에 제공한다.
|
||||
운영체제는 주기적으로 번갈아가며 각 프로세스에 CPU를 할당한다. 프로세스는 다시 운영체제에 한 개 이상의 `스레드` 즉, 본인이 가진 프로세스와 같은
|
||||
주소 공간을 공유하는 프로세스를 요청함으로 태스크를 동시에 또는 협력적으로 실행할 수 있다.
|
||||
|
||||
멀티코어 설정(한 사용자 프로세스만 실행하는 한명의 사용자 노트북)에서는 스레드의 도움 없이 프로그램이 노트북의 컴퓨팅 파워를 모두 활용할 수 없다.
|
||||
각 코어는 한 개 이상의 프로세스나 스레드에 할당될 수 있지만 프로그램이 스레드를 사용하지 않는다면 효율성을 고려해 여러 프로세서 코어 중 한 개만을 사용할 것이다.
|
||||
|
||||
실제로 네 개의 코어를 가진 CPU에서 이론적으로는 프로그램을 네 개의 코어에서 병렬로 실행함으로 실행 속도를 네 배까지 향상시킬 수 있다(물론 오버헤드로 인해 실제 네 배가 되긴 어렵다).
|
||||
|
||||
다음은 학생들이 제출한 숫자 1,000,000개를 저장한 배열을 처리하는 예제이다.
|
||||
|
||||
```java
|
||||
long sum = 0;
|
||||
for (int i = 0; i < 1_000_000; i++) {
|
||||
sum += stats[i];
|
||||
}
|
||||
```
|
||||
|
||||
위 코드는 한 개의 코어로 며칠 동안 작업을 수행한다. 반면 아래의 코드는 첫 스레드를 다음 처럼 실행한다.
|
||||
|
||||
```java
|
||||
long sum0 = 0;
|
||||
for (int i = 0; i < 250_000; i++) {
|
||||
sum0 += stats[i];
|
||||
}
|
||||
```
|
||||
|
||||
그리고 네 번째 스레드는 다음으로 끝난다.
|
||||
```java
|
||||
long sum3 = 0;
|
||||
for (int i = 750_000; i < 1_000_000; i++) {
|
||||
sum3 += stats[i];
|
||||
}
|
||||
```
|
||||
|
||||
메인 프로그램은 네 개의 스레드를 완성하고 자바의 `.start()`로 실행한 다음 `.join()`으로 완료될 때까지 기다렸다가 다음을 계산한다.
|
||||
|
||||
```java
|
||||
sum = sum0 + ... + sum3;
|
||||
```
|
||||
|
||||
이를 각 루프로 처리하는 것은 성가시며 쉽게 에러가 발생할 수 있는 구조다. 루프가 아닌 코드라면 어떻게 처리할지도 난감해진다.
|
||||
|
||||
이전에, 자바 스트림으로 외부 반복(명시적 루프) 대신 내부 반복을 통해 얼마나 쉽게 병렬성을 달성할 수 있는지 설명했다.
|
||||
```java
|
||||
sum = Arrays.stream(stats).parallel().sum();
|
||||
```
|
||||
|
||||
결론적으로 병렬 스트림 반복은 명시적으로 스레드를 사용하는 것에 비해 높은 수준의 개념이라는 사실을 알 수 있다.
|
||||
다시 말해 스트림을 이용해 스레드 사용 패턴을 `추상화`할 수 있다.
|
||||
스트림으로 추상화하는 것은 디자인 패턴을 적용하는 것과 비슷하지만 대신 쓸모 없는 코드가 라이브러리 내부로 구현되면서 복잡성도 줄어든다는 장점이 더해진다.
|
||||
|
||||
추가적인 스레드 추상화를 살펴보기에 앞서 추상화의 기반 개념에 해당하는 자바 5의 `ExecutorService` 개념과 스레드 풀을 살펴보자.
|
||||
|
||||
### 15.1.2 Executor와 스레드 풀
|
||||
자바 5는 `Executor` 프레임워크와 스레드 풀을 통해 스레드의 힘을 높은 수준으로 끌어올리는 즉 자바 프로그래머가 태스크 제출과 실행을 분리할 수 있는 기능을 제공한다.
|
||||
|
||||
#### 스레드의 문제
|
||||
자바 스레드는 직접 운영체제 스레드에 접근한다. 운영체제 스레드를 만들고 종료하려면 비싼 비용(페이지 테이블과 관련한 상호작용)을 치러야 하며
|
||||
더욱이 운영체제 스레드의 숫자는 제한되어 있는 것이 문제다. 운영체제가 지원하는 스레드 수를 초과해 사용하면 자바 애플리케이션이 예상치 못한 방식으로
|
||||
크래시될 수 있으므로 기존 스레드가 실행되는 상태에서 계속 새로운 스레드를 만드는 상황이 일어나지 않도록 주의해야 한다.
|
||||
|
||||
보통 운영체제와 자바의 스레드 개수가 하드웨어 스레드 개수보다 많으므로 일부 운영체제 스레드가 블록되거나 자고 있는 상황에서 모든 하드웨어 스레드가
|
||||
코드를 실행하도록 할당된 상황에 놓일 수 있다. 다양한 기기에서 실행할 수 있는 프로그램에서는 미리 하드웨어 스레드 개수를 추측하지 않는 것이 좋다.
|
||||
한편 주어진 프로그램에서 사용할 최적의 자바 스레드 개수는 사용할 수 있는 하드웨어 코어의 개수에 따라 달라진다.
|
||||
|
||||
#### 스레드 풀 그리고 스레드 풀이 더 좋은 이유
|
||||
자바 `ExecutorService`는 태스크를 제출하고 나중에 결과를 수집할 수 있는 인터페이스를 제공한다.
|
||||
프로그램은 `newFixedThreadPool` 같은 팩토리 메서드 중 하나를 이용해 스레드 풀을 만들어 사용할 수 있다.
|
||||
|
||||
```java
|
||||
ExecutorService newFixedThreadPool(int nThreads)
|
||||
```
|
||||
|
||||
이 메서드는 워커 스레드라 불리는 `nThreads`를 포함하는 `ExecutorService`를 만들고 이들을 스레드 풀에 저장한다.
|
||||
스레드 풀에서 사용하지 않은 스레드로 제출된 태스크를 먼저 온 순서대로 실행한다. 이들 태스크 실행이 종료되면 이들 스레드를 풀로 반환한다.
|
||||
이 방식의 장점은 하드웨어에 맞는 수의 태스크를 유지함과 동시에 수 천개의 태스크를 스레드 풀에 아무 오버헤드 없이 제출할 수 있다는 점이다.
|
||||
큐의 크기 조정, 거부 정책, 태스크 종류에 따른 우선순위 등 다양한 설정을 할 수 있다.
|
||||
|
||||
프로그래머가 `태스크(Runnable이나 Callable)`를 제공하면 `스레드`가 이를 실행한다.
|
||||
|
||||
#### 스레드 풀 그리고 스레드 풀이 나쁜 이유
|
||||
거의 모든 관점에서 스레드를 직접 사용하는 것보다 스레드 풀을 이용하는 것이 바람직하지만 두 가지 "사항"을 주의해야 한다.
|
||||
|
||||
- k 스레드를 가진 스레드 풀은 오직 k만큼의 스레드를 동시에 실행할 수 있다. 초과로 제출된 태스크는 큐에 저장되며 이전에 태스크 중 하나가 종료되기
|
||||
전까지는 스레드에 할당하지 않는다. 불필요하게 많은 스레드를 만드는 일을 피할 수 있으므로 보통 이 상황은 아무 문제가 되지 않지만
|
||||
잠을 자거나 I/O를 기다리거나 네트워크 연결을 기다리는 태스크가 있다면 주의해야 한다. I/O를 기다리는 블록 상황에서 이들 태스크가 워커 스레드에
|
||||
할당된 상태를 유지하지만 아무 작업도 하지 않게 된다. [그림 15-3]에서 보여주는 것처럼 네 개의 하드웨어 스레드와 5개의 스레드를 갖는 스레드 풀에 20개의 태스크를
|
||||
제출했다고 가정하자. 모든 태스크가 병렬로 실행되면서 20개의 태스크를 실행할 것이라 생각할 수 있다. 하지만 처음 제출한 세 스레드가 잠을 자거나 I/O를 기다린다고 가정하자.
|
||||
그러면 나머지 15개의 태스크를 두 스레드가 실행해야 하므로 작업 효율성이 예상보다 절반으로 떨어진다. 처음 제출한 태스크나 기존 실행 중인 태스크가
|
||||
나중의 태스크 제출을 기다리는 상황(`Future`의 일반적인 패턴)이라면 데드락에 걸릴 수도 있다. 핵심은 블록(자거나 이벤트를 기다리는)할 수 있는 태스크는
|
||||
스레드 풀에 제출하지 말아야 한다는 것이지만 항상 이를 지킬 수 있는 것은 아니다.
|
||||
- 중요한 코드를 실행하는 스레드가 죽는 일이 발생하지 않도록 보통 자바 프로그램은 `main`이 반환하기 전에 모든 스레드의 작업이 끝나길 기다린다.
|
||||
따라서 프로그램을 종료하기 전에 모든 스레드 풀을 종료하는 습관을 갖는 것이 중요하다(풀의 워커 스레드가 만들어진 다음 다른 태스크 제출을 기다리면서
|
||||
종료되지 않은 상태일 수 있으므로). 보통 장기간 실행하는 인터넷 서비스를 관리하도록 오래 실행되는 `ExecutorService`를 갖는 것은 흔한 일이다.
|
||||
자바는 이런 상황을 다룰 수 있도록 `Thread.setDaemon` 메서드를 제공한다.
|
||||
|
||||
##### 그림 15-3 자는 태스크는 스레드 풀의 성능을 저하시킨다.
|
||||
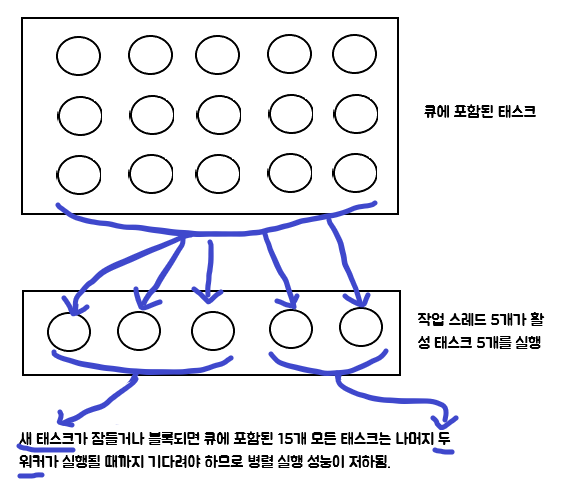
|
||||
|
||||
### 15.1.3 스레드의 다른 추상화 : 중첩되지 않은 메서드 호출
|
||||
7장(`병렬 스트림 처리와 포크/조인 프레임워크`)에서 설명한 동시성과 지금 설명하는 동시성이 어떻게 다른지 명확하게 알 수 있도록 7장에서 사용한 동시성에서는
|
||||
한 개의 특별한 속성 즉, 태스크나 스레드가 메서드 호출 안에서 시작되면 그 메서드 호출은 반환하지 않고 작업이 끝나기를 기다렸다. 다시 말해 스레드 생성과
|
||||
`join()`이 한 쌍처럼 중첩된 메서드 호출 내에 추가되었다. [그림 15-4]에서 보여주는 것처럼 이를 `엄격한 포크/조인`이라 부른다.
|
||||
|
||||
시작된 태스크를 내부 호출이 아니라 외부 호출에서 종료하도록 기다리는 좀 더 여유로운 방식의 `포크/조인`을 사용해도 비교적 안전하다. 그러면 [그림 15-5]에서
|
||||
보여주는 것처럼 제공된 인터페이스를 사용자는 일반 호출로 간주할 수 있다.
|
||||
|
||||
##### 그림 15-4 엄격한 포크/조인. 화살표는 스레드, 원은 포크와 조인을, 사각형은 메서드 호출과 반환을 의미한다.
|
||||

|
||||
|
||||
##### 그림 15-5 여유로운 포크/조인
|
||||
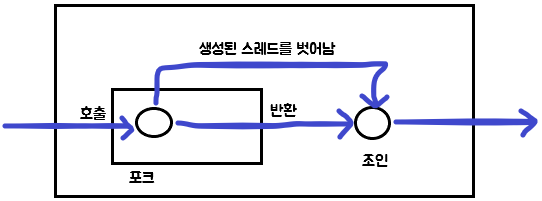
|
||||
|
||||
여기서는 [그림 15-6]처럼 사용자의 메서드 호출에 의해 스레드가 생성되고 메서드를 벗어나 계속 실행되는 동시성 형태에 초점을 둔다.
|
||||
|
||||
##### 그림 15-6 비동기 메서드
|
||||
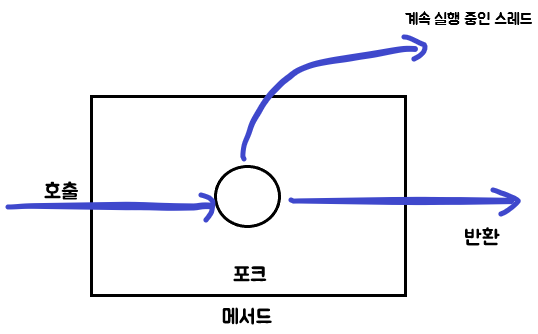
|
||||
|
||||
이런 종류, 특히 메서드 호출자에 기능을 제공하도록 메서드가 반환된 후에도 만들어진 태스크 실행이 계속되는 메서드를 비동기 메서드라 한다.
|
||||
이러한 메서드를 사용할 때 다음과 같은 위험성이 따를 수 있다.
|
||||
- 스레드 실행은 메서드를 호출한 다음의 코드와 동시에 실행되므로 데이터 경쟁 문제를 일으키지 않도록 주의해야 한다.
|
||||
- 기존 실행 중이던 스레드가 종료되지 않은 상황에서 자바의 `main()` 메서드가 반환하면 어떻게 될까? 다음과 같은 두 가지 방법이 있는데 어느 방법도 안전하지 못하다.
|
||||
- **애플리케이션을 종료하지 못하고 모든 스레드가 실행을 끝낼 떄까지 기다린다.**
|
||||
- **애플리케이션 종료를 방해하는 스레드를 강제종료시키고 애플리케이션을 종료한다.**
|
||||
|
||||
첫 번째 방법에서는 잊고서 종료를 못한 스레드에 의해 애플리케이션이 크래시될 수 있다. 또 다른 문제로 디스크에 쓰기 I/O 작업을 시도하는
|
||||
일련의 작업을 중단했을 때 이로 인해 외부 데이터의 일관성이 파괴될 수 있다.
|
||||
이들 문제를 피하려면 애플리케이션에서 만든 모든 스레드를 추적하고 애플리케이션을 종료하기 전에 스레드 풀을 포함한 모든 스레드를 종료하는 것이 좋다.
|
||||
자바 스레드는 `setDaemon()` 메서드를 이용해 **데몬** 또는 비데몬으로 구분시킬 수 있다.
|
||||
데몬 스레드는 애플리케이션이 종료될 때 강제 종료되므로 디스크의 데이터 일관성을 파괴하지 않는 동작을 수행할 때 유용하게 활용할 수 있는 반면,
|
||||
`main()` 메서드는 모든 비데몬 스레드가 종료될 때까지 프로그램을 종료하지 않고 기다린다.
|
||||
|
||||
### 15.1.4 스레드에 무엇을 바라는가?
|
||||
일반적으로 모든 하드웨어 스레드를 활용해 병렬성의 장점을 극대화하도록 프로그램 구조를 만드는 것 즉, 프로그램을 작은 태스크 단위로 구조화하는 것이
|
||||
목표다(하지만 태스크 변환 비용을 고려해 너무 작은 크기는 아니어야 한다). 7장에서는 병렬 스트림 처리와 포크/조인을 `for` 루프와 분할 그리고 정복 알고리즘을
|
||||
처리하는 방법을 살펴봤는데 이 장의 나머지 부분과 16, 17장에서는 스레드를 조작하는 복잡한 코드를 구현하지 않고 메서드를 호출하는 방법을 살펴본다.
|
||||
|
||||
---
|
||||
|
||||
## 15.2 동기 API와 비동기 API
|
||||
7장에서는 자바 8 스트림을 이용해 명시적으로 병렬 하드웨어를 이용할 수 있음을 설명했다. 두 가지 단계로 병렬성을 이용할 수 있다.
|
||||
첫 번째로 외부 반복(명시적 for 루프)을 내부 반복(스트림 메서드 사용)으로 바꿔야 한다. 그리고 스트림에 `parallel()` 메서드를 이용하므로
|
||||
자바 런타임 라이브러리가 복잡한 스레드 작업을 하지 않고 병렬로 요소가 처리되도록 할 수 있다.
|
||||
루프가 실행될 때 추측에 의존해야 하는 프로그래머와 달리 런타임 시스템은 사용할 수 있는 스레드를 더 정확하게 알고 있다는 것도 내부 반복의 장점이다.
|
||||
|
||||
루프 기반의 계산을 제외한 다른 상황에서도 병렬성이 유용할 수 있다. 이후에 살펴볼 중요한 자바 개발의 배경에는 비동기 API가 있다.
|
||||
|
||||
다음과 같은 시그니처를 갖는 `f`, `g` 두 메서드의 호출을 합하는 예제를 살펴보자.
|
||||
|
||||
```java
|
||||
int f(int x);
|
||||
int g(int x);
|
||||
```
|
||||
|
||||
참고로 이들 메서드는 물리적 결과를 반환하므로 `동기 API`라고 부른다. 다음처럼 두 메서드를 호출하고 합계를 출력하는 코드가 있다.
|
||||
|
||||
```java
|
||||
int y = f(x);
|
||||
int z = g(x);
|
||||
System.out.println(y + z);
|
||||
```
|
||||
|
||||
`f`와 `g`를 실행하는데 오랜 시간이 걸린다고 가정하자. `f`, `g`의 작업을 컴파일러가 완전하게 이해하기 어려우므로 보통 자바 컴파일러는 코드 최적화와
|
||||
관련한 아무 작업도 수행하지 않을 수 있다. `f`와 `g`가 서로 상호작용하지 않는다는 사실을 알고 있거나 상호작용을 전혀 신경쓰지 않는다면 `f`와 `g`를 별도의
|
||||
CPU 코어로 실행함으로 `f`와 `g`중 오래 걸리는 작업의 시간으로 합계 구하는 시간을 단축할 수 있다. 별도의 스레드로 `f`와 `g`를 실행해 이를 구현할 수 있다.
|
||||
의도는 좋지만 이전의 단순했던 코드가 다음처럼 복잡하게 변한다.
|
||||
|
||||
```java
|
||||
class ThreadExample {
|
||||
public static void main(String[] args) throws InterruptedException {
|
||||
int x = 1337;
|
||||
Result result = new Result();
|
||||
|
||||
Thread t1 = new Thread(() -> {result.left = f(x);});
|
||||
Thread t2 = new Thread(() -> {result.right = g(x);});
|
||||
t1.start();
|
||||
t2.start();
|
||||
t1.join();
|
||||
t2.join();
|
||||
System.out.println(result.left + result.right);
|
||||
}
|
||||
|
||||
private static class Result {
|
||||
private int left;
|
||||
private int right;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
`Runnable` 대신 `Future` API 인터페이스를 이용해 코드를 더 단순화할 수 있다. 이미 `ExecutorService`로 스레드 풀을 설정했다고 가정하면
|
||||
다음처럼 코드를 구현할 수 있다.
|
||||
|
||||
```java
|
||||
public class ExecutorServiceExample {
|
||||
public static void main(String[] args) throws ExecutionException, InterruptedException {
|
||||
int x = 1337;
|
||||
|
||||
ExecutorService executorService = Executors.newFixedThreadPool(2);
|
||||
Future<Integer> y = executorService.submit(() -> f(x));
|
||||
Future<Integer> z = executorService.submit(() -> g(x));
|
||||
System.out.println(y.get() + z.get());
|
||||
|
||||
executorService.shutdown();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
여전히 이 코드도 명시적인 `submit` 메서드 호출 같은 불필요한 코드로 오염되었다. 명시적 반복으로 병렬화를 수행하던 코드를 스트림을 이용해 내부 반복으로
|
||||
바꾼 것처럼 비슷한 방법으로 이 문제를 해결해야 한다.
|
||||
|
||||
문제의 해결은 `비동기 API`라는 기능으로 API를 바꿔서 해결할 수 있다.
|
||||
|
||||
첫 번째 방법인 자바의 `Future`를 이용하면 이 문제를 조금 개선할 수 있다. 자바 5에서 소개된 `Future`는 자바 8의 `CompletableFuture`로 이들을
|
||||
조합할 수 있게 되면서 더욱 기능이 풍부해졌다. 두 번째 방법은 발행-구독 프로토콜에 기반한 자바 9의 `java.util.concurrent.Flow` 인터페이스를
|
||||
이용하는 방법이며, 이후에 소개하도록 한다.
|
||||
|
||||
이런 대안들을 이 문제에 적용하면 `f`, `g`의 시그니처가 어떻게 바뀔까?
|
||||
|
||||
### 15.2.1 Future 형식 API
|
||||
대안을 이용하면 `f`, `g`의 시그니처가 다음처럼 바뀐다.
|
||||
|
||||
```java
|
||||
Future<Integer> f(int x);
|
||||
Future<Integer> g(int x);
|
||||
```
|
||||
|
||||
그리고 다음처럼 호출이 바뀐다.
|
||||
|
||||
```java
|
||||
Future<Integer> y = f(x);
|
||||
Future<Integer> z = g(x);
|
||||
System.out.println(y.get() + z.get());
|
||||
```
|
||||
|
||||
메서드 `f`는 호출 즉시 자신의 원래 바디를 평가하는 태스크를 포함하는 `Future`를 반환한다. 마찬가지로 메서드 `g`도 `Future`를 반환하며 세 번째 코드는
|
||||
`get()` 메서드를 이용해 두 `Future`가 완료되어 결과가 합쳐지기를 기다린다.
|
||||
|
||||
예제에서는 API는 그대로 유지하고 `g`를 그대로 호출하면서 `f`에만 `Future`를 적용할 수 있었다. 하지만 조금 더 큰 프로그램에서는
|
||||
두 가지 이유로 이런 방식을 사용하지 않는다.
|
||||
- 다른 상황에서는 `g`에도 `Future` 형식이 필요할 수 있으므로 API 형식을 통일하는 것이 바람직하다.
|
||||
- 병렬 하드웨어로 프로그램 실행 속도를 극대화하려면 여러 개의 작지만 합리적인 크기의 태스크로 나누는 것이 좋다.
|
||||
|
||||
### 15.2.2 리액티브 형식 API
|
||||
두 번째 대안에서 핵심은 `f`, `g`의 시그니처를 바꿔서 콜백 형식의 프로그래밍을 이용하는 것이다.
|
||||
|
||||
```java
|
||||
void f(int x, IntConsumer dealWithResult);
|
||||
```
|
||||
|
||||
처음에는 두 번째 대안이 이상해 보일 수 있다. `f`가 값을 반환하지 않는데 어떻게 프로그램이 동작할까? `f`에 추가 인수로 콜백(람다)을 전달해서
|
||||
`f`의 바디에서는 `return` 문으로 결과를 반환하는 것이 아니라 결과가 준비되면 이를 람다로 호출하는 태스크를 만드는 것이 비결이다.
|
||||
`f`는 바디를 실행하면서 태스크를 만든 다음 즉시 반환하므로 코드 형식이 다음처럼 바뀐다.
|
||||
|
||||
```java
|
||||
public class CallbackStyleExample {
|
||||
public static void main(String[] args) {
|
||||
int x = 1337;
|
||||
Result result = new Result();
|
||||
|
||||
f(x, (int y) -> {
|
||||
result.left = y;
|
||||
System.out.println((result.left + result.right));
|
||||
});
|
||||
|
||||
g(x, (int z) -> {
|
||||
result.right = z;
|
||||
System.out.println((result.left + result.right));
|
||||
});
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
하지만 결과가 달라졌다. `f`와 `g`의 호출 합계를 정확하게 출력하지 않고 상황에 따라 먼저 계산된 결과를 출력한다.
|
||||
락을 사용하지 않으므로 값을 두 번 출력할 수 있을 뿐더러 때로는 +에 제공된 두 피연산자가 `println`이 호출되기 전에 업데이트될 수도 있다.
|
||||
다음처럼 두 가지 방법으로 이 문제를 보완할 수 있다.
|
||||
|
||||
- `if-then-else`를 이용해 적절한 락을 이용해 두 콜백이 모두 호출되었는지 확인한 다음 `println`을 호출해 원하는 기능을 수행할 수 있다.
|
||||
- 리액티브 형식의 API는 보통 한 결과가 아니라 일련의 이벤트에 반응하도록 설계되었으므로 `Future`를 이용하는 것이 더 적절하다.
|
||||
|
||||
리액티브 형식의 프로그래밍으로 메서드 `f`와 `g`는 `dealWithResult` 콜백을 여러 번 호출할 수 있다. 원래의 `f`, `g` 함수는 오직 한 번만
|
||||
`return`을 사용하도록 되어있다. 마찬가지로 `Future`도 한 번만 완료되며 그 결과는 `get()`으로 얻을 수 있다.
|
||||
리액티브 형식의 비동기 API는 자연스럽게 일련의 값(나중에 스트림으로 연결)을, `Future` 형식의 API는 일회성의 값을 처리하는 데 적합니다.
|
||||
|
||||
두 대안 모두 코드를 복잡하게 만든다고 생각할 것이다. 어느 정도는 맞는 말이다. 어떤 API를 사용할 것인지 미리 잘 생각해야 한다. 하지만 API는
|
||||
명시적으로 스레드를 처리하는 코드에 비해 사용 코드를 더 단순하게 만들어주며 높은 수준의 구조를 유지할 수 있게 도와준다.
|
||||
또한 (a) 계산이 오래 걸리는 메서드(수 밀리초 이상), (b) 네트워크나 사람의 입력을 기다리는 메서드에 이들 API를 잘 활용하면 애플리케이션의
|
||||
효율성이 크게 향상된다. (b)의 상황에서는 리소스를 낭비하지 않고 효율적으로 하단의 시스템을 활용할 수 있다는 장점을 추가로 제공한다.
|
||||
|
||||
### 15.2.3 잠자기(그리고 기타 블로킹 동작)는 해로운 것으로 간주
|
||||
사람과 상호작용하거나 어떤 일이 일정 속도로 제한되어 일어나는 상황의 애플리케이션을 만들 때 자연스럽게 `sleep()` 메서드를 사용할 수 있다.
|
||||
하지만 스레드는 잠들어도 여전히 시스템 자원을 점유한다. 스레드를 단지 몇 개 사용하는 상황에서는 큰 문제가 아니지만 스레드가 많아지고
|
||||
그 중 대부분이 잠을 잔다면 문제가 심각해진다.
|
||||
|
||||
스레드 풀에서 잠을 자는 태스크는 다른 태스크가 시작되지 못하게 막으므로 자원을 소비한다는 사실을 기억하자(운영 체제가 이들 태스크를 관리하므로
|
||||
일단 스레드로 할당된 태스크는 중지시키지 못한다.)
|
||||
|
||||
물론 스레드 풀에서 잠자는 스레드만 실행을 막는것은 아니다. 모든 블록 동작도 마찬가지다. 블록 동작은 다른 태스크가 어떤 동작을 완료하기를
|
||||
기다리는 동작(예를 들어, `Future`에 `get()` 호출)과 외부 상호작용(예를 들어, 네트워크, 데이터베이스 서버에서 읽기 작업을 기다리거나, 키보드 입력 같은
|
||||
사람의 상호작용을 기다림)을 기다리는 동작 두 가지로 구분할 수 있다.
|
||||
|
||||
이상적으로는 절대 태스크에서 기다리는 일을 만들지 말거나 아니면 코드에서 예외를 일으키는 방법으로 이를 처리할 수 있따. 태스크를 앞과 뒤 부분으로 나누고
|
||||
블록되지 않을 떄만 뒷부분을 자바가 스케줄링하도록 요청할 수 있다.
|
||||
|
||||
다음은 한 개의 작업을 갖는 코드 A다.
|
||||
|
||||
```java
|
||||
work1();
|
||||
Thread.sleep(10000); // 10초 동안 잠
|
||||
work2();
|
||||
```
|
||||
|
||||
이를 코드 B와 비교하자.
|
||||
|
||||
```java
|
||||
public class ScheduleExecutorServiceExample {
|
||||
public static void main(String[] args) {
|
||||
ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(1);
|
||||
|
||||
work1();
|
||||
scheduledExecutorService.schedule(ScheduledExecutorService::work2, 10, TimeUnit.SECONDS); // work1()이 끝난 다음 10초 뒤에 work2()를 개별 태스크로 스케줄함
|
||||
|
||||
scheduledExecutorService.shutdown();
|
||||
}
|
||||
|
||||
public static void work1() {
|
||||
System.out.println("Hello from Work1!");
|
||||
}
|
||||
|
||||
public static void work2() {
|
||||
System.out.println("Hello from Work2!");
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
두 태스크 모두 스레드 풀에서 실행된다고 가정하자.
|
||||
|
||||
코드 A가 어떻게 실행되는지 살펴보자. 먼저 코드는 스레드 풀 큐에 추가되며 나중에 차례가 되면 실행된다. 하지만 코드가 실행되면 워커 스레드를
|
||||
점유한 상태에서 아무것도 하지 않고 10초를 잔다. 그리고 깨어나서 `work2()`를 실행한 다음 작업을 종료하고 워커 스레드를 해제한다.
|
||||
반면에 코드 B는 `work1()`을 실행하고 종료한다. 하지만 `work2()`가 10초 뒤에 실행될 수 있도록 큐에 추가한다.
|
||||
|
||||
코드 B가 더 좋은 이유는 뭘까? 코드 A나 B 모두 같은 동작을 수행한다. 두 코드의 다른 점은 A가 자는 동안 귀중한 스레드 자원을 점유하는 반면
|
||||
B는 다른 작업이 실행될 수 있도록 허용한다는 점이다(스레드를 사용할 필요가 없이 메모리만 조금 더 사용했다).
|
||||
|
||||
태스크를 만들 떄는 이런 특징을 잘 활용해야 한다. 태스크가 실행되면 귀중한 자원을 점유하므로 태스크가 끝나서 자원을 해제하기 전까지 태스크를
|
||||
계속 실행해야 한다. 태스크를 블록하는 것보다는 다음 작업을 태스크로 제출하고 현재 태스크는 종료하는 것이 바람직하다.
|
||||
|
||||
가능하다면 I/O 작업에도 이 원칙을 적용하는 것이 좋다. 고전적으로 읽기 작업을 기다리는 것이 아니라 블록하지 않는 '읽기 시작' 메서드를 호출하고
|
||||
읽기 작업이 끝나면 이를 처리할 다음 태스크를 런타임 라이브러리에 스케줄하도록 요청하고 종료한다.
|
||||
|
||||
이런 디자인 패턴을 따르려면 읽기 어려운 코드가 많아지는 것처럼 보일 수 있다. 하지만 자바 `CompletableFuture` 인터페이스는 이전에 살펴본 `Future`에
|
||||
`get()`을 이용해 명시적으로 블록하지 않고 콤비네이터를 사용함으로 이런 형식의 코드를 런탕미 라이브러리 내에 추상화한다.
|
||||
|
||||
마지막으로 스레드의 제한이 없고 저렴하다면 코드 A와 B는 사실상 같다. 하지만 스레드에는 제한이 있고 저렴하지 않으므로 잠을 자거나 블록해야 하는
|
||||
여러 태스크가 있을 때 가능하면 코드 B 형식을 따르는 것이 좋다.
|
||||
|
||||
### 15.2.4 현실성 확인
|
||||
새로운 시스템을 설계할 때 시스템을 많은 작은 동시 실행되는 태스크로 설계해서, 블록할 수 있는 모든 동작을 비동기 호출로 구현한다면 병렬 하드웨어를
|
||||
최대한 활용할 수 있다. 하지만 현실적으로는 '모든 것은 비동기'라는 설계 원칙을 어겨야 한다('최상은 좋은 것의 적이다'라는 속담을 기억하자).
|
||||
자바는 2002년 자바 1.4에서부터 비블록 10 기능(`java.nio`)을 제공했는데 이들은 조금 복잡하고 잘 알려지지 않았따. 실제로 자바의 개선된
|
||||
동시성 API를 이용해 유익을 얻을 수 있는 상황을 찾아보고 모든 API를 비동기로 만드는 것을 따지지 말고 개선된 동시성 API를 사용해보길 권장한다.
|
||||
|
||||
네트워크 서버의 블록/비블록 API를 일관적으로 제공하는 `Netty(https://netty.io/)` 같은 새로운 라이브러리를 사용하는것도 도움이 된다.
|
||||
|
||||
### 15.2.5 비동기 API에서 예외는 어떻게 처리되는가?
|
||||
`Future`나 리액티브 형식의 비동기 API에서 호출된 메서드의 실제 바디는 별도의 스레드에서 호출되며 이때 발생하는 어떤 에러는 이미 호출자의
|
||||
실행 범위와는 관계가 없는 상황이 된다. 예상치못한 일이 일어나면 예외를 발생시켜 다른 동작이 실행되어야 한다. 어떻게 이를 실현할 수 있을까?
|
||||
`Future`를 구현한 `CompletableFuture`에서는 런타임 `get()` 메서드에 예외를 처리할 수 있는 기능을 제공하며 예외에서 회복할 수 있도록
|
||||
`exceptionally()` 같은 메서드도 제공한다.
|
||||
|
||||
리액티브 형식의 비동기 API에서는 `return` 대신 기존 콜백이 호출되므로 예외가 발생했을 때 실행될 추가 콜백을 만들어 인터페이스를 바꿔야 한다.
|
||||
다음 예제처럼 리액티브 API에 여러 콜백을 포함해야 한다.
|
||||
|
||||
```java
|
||||
void f(int x, Consumer<Integer> dealWithResult, Consumer<Throwable> dealWithException);
|
||||
```
|
||||
|
||||
`f`의 바디는 다음을 수행할 수 있다.
|
||||
|
||||
```java
|
||||
dealWithException(e);
|
||||
```
|
||||
|
||||
콜백이 여러 개면 이를 따로 제공하는 것보다는 한 객체로 이 메서드를 감싸는 것이 좋다. 예를 들어 `자바 9 플로 API`에서는 여러 콜백을
|
||||
한 객체(네 개의 콜백을 각각 대표하는 네 메서드를 포함하는 `Subcriber<T>` 클래스)로 감싼다. 다음은 그 예제다.
|
||||
|
||||
```java
|
||||
void onComplete()
|
||||
void onError(Throwable throwable)
|
||||
void onNext(T item)
|
||||
```
|
||||
|
||||
값이 있을 때(`onNext`), 도중에 에러가 발생했을 때(`onError`), 값을 다 소진했거나 에러가 발생해서 더 이상 처리할 데이터가 없을 때(`onComplete`) 각각의 콜백이 호출된다.
|
||||
이전의 `f`에 이를 적용하면 다음과 같이 시그니처가 바뀐다.
|
||||
|
||||
```java
|
||||
void f(int x, Subscriber<Integer> s);
|
||||
```
|
||||
|
||||
`f`의 바디는 다음처럼 `Throwable`을 가리키는 `t`로 예외가 일어났음을 가리킨다.
|
||||
|
||||
```java
|
||||
s.onError(t);
|
||||
```
|
||||
|
||||
여러 콜백을 포함하는 API를 파일이나 키보드 장치에서 숫자를 읽는 작업과 비교해보자. 이들 장치가 수동적인 데이터 구조체가 아니라 "여기 번호 나왔어요"나
|
||||
"숫자가 아니라 잘못된 형식의 아이템이 나왔어요" 같은 일련의 데이터를 만들어낸 다음 마지막으로 "더 이상 처리할 데이터가 없어요(파일의 끝)" 알림을 만든다.
|
||||
|
||||
보통 이런 종류의 호출을 메시지 또는 **이벤트**라 부른다. 예를 들어 파일 리더가 3, 7, 42를 읽은 다음 잘못된 형식의 숫자 이벤트를 내보내고
|
||||
이어서 2, 파일의 끝 이벤트를 차례로 생성했다고 가정하자.
|
||||
이런 이벤트를 API의 일부로 보자면 API는 이벤트의 순서(**채널 프로토콜**이라 불리는)에는 전혀 개의치 않는다. 실제 부속 문서에서는 "`onComplete` 이벤트 다음에는
|
||||
아무 이벤트도 일어나지 않음" 같은 구문을 사용해 프로토콜을 정의한다.
|
||||
|
||||
---
|
||||
|
||||
## 15.3 박스와 채널 모델
|
||||
동시성 모델을 가장 잘 설계하고 개념화하려면 그림이 필요하다. 우리는 이 기법을 **박스와 채널 모델**(box-and-channel model)이라고 부른다.
|
||||
이전 예제인 `f(x) + g(x)`의 계산을 일반화해서 정수와 관련된 간단한 상황이 있다고 가정하자. `f`나 `g`를 호출하거나 `p` 함수에 인수 `x`를 이용해 호출하고
|
||||
그 결과를 `q1`과 `q2`에 전달하며 다시 이 두 호출의 결과로 함수 `r`을 호출한 다음 결과를 출력한다. 편의상 클래스 `C`의 메서드와 연상 함수 `C::m`을 구분하지 않는다.
|
||||
[그림 15-7]에서 보여주는 것처럼 간단한 태스크를 그림으로 표현할 수 있다.
|
||||
|
||||
##### 그림 15-7 간단한 박스와 채널 다이어그램
|
||||
|
||||
|
||||
자바로 [그림 15-7]을 두 가지 방법으로 구현해 어떤 문제가 있는지 확인하자. 다음은 첫 번째 구현 방법이다.
|
||||
|
||||
```java
|
||||
int t = p(x);
|
||||
System.out.println(r(q1(t), q2(t)));
|
||||
```
|
||||
|
||||
겉보기엔 깔끔해 보이는 코드지만 자바가 `q1`,`q2`를 차례로 호출하는데 이는 하드웨어 병렬성의 활용과 거리가 멀다.
|
||||
`Future`를 이용해 `f`, `g`를 병렬로 평가하는 방법도 있다.
|
||||
|
||||
```java
|
||||
int t = p(x);
|
||||
Future<Integer> a1 = executorService.submit(() -> q1(t));
|
||||
Future<Integer> a2 = executorService.submit(() -> q2(t));
|
||||
System.out.println(r(a1.get(), a2.get()));
|
||||
```
|
||||
|
||||
이 예제에서는 박스와 채널 다이어그램의 모양상 `p`와 `r`을 `Future`로 감싸지 않았다. `p`는 다른 어떤 작업보다 먼저 처리해야 하며 `r`은
|
||||
모든 작업이 끝난 다음 가장 마지막으로 처리해야 한다. 아래처럼 코드를 흉내내보지만 이는 우리가 원하는 작업과 거리가 있다.
|
||||
|
||||
```java
|
||||
System.out.println(r(q1(t), q2(t)) + s(x));
|
||||
```
|
||||
|
||||
위 코드에서 병렬성을 극대화하려면 모든 다섯 함수(`p`, `q1`, `q2`, `r`, `s`)를 `Future`로 감싸야 하기 때문이다.
|
||||
|
||||
시스템에서 많은 작업이 동시에 실행되고 있지 않다면 이 방법도 잘 동작할 수 있다. 하지만 시스템이 커지고 각각의 많은 박스와 채널 다이어그램이
|
||||
등장하고 각각의 박스는 내부적으로 자신만의 박스와 채널을 사용한다면 문제가 달라진다. 이런 상황에서는 앞서 설명한 것처럼 많은 태스크가 `get()`
|
||||
메서드를 호출해 `Future`가 끝나기를 기다리는 상태에 놓일 수 있다. 결과적으로 하드웨어의 병렬성을 제대로 활용하지 못하거나 심지어 데드락에 걸릴 수 있다.
|
||||
또한 이런 대규모 시스템 구조가 얼마나 많은 수의 `get()`을 감당할 수 있는지 이해하기 어렵다. 자바 8에서는 다음에 설명할 `CompletableFuture`와 **콤비네이터**를 이용해 문제를 해결한다.
|
||||
두 `Function`이 있을 때 `compose()`, `andThen()` 등을 이용해 다른 `Function`을 얻을 수 있다는 사실을 확인했다(3장 참고).
|
||||
`add1`은 정수 1을 더하고 `dble`은 정수를 두 배로 만든다고 가정하면 인수를 두 배로 만들고 결과에 2를 더하는 `Function`을 다음처럼 구현할 수 있다.
|
||||
|
||||
```java
|
||||
Function<Integer, Integer> myfun = add1.andThen(dble);
|
||||
```
|
||||
|
||||
하지만 박스와 채널 다이어그램은 콤비네이터로도 직접 멋지게 코딩할 수 있다. [그림 15-7]을 자바 `Function p, q1, q2, Bifunction r`로 간단하게 구현할 수 있다.
|
||||
|
||||
```java
|
||||
p.thenBoth(q1, q2).thenCombine(r)
|
||||
```
|
||||
|
||||
안타깝게도 `thenBoth`나 `thenCombine`은 자바 `Function`과 `BiFunction` 클래스의 일부가 아니다.
|
||||
|
||||
다음(15.4절)으로는 콤비네이터와 `CompletableFuture`의 개념이 얼마나 비슷하며 `get()`을 이용해 태스크가 기다리게 만드는 일을 피할 수 있는지 설명한다.
|
||||
|
||||
박스와 채널 모델을 이용해 생각과 코드를 구조화할 수 있으며, 박스와 채널 모델로 대규모 시스템 구현의 추상화 수준을 높일 수 있다.
|
||||
박스(또는 프로그램의 콤비네이터)로 원하는 연산을 표현(계산은 나중에 이루어짐)하면 계산을 손으로 코딩한 결과보다 더 효율적일 것이다.
|
||||
콤비네이터는 수학적 함수뿐 아니라 `Future`와 `리액티브 스트림 데이터`에도 적용할 수 있다. 15.5절에서는 박스와 채널 다이어그램의 각 채널을
|
||||
마블 다이어그램(메시지를 가리키는 여러 마블을 포함)으로 표현하는 방법을 설명한다. 박스와 채널 모델은 병렬성을 직접 프로그래밍하는 관점을
|
||||
콤비네이터를 이용해 내부적으로 작업을 처리하는 관점으로 바꿔준다. 마찬가지로 자바 8 스트림은 자료 구조를 반복해야 하는 코드를 내부적으로
|
||||
작업을 처리하는 스트림 콤비네이터로 바꿔준다.
|
||||
|
||||
---
|
||||
|
||||
## 15.4 CompletableFuture와 콤비네이터를 이용한 동시성
|
||||
동시 코딩 작업을 `Future` 인터페이스로 생각하도록 유도한다는 점이 `Future` 인터페이스의 문제다. 하지만 역사적으로 주어진 연산으로 `Future`를 만들고,
|
||||
이를 실행하고, 종료되길 기다리는 등 `Future`는 `FutureTask` 구현을 뛰어 넘는 몇 가지 동작을 제공했다.
|
||||
이후 버전의 자바에서는 7장에서 설명한 `RecursiveTask` 같은 더 구조화된 지원을 제공했다.
|
||||
|
||||
자바 8에서는 `Future` 인터페이스의 구현인 `CompletableFuture`를 이용해 `Future`를 조합할 수 있는 기능을 추가했다. 그럼 `ComposableFuture`가 아니라
|
||||
`CompletableFuture`라고 부르는 이유는 뭘까? 일반적으로 `Future`는 실행해서 `get()`으로 결과를 얻을 수 있는 `Callable`로 만들어진다.
|
||||
하지만 `CompletableFuture`는 실행할 코드 없이 `Future`를 만들 수 있도록 허용하며 `complete()` 메서드를 이용해 나중에 어떤 값을 이용해
|
||||
다른 스레드가 이를 완료할 수 있고 `get()`으로 값을 얻을 수 있도록 허용한다(그래서 `CompletableFuture`라 부른다).
|
||||
`f(x)`와 `g(x)`를 동시에 실행해 합계를 구하는 코드를 다음처럼 구현할 수 있다.
|
||||
|
||||
```java
|
||||
public class CFComplete {
|
||||
public static void main(String[] args) throws ExecutionException, InterruptedException{
|
||||
ExecutorService executorService = Executors.newFixedThreadPool(10);
|
||||
int x = 1337;
|
||||
|
||||
CompletableFuture<Integer> a = new CompletableFuture<>();
|
||||
executorService.submit(() -> a.complete(f(x)));
|
||||
int b = g(x);
|
||||
System.out.println(a.get() + b);
|
||||
|
||||
executorService.shutdown();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
또는 다음처럼 구현할 수 있다.
|
||||
|
||||
```java
|
||||
public class CFComplete {
|
||||
public static void main(String[] args) throws ExecutionException, InterruptedException {
|
||||
ExecutorService executorService = Executors.newFixedThreadPool(10);
|
||||
int x = 1337;
|
||||
|
||||
CompletableFuture<Integer> a = new CompletableFuture<>();
|
||||
executorService.submit(() -> b.complete(g(x)));
|
||||
int a = f(x);
|
||||
System.out.println(a + b.get());
|
||||
|
||||
executorService.shutdown();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
위 두 코드는 `f(x)`의 실행이 끝나지 않거나 아니면 `g(x)`의 실행이 끝나지 않는 상황에서 `get()`을 기다려야 하므로 프로세싱 자원을 낭비할 수 있다.
|
||||
자바 8의 `CompletableFuture`를 이용하면 이 상황을 해결할 수 있다.
|
||||
|
||||
>##### 퀴즈 15-1
|
||||
>위와 같은 상황에서 스레드를 완벽하게 활용할 수 있는 태스크를 어떻게 구현할 수 있을까? `f(x)`, `g(x)`를 실행하는 두 개의 활성 스레드가 있는데
|
||||
한 스레드는 다른 스레드가 `return` 문을 실행해 종료될 떄까지 기다렸다가 시작한다.
|
||||
>
|
||||
>정답은 `f(x)`를 실행하는 한 태스크, `g(x)`를 실행하는 두 번째 태스크, 합계를 계산하는 세 번째 태스크(이전의 두 태스크를 재활용 할 수 있다)
|
||||
세 개를 이용하는 것이다 .하지만 처음 두 태스크가 실행되기 전까지 세 번쨰 태스크는 실행할 수 없다. 이 문제는 `Future`를 조합해 해결할 수 있다.
|
||||
|
||||
`CompletableFuture<T>`에 `thenCombine` 메서드를 사용함으로 두 연산 결과를 더 효과적으로 더할 수 있다(16장에서 자세히 다룰 것이다).
|
||||
`thenCombine` 메서드는 다음과 같은 시그니처(제네릭과 와일드카드와 관련된 문제를 피할 수 있게 간소화됨)를 갖고 있다.
|
||||
|
||||
```java
|
||||
CompletableFuture<V> thenCombine(CompletableFuture<U> other, BiFunction<T, U, V> fn)
|
||||
```
|
||||
|
||||
이 메서드는 두 개의 `CompletableFuture` 값(T, U 결과 형식)을 받아 한 개의 새 값을 만든다.
|
||||
처음 두 작업이 끝나면 두 결과 모두에 fn을 적용하고 블록하지 않은 상태로 결과 `Future`를 반환한다. 이전 코드를 다음처럼 구현할 수 있다.
|
||||
|
||||
```java
|
||||
public class CFCombine {
|
||||
public static void main(String[] args) throws ExecutionException, InterruptedException {
|
||||
ExecutorService executorService = Executors.newFixedThreadPool(10);
|
||||
int x = 1337;
|
||||
|
||||
CompletableFuture<Integer> a = new CompletableFuture<>();
|
||||
CompletableFuture<Integer> b = new CompletableFuture<>();
|
||||
CompletableFuture<Integer> c = a.thenCombine(b, (y, z) -> y + z);
|
||||
executorService.submit(() -> a.complete(f(x)));
|
||||
executorService.submit(() -> b.complete(g(x)));
|
||||
|
||||
System.out.println(c.get());
|
||||
executorService.shutdown();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
`thenCombine` 행이 핵심이다. `Future a`와 `Future b`의 결과를 알지 못한 상태에서 `thenCombine`은 두 연산이 끝났을 때 스레드 풀에서
|
||||
실행된 연산을 만든다. 결과를 추가하는 세 번째 연산 c는 다른 두 작업이 끝날 때까지는 스레드에서 실행되지 않는다(먼저 시작해서 블록되지 않는 점이 특징).
|
||||
따라서 기존의 두 가지 버전의 코드에서 발생했던 블록 문제가 어디서도 일어나지 않는다. `Future`의 연산이 두 번째로 종료되는 상황에서 실제 필요한
|
||||
스레드는 한 개지만 스레드 풀의 두 스레드가 여전히 활성 상태다. [그림 15-8]은 이 상황을 다이어그램으로 보여준다. 이전의 두 버전에서 `y+z` 연산은
|
||||
`f(x)` 또는 `g(x)`를 실행(블록될 가능성이 있는)한 같은 스레드에서 수행했다. 반면 `thenCombine`을 이용하면 `f(x)`와 `g(x)`가 끝난 다음에야
|
||||
덧셈 계산이 실행된다.
|
||||
|
||||
##### 그림 15-8 f(x), g(x), 결과 합산 세 가지 연산의 타이밍 다이어그램
|
||||
,%20g(x),%20%EA%B2%B0%EA%B3%BC%20%ED%95%A9%EC%82%B0%20%EC%84%B8%20%EA%B0%80%EC%A7%80%20%EC%97%B0%EC%82%B0%EC%9D%98%20%ED%83%80%EC%9D%B4%EB%B0%8D%20%EB%8B%A4%EC%9D%B4%EC%96%B4%EA%B7%B8%EB%9E%A8.png)
|
||||
|
||||
상황에 따라서는 `get()`을 기다리는 스레드가 큰 문제가 되지 않으므로 기존 자바 8의 `Future`를 이용한 방식도 해결 방법이 될 수 있다.
|
||||
하지만 어떤 상황에서는 많은 수의 `Future`를 사용해야 한다(예를 들어 서비스에 여러 질의를 처리하는 상황). 이런 상황에서는 `CompletableFuture`와
|
||||
콤비네이터를 이용해 `get()`에서 블록하지 않을 수 있고 그렇게 함으로 병렬 실행의 효율성은 높이고 데드락은 피하는 최상의 해결책을 구현할 수 있다.
|
||||
|
||||
---
|
||||
|
||||
## 15.5 발생-구독 그리고 리액티브 프로그래밍
|
||||
`Future`와 `CompletableFuture`은 독립적 실행과 병렬성이라는 정식적 모델에 기반한다. 연산이 끝나면 `get()`으로 `Future`의 결과를 얻을 수 있다.
|
||||
따라서 `Future`는 **한 번**만 실행해 결과를 제공한다.
|
||||
|
||||
반면 리액티브 프로그래밍은 시간이 흐르면서 여러 `Future` 같은 객체를 통해 여러 결과를 제공한다. 먼저 온도계 객체를 예로 생각해보자.
|
||||
이 객체는 매 초마다 온도 값을 반복적으로 제공한다. 또 다른 예로 웹 서버 컴포넌트 응답을 기다리는 리스너 객체를 생각할 수 있다. 이 객체는
|
||||
네트워크에 HTTP 요청이 발생하길 기다렸다가 이후에 결과 데이터를 생산한다. 그리고 다른 코드에서 온도 값 또는 네트워크 결과를 처리한다.
|
||||
그리고 온도계와 리스너 객체는 다음 결과를 처리할 수 있도록 온도 결과나 다른 네트워크 요청을 기다린다.
|
||||
|
||||
눈여겨봐야 할 두 가지 사실이 있다. 이 두 예제에서 `Future` 같은 동작이 모두 사용되었지만 한 예제에서는 한 번의 결과가 아니라 여러 번의 결과가 필요하다.
|
||||
두 번째 예제에서 눈여겨봐야 할 또 다른 점은 모든 결과가 똑같이 중요한 반면 온도계 예제에서는 대부분의 사람에게 가장 최근의 온도만 중요하다.
|
||||
이런 종류의 프로그래밍을 리액티브라 부르는 이유는 뭘까? 이는 낮은 온도를 감지했을 때 이에 **반응-react-**(예를 들어 히터를 킴)하는 부분이 존재하기 때문이다.
|
||||
|
||||
여기서 스트림을 떠올릴 수 있다. 만약 프로그램이 스트림 모델에 잘 맞는 상황이라면 가장 좋은 구현이 될 수 있다. 하지만 보통 리액티브 프로그래밍
|
||||
패러다임은 비싼 편이다. 주어진 자바 스트림은 한 번의 단발 동작으로 소비될 수 있다. 15.3절에서 살펴본것처럼 스트림 패러다임은 두 개의 파이프라인으로
|
||||
값을 분리(포크처럼)하기 어려우며 두 개로 분리된 스트림에서 다시 결과를 합치기도(조인처럼) 어렵다. 스트림은 선형적인 파이프라인 처리 기법에 알맞다.
|
||||
|
||||
자바 9에서는 `java.util.concurrent.Flow`의 인터페이스에 `발행-구독 모델(또는 줄여서 pub-sub이라 불리는 프로토콜)`을 적용해 리액티브 프로그래밍을 제공한다.
|
||||
`자바 9 플로 API`는 17장에서 자세히 살펴보겠지만 여기서는 간단히 다음처럼 세 가지로 플로 API를 정리할 수 있다.
|
||||
|
||||
- **구독자**가 구독할 수 있는 **발행자**
|
||||
- 이 연결을 **구독**(subscription)이라 한다.
|
||||
- 이 연결을 이용해 **메시지**(또는 **이벤트**로 알려짐)를 전송한다.
|
||||
|
||||
[그림 15-9]는 구독을 채널로 발행자와 구독자를 박스로 표현한 그림을 보여준다. 여러 컴포넌트가 한 구독자로 구독할 수 있고 한 컴포넌트는
|
||||
여러 개별 스트림을 발행할 수 있으며 한 컴포넌트는 여러 구독자에 가입할 수 있다.
|
||||
15.5.1절에서는 이 개념이 실제 어떻게 동작하는지를 자바 9 플로 인터페이스로 한 단계씩 설명한다.
|
||||
|
||||
##### 그림 15-9 발행자-구독자 모델
|
||||
|
||||
|
||||
### 15.5.1 두 플로를 합치는 예제
|
||||
두 정보 소스로부터 발생하는 이벤트를 합쳐서 다른 구독자가 볼 수 있도록 발행하는 예를 통해 `발행-구독`의 특징을 간단하게 확인할 수 있다.
|
||||
사실 이 기능은 수식을 포함하는 스프레드시트의 셀에서 흔히 제공하는 동작이다. "=C1+C2"라는 공식을 포함하는 스프레드시트 셀 C3을 만들자.
|
||||
C1이나 C2의 값이 갱신되면(사람에 의해서 또는 각 셀이 포함하는 또 다른 공식에 의해서) C3에도 새로운 값이 반영된다. 다음 코드는 셀의 값을 더할 수만 있다고 가정한다.
|
||||
|
||||
먼저 값을 포함하는 셀을 구현한다.
|
||||
|
||||
```java
|
||||
private class SimpleCell {
|
||||
private int value = 0;
|
||||
private String name;
|
||||
|
||||
public SimpleCell(String name) {
|
||||
this.name = name;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
아직은 코드가 단순한 편이며 다음처럼 몇 개의 셀을 초기화할 수 있다.
|
||||
|
||||
```java
|
||||
SimpleCell c1 = new SimpleCell("C1");
|
||||
SimpleCell c2 = new SimpleCell("C2");
|
||||
```
|
||||
|
||||
c1이나 c2의 값이 바뀌었을 때 c3가 두 값을 더하도록 어떻게 지정할 수 있을까? c1과 c2에 이벤트가 발생했을 때 c3를 구독하도록 만들어야 한다.
|
||||
그러려면 다음과 같은 인터페이스 `Publisher<T>`가 필요하다.
|
||||
|
||||
```java
|
||||
interface Publisher<T> {
|
||||
void subscribe(Subscriber<? super T> subscriber);
|
||||
}
|
||||
```
|
||||
|
||||
이 인터페이스는 통신할 구독자를 인수로 받는다. `Subscriber<T>` 인터페이스는 `onNext`라는 정보를 전달할 단순 메서드를 포함하며 구현자가 필요한대로
|
||||
이 메서드를 구현할 수 있다.
|
||||
|
||||
```java
|
||||
interface Subcriber<T> {
|
||||
void onNext(T t);
|
||||
}
|
||||
```
|
||||
|
||||
이 두 개념을 어떻게 합칠 수 있을까? 사실 `Cell`은 `Publisher`(셀의 이벤트에 구독할 수 있음)이며 동시에 `Subscriber`(다른 셀의 이벤트에 반응함)임을 알 수 있다.
|
||||
|
||||
```java
|
||||
private class SimpleCell implements Publisher<Integer>, Subscriber<Integer> {
|
||||
private int value = 0;
|
||||
private String name;
|
||||
private List<Subscriber> subscribers = new ArrayList<>();
|
||||
|
||||
public SimpleCell(String name) {
|
||||
this.name = name;
|
||||
}
|
||||
|
||||
@Override
|
||||
public void subscribe(Subscriber<? super Integer> subscriber) {
|
||||
subscribers.add(subscriber);
|
||||
}
|
||||
|
||||
private void notifyAllSubscribers() { // 새로운 값이 있음을 모든 구독자에게 알리는 메서드
|
||||
subscribers.forEach(subscriber -> subscriber.onNext(this.value));
|
||||
}
|
||||
|
||||
@Override
|
||||
public void onNext(Integer newValue) {
|
||||
this.value = newValue; // 구독한 셀에 새 값이 생겼을 때 값을 갱신해서 반응함
|
||||
System.out.println(this.name + ":" + this.value); // 값을 콘솔로 출력하지만 실제로는 UI의 셀을 갱신할 수 있음
|
||||
notifyAllSubscribers(); // 값이 갱신되었음을 모든 구독자에게 알림
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
다음 간단한 예제를 시도해보자.
|
||||
|
||||
```java
|
||||
SimpleCell c3 = new SimpleCell("C3");
|
||||
SimpleCell c2 = new SimpleCell("C2");
|
||||
SimpleCell c1 = new SimpleCell("C1");
|
||||
|
||||
c1.subscribe(c3);
|
||||
|
||||
c1.onNext(10); // C1의 값을 10으로 갱신
|
||||
c2.onNext(20); // C2의 값을 20으로 갱신
|
||||
```
|
||||
|
||||
C3는 직접 C1을 구독하므로 다음과 같은 결과가 출력된다.
|
||||
>C1:10
|
||||
>C3:10
|
||||
>C2:20
|
||||
|
||||
'C3=C1+C2'은 어떻게 구현할까? 왼쪽과 오른쪽의 연산 결과를 저장할 수 있는 별도의 클래스가 필요하다.
|
||||
|
||||
```java
|
||||
public class ArithmeticCell extends SimpleCell {
|
||||
private int left;
|
||||
private int right;
|
||||
|
||||
public ArithmeticCell(String name) {
|
||||
super(name);
|
||||
}
|
||||
|
||||
public void setLeft(int left) {
|
||||
this.left = left;
|
||||
onNext(left + this.right); // 셀 값을 갱신하고 모든 구독자에 알림
|
||||
}
|
||||
|
||||
public void setRight(int right) {
|
||||
this.right = right;
|
||||
onNext(right + this.left); // 셀 값을 갱신하고 모든 구독자에 알림
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
다음처럼 조금 더 실용적인 예제를 시도할 수도 있다.
|
||||
|
||||
```java
|
||||
ArithmeticCell c3 = new ArithmeticCell("C3");
|
||||
SimpleCell c2 = new SimpleCell("C2");
|
||||
SimpleCell c1 = new SimpleCell("C1");
|
||||
|
||||
c1.subscribe(c3::setLeft);
|
||||
c2.subscribe(c3::setRight);
|
||||
|
||||
c1.onNext(10); // C1의 값을 10으로 갱신
|
||||
c2.onNext(20); // C2의 값을 20으로 갱신
|
||||
c1.onNext(15); // C1의 값을 15으로 갱신
|
||||
```
|
||||
|
||||
다음은 출력 결과다.
|
||||
>C1:10
|
||||
>C3:10
|
||||
>C2:20
|
||||
>C3:30
|
||||
>C1:15
|
||||
>C3:35
|
||||
|
||||
결과를 통해 C1의 값이 15로 갱신되었을 때 C3이 즉시 반응해 자신의 값을 갱신한다는 사실을 확인할 수 있다.
|
||||
발행자-구독자 상호작용의 멋진 점은 발행자 구독자의 그래프를 설정할 수 있다는 점이다.
|
||||
예를 들어 "C5=C3+C4"처럼 C3과 C4에 의존하는 새로운 셀 C5를 만들 수 있다.
|
||||
|
||||
```java
|
||||
ArithmeticCell c5 = new ArithmeticCell("C5");
|
||||
ArithmeticCell c3 = new ArithmeticCell("C3");
|
||||
|
||||
SimpleCell c4 = new SimpleCell("C4");
|
||||
SimpleCell c2 = new SimpleCell("C2");
|
||||
SimpleCell c1 = new SimpleCell("C1");
|
||||
|
||||
c1.subscribe(c3::setLeft);
|
||||
c2.subscribe(c3::setRight);
|
||||
|
||||
c3.subscribe(c5::setLeft);
|
||||
c4.subscribe(c5::setRight);
|
||||
```
|
||||
|
||||
이제 스프레드시트에 다음과 같은 다양한 갱신 작업을 수행할 수 있다.
|
||||
|
||||
```java
|
||||
c1.onNext(10); // C1의 값을 10으로 갱신
|
||||
c2.onNext(20); // C2의 값을 20으로 갱신
|
||||
c1.onNext(15); // C2의 값을 20으로 갱신
|
||||
c4.onNext(1); // C2의 값을 20으로 갱신
|
||||
c4.onNext(3); // C2의 값을 20으로 갱신
|
||||
```
|
||||
|
||||
위 동작을 수행하면 다음과 같은 결과가 출력된다.
|
||||
>C1:10
|
||||
>C3:10
|
||||
>C5:10
|
||||
>C2:20
|
||||
>C3:30
|
||||
>C5:30
|
||||
>C1:15
|
||||
>C3:35
|
||||
>C5:35
|
||||
>C4:1
|
||||
>C5:36
|
||||
>C4:3
|
||||
>C5:38
|
||||
|
||||
최종적으로 C1은 15, C2는 20, C4는 3이므로 C5는 38의 값을 갖는다.
|
||||
|
||||
>데이터가 발행자(생산자)에서 구독자(소비자)로 흐름에 착안해 개발자는 이를 **업스트림(upstream)** 또는 **다운스트림(downstream)**이라 부른다.
|
||||
>위 예제에서 데이터 `newValue`는 업스트림 `onNext()` 메서드로 전달되고 `notifyAllSubscribers()` 호출을 통해 다운스트림 `onNext()` 호출로 전달된다.
|
||||
|
||||
지금까지 `발행-구독` 핵심 개념을 확인했다. 하지만 부수적인 내용은 다루지 않았지만 `역압력(backpressure)` 같은 내용은 중요하므로 다음 절에서 따로 설명한다.
|
||||
|
||||
우선은 리액티브 프로그래밍과 직접적으로 관련이 있는 내용만 살펴본다. 15.2절에서 설명한것처럼 실생활에서 플로를 사용하려면
|
||||
`onNext` 이벤트 외에 `onError`나 `onComplete` 같은 메서드를 통해 데이터 흐름에서 예외가 발생하거나
|
||||
데이터 흐름이 종료되었음을 알 수 있어야 한다(예를 들어 온도계 샘플이 교체되어서 `onNext`로 더 이상 데이터가 발생하지 않는 상황).
|
||||
`자바 9 플로 API`의 `Subcriber`에서는 실제 `onError`와 `onComplete`를 지원한다.
|
||||
기존의 옵저버 패턴에 비해 새로운 API 프로토콜이 더 강력해진 이유가 이들 바로 이런 메서드 덕분이다.
|
||||
|
||||
간단하지만 플로 인터페이스의 개념을 복잡하게 만든 두 가지 기능은 `압력`과 `역압력`이다. 처음에는 이 두 기능이 별로 중요해 보이지 않을 수 있지만
|
||||
스레드 활용에서 이들 기능은 필수다. 기존의 온도계 예제에서 온도계가 매 초마다 온도를 보고했는데 기능이 업그레이드 되면서 매 밀리초마다 온도계를 보고한다고 가정하자.
|
||||
우리 프로그램은 이렇게 빠른 속도로 발생하는 이벤트를 아무 문제없이 처리할 수 있을까? 마찬가지로 모든 SMS 메시지를 폰으로 제공하는 발행자에 가입하는 상황을 생각해보자.
|
||||
처음에 약간의 SMS 메시지가 있는 새 폰에서는 가입이 잘 동작할 수 있지만 몇 년 후에는 매 초마다 수천 개의 메시지가 `onNext`로 전달된다면 어떤 일이 일어날까?
|
||||
이런 상황을 `압력(pressure)`이라 부른다.
|
||||
|
||||
공에 담긴 메시지를 포함하는 수직 파이프를 상상해보자. 이런 상황에서는 출구로 추가될 공의 숫자를 제한하는 `역압력` 같은 기법이 필요하다.
|
||||
`자바 9 플로 API`에서는 발행자가 무한의 속도로 아이템을 방출하는 대신 요청했을 때만 다음 아이템을 보내도록 하는
|
||||
`request()` 메서드(`Subscription`이라는 새 인터페이스에 포함)를 제공한다(`밀어내기(push)모델`이 아니라 `당김(pull)모델`).
|
||||
|
||||
### 15.5.2 역압력
|
||||
`Subscriber` 객체(`onNext`, `onError`, `onComplete` 메서드를 포함)를 어떻게 `Publisher`에게 전달해 발행자가 필요한 메서드를 호출할 수 있는지 살펴봤다.
|
||||
이 객체는 `Publisher`에서 `Subscriber`로 정보를 전달한다. 정보의 흐름 속도를 `역압력(흐름 제어)`으로 제어,
|
||||
즉 `Subscriber`에서 `Publisher`로 정보를 요청해야 할 필요가 있을 수 있다.
|
||||
`Publisher`는 여러 `Subscriber`를 갖고 있으므로 역압력 요청이 한 연결에만 영향을 미쳐야 한다는 것이 문제가 될 수 있다.
|
||||
`자바 9 플로 API`의 `Subcriber` 인터페이스는 네 번째 메서드를 포함한다.
|
||||
|
||||
```java
|
||||
void onSubscribe(Subscription subscription);
|
||||
```
|
||||
|
||||
`Publisher`와 `Subscriber` 사이에 채널이 연결되면 첫 이벤트로 이 메서드가 호출된다. `Subscription` 객체는 다음처럼
|
||||
`Subscriber`와 `Publisher`와 통신할 수 있는 메서드를 포함한다.
|
||||
|
||||
```java
|
||||
interface Subscription {
|
||||
void cancel();
|
||||
void request(long n);
|
||||
}
|
||||
```
|
||||
|
||||
콜백을 통한 '역방향' 소통 효과에 주목하자. `Publisher`는 `Subscription` 객체를 만들어 `Subscriber`로 전달하면 `Subscriber`는 이를 이용해
|
||||
`Publisher`로 정보를 보낼 수 있다.
|
||||
|
||||
### 15.5.3 실제 역압력의 간단한 형태
|
||||
한 번에 한 개의 이벤트를 처리하도록 `발행-구독` 연결을 구성하려면 다음과 같은 작업이 필요하다.
|
||||
- `Subscriber`가 `OnSubscribe`로 전달된 `Subscription` 객체를 `subscription` 같은 필드에 로컬로 저장한다.
|
||||
- `Subscriber`가 수 많은 이벤트를 받지 않도록 `onSubscribe`, `onNext`, `onError`의 마지막 동작에 `channel.request(1)`을 추가해 오직 한 이벤트만 요청한다.
|
||||
- 요청을 보낸 채널에만 `onNext`, `onError` 이벤트를 보내도록 `Publisher`의 `notifyAllSubscribers` 코드를 바꾼다
|
||||
(보통 여러 `Subscriber`가 자신만의 속도를 유지할 수 있도록 `Publisher`는 새 `Subscription`을 만들어 각 `Subscriber`와 연결한다).
|
||||
|
||||
구현이 간단해 보일 수 있지만 역압력을 구현하려면 여러 가지 장단점을 생각해야 한다.
|
||||
- 여러 `Subscriber`가 있을 때 이벤트를 가장 느린 속도로 보낼 것인가? 아니면 각 `Subscriber`에게 보내지 않은 데이터를 저장할 별도의 큐를 가질 것인가?
|
||||
- 큐가 너무 커지면 어떻게 해야 할까?
|
||||
- `Subscriber`가 준비가 안 되었다면 큐의 데이터를 폐기할 것인가?
|
||||
|
||||
위 질문의 답변은 데이터의 성격에 따라 달라진다. 한 온도 데이터를 잃어버리는 것은 그리 대수로운 일이 아니지만 은행 계좌에서 크레딧이 사라지는 것은 큰 일이다.
|
||||
|
||||
`당김 기반 리액티브 역압력`이라는 기법에서는 `Subscriber`가 `Publisher`로부터 요청을 `당긴다(pull)`는 의미에서 **리액티브 당김 기반**(reactive pull-based)이라 불린다.
|
||||
결과적으로 이런 방식으로 역압력을 구현할 수도 있다.
|
||||
|
||||
---
|
||||
|
||||
## 15.6 리액티브 시스템 vs 리액티브 프로그래밍
|
||||
프로그래밍과 교육 커뮤니티에서 `리액티브 시스템`과 `리액티브 프로그래밍`이라는 말을 점점 자주 접할 수 있는데 이 둘은 상당히 다른 의미를 가지고 있다.
|
||||
|
||||
`리액티브 시스템(reactive system)`은 런타임 환경이 변화에 대응하도록 전체 아키텍처가 설계된 프로그램을 가리킨다.
|
||||
리액티브 시스템이 가져야 할 공식적인 속성은 `Reactive Manifesto(http://www.reactivemanifesto.org)`에서 확인할 수 있다(17장 참고).
|
||||
`반응성(responsive)`, `회복성(resilient)`, `탄력성(elastic)`으로 세 가지 속성을 요약할 수 있다.
|
||||
|
||||
`반응성`은 리액티브 시스템이 큰 작업을 처리하느라 간단한 질의의 응답을 지연하지 않고 실시간으로 입력에 반응하는 것을 의미한다.
|
||||
`회복성`은 한 컴포넌트의 실패로 전체 시스템이 실패하지 않음을 의미한다. 네트워크가 고장났어도 이와 관계가 없는 질의에는 아무 영향이 없어야 하며
|
||||
반응이 없는 컴포넌트를 향한 질의가 있다면 다른 대안 컴포넌트를 찾아야 한다.
|
||||
`탄력성`은 시스템이 자신의 작업 부하에 맞게 적응하며 작업을 효율적으로 처리함을 의미한다.
|
||||
바에서 음식과 음료를 서빙하는 직원을 동적으로 재배치 하므로 두 가지 주문의 대기줄이 일정하게 유지되도록 하듯이 각 큐가 원활하게 처리될 수 있도록
|
||||
다양한 소프트웨어 서비스와 관련된 작업자 스레드를 적절하게 재배치할 수 있다.
|
||||
|
||||
여러 가지 방법으로 이런 속성을 구현할 수 있지만 `java.util.concurrent.Flow` 관련된 자바 인터페이스에서 제공하는 **리액티브 프로그래밍** 형식을
|
||||
이용하는 것도 주요 방법 중 하나다. 이들 인터페이스 설계는 `Reactive Manifesto`의 네 번째이자 마지막 속성 즉 `메시지 주도(message-driven)` 속성을 반영한다.
|
||||
`메시지 주도 시스템`은 `박스와 채널 모델`에 기반한 내부 API를 갖고 있는데 여기서 컴포넌트는 처리할 입력을 기다리고 결과를 다른 컴포넌트로 보내면서 시스템이 반응한다.
|
||||
|
||||
---
|
||||
|
||||
## 15.7 마치며
|
||||
- 자바의 동시성 지원은 계속 진화해 왔으며 앞으로도 그럴 것이다. 스레드 풀은 보통 유용하지만 블록되는 태스크가 많아지면 문제가 발생한다.
|
||||
- 메서드를 `비동기(결과를 처리하기 전에 반환)`로 만들면 병렬성을 추가할 수 있으며 부수적으로 루프를 최적화한다.
|
||||
- 박스와 채널 모델을 이용해 비동기 시스템을 시각화할 수 있다.
|
||||
- 자바 8 `CompletableFuture` 클래스와 `자바 9 플로 API` 모두 `박스와 채널 다이어그램`으로 표현할 수 있다.
|
||||
- `CompletableFuture` 클래스는 한 번의 비동기 연산을 표현한다. 콤비네이터로 비동기 연산을 조합함으로 `Future`를 이용할 때 발생했던
|
||||
기존의 블로킹 문제를 해결할 수 있다.
|
||||
- `플로 API`는 `발행-구독 프로토콜`, `역압력`을 이용하면 자바의 리액티브 프로그래밍의 기초를 제공한다.
|
||||
- `리액티브 프로그래밍`을 이용해 `리액티브 시스템`을 구현할 수 있다.
|
||||
|
||||
---
|
||||