7.3 KiB
7.3 KiB
29강. 인덱스 작성과 삭제
여기서는 실제로 테이블에 인덱스를 작성하는 방법에 대해서 알아본다.
인덱스 작성, 삭제
CREATE INDEX
DROP INDEX
- 인덱스는 데이터베이스 객체의 하나로
DDL을 사용해서 작성하거나 삭제한다. - 표준 SQL에는
CREATE INDEX명령은 없다. 인덱스 자체가 데이터베이스 제품에 의존하는 선택적인 항목으로 취급된다. - 하지만 대표적인 데이터베이스 제품에는 모두 인덱스 구조가 도입되어 있으며, 모두 비슷한 관리 방법으로 인덱스를 다룰 수 있다.
1. 인덱스 작성
- 인덱스는
CREATE INDEX명령으로 만든다. - 인덱스에 이름을 붙여 관리하는데, 데이터베이스 객체가 될지 테이블의 열처럼 취급될지는 데이터베이스 제품에 따라 다르다.
Oracle이나DB2등에서 인덱스는 스키마 객체가 된다. 따라서 스키마 내에 이름이 중복하지 않도록 지정해 관리한다.- 한편
SQL Server나MySQL에서 인덱스는 테이블 내의 객체가 된다. - 따라서 테이블 내에 이름이 중복되지 않도록 지정해 관리한다.
- 인덱스를 작성할 때는 해당 인덱스가 어느 테이블의 어느 열에 관한 것인지 지정할 필요가 있다.
- 이때 열은 복수로도 지정할 수 있다. 인덱스의 네임스페이스가 데이터베이스 제품마다 다르다는 점만 주의하면 문법은 그렇게 어렵지 않다.
CREATE INDEX
CREATE INDEX 인덱스명 ON 테이블명 (열명1, 열명2, ...)
- 다음 예제에서는 sample62 테이블의 no 열에 isample65라는 인덱스를 지정한다.
- 인덱스를 작성할 때는 저장장치에 색인용 데이터가 만들어진다.
- 테이블 크기에 따라 인덱스 작성시간도 달라지는데, 행이 대량으로 존재하면 시간도 많이 걸리고 저장공간도 많이 소비한다.
인덱스 작성하기
CREATE INDEX isample65 ON sample62(no);
2. 인덱스 삭제
- 인덱스는
DROP INDEX명령으로 삭제한다. DROP할 때는 다른 객체와 동일하게 인덱스 이름만 지정하면 된다.- 다만 테이블 내 객체로서 작성하는 경우에는 테이블 이름도 지정한다(이때 인덱스를 구성하는 열은 지정할 필요가 없다).
DROP INDEX(스키마 객체의 경우)
DROP INDEX 인덱스명
DROP INDEX(테이블 내 객체의 경우)
DROP INDEX 인덱스명 ON 테이블명
- 인덱스는 테이블에 의존하는 객체이다.
DROP TABLE로 테이블을 삭제하면 테이블에 작성된 인덱스도 자동으로 삭제된다.- 인덱스만 삭제하는 경우에는
DROP INDEX를 사용한다.
인덱스 삭제하기
DROP INDEX isample65 ON sample62;
- 인덱스를 작성해두면 검색이 빨라진다.
- 작성한 인덱스의 열을
WHERE구로 조건을 지정하여SELECT명령으로 검색하면 처리속도가 향상된다. - 하지만 모든
SELECT명령에 적용되는 만능 인덱스는 작성할 수 없다. - 한편,
INSERT명령의 경우에는 인덱스를 최신 상태로 갱신하는 처리가 늘어나므로 처리속도가 조금 떨어진다. SELECT명령에서의 인덱스 사용에 관해 조금 더 설명한다. 먼저 다음과 같은 명령으로 인덱스를 작성했다고 가정하자.
CREATE INDEX isample65 ON sample62(a);
WHERE구에 a 열에 대한 조건식을 지정한 경우SELECT명령은 인덱스를 사용해 빠르게 검색할 수 있다.- 예를 들면 다음과 같은
SELECT명령이 된다. 그러나WHERE구의 조건식에 a 열이 전혀 사용되지 않으면SELECT명령은 isample62라는 인덱스를 사용할 수 없다.
SELECT * FROM sample62 WHERE a = 'a';
3. EXPLAIN
- 인덱스 작성을 통해 쿼리의 성능 향상을 기대할 수 있다.
- 이때 실제로 인덱스를 사용해 검색하는지를 확인하려면
EXPLAIN명령을 사용한다.
EXPLAIN
EXPLAIN SQL명령
EXPLAIN명령의 문법은 간단하다.EXPLAIN에 뒤이어 확인하고 싶은SELECT명령 등의 SQL 명령을 지정하면 된다. 다만 이 SQL 명령은 실제로는 실행되지 않는다.- 어떤 상태로 실행되는지를 데이터베이스가 설명해줄 뿐이다.
MySQL의 경우 상황에 따라 다르지만 필요한 정보를 얻기 위해 SQL 명령의 일부분을 실제로 실행하는 경우도 있다.
EXPLAIN은 표준 SQL에는 존재하지 않는, 데이터베이스 제품 의존형 명령이다. 하지만 어떤 데이터베이스 제품이라도 이와 비슷한 명령을 지원한다.
EXPALIN으로 인덱스 사용 확인하기 1 (MySQL)
EXPLAIN SELECT * FROM sample62 WHERE a = 'a';
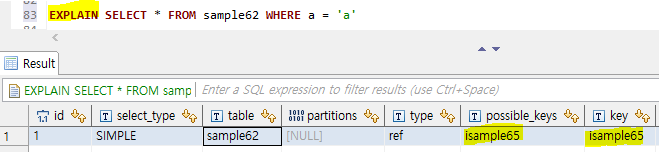
- sample62의 a 열에는 isample65이라는 인덱스가 작성되어 있다.
EXPLAIN의 뒤를 잇는SELECT명령은 a 열의 값을 참조해 검색하므로 isample65을 사용해 검색한다(possible_keys라는 곳에 사용될 수 있는 인덱스가 표시되며,key는 사용된 인덱스가 표시된다).
이때 WHERE 조건을 바꾸면 어떻게 변하는지 알아본다. a 열을 사용하지 않도록 조건을 변경하면 인덱스를 사용할 수 없을 것이다.
EXPLAIN으로 인덱스 사용 확인하기 2 (MySQL)
EXPLAIN SELECT * FROM sample62 WHERE no > 10;
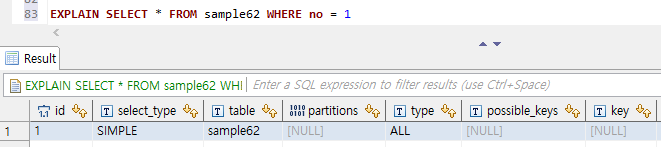
possible_keys와key가NULL이 된다.
4. 최적화
SELECT명령을 실행할 때 인덱스의 사용 여부를 선택한다는 것을 알았다.- 이는 데이터베이스 내부의 최적화에 의해 처리되는 부분이다.
- 내부 처리에서는
SELECT명령을 실행하기에 앞서실행계획을 세운다. - 실행계획에는 '인덱스가 지정된 열이
WHERE조건으로 지정되어 있으니 인덱스를 사용하자'와 같은 처리가 이루어진다. EXPLAIN명령은 이 실행계획을 확인하는 명령이다.- 실행계획에서는 인덱스의 유무뿐만 아니라 인덱스를 사용할 것인지 여부에 대해서도 데이터베이스 내부의 최적화 처리를 통해 판단한다.
- 이때 판단 기준으로 인덱스의 품질도 고려한다.
- 예를 들어 '예' 또는 '아니오'라는 값만 가지는 열이 있다면, 해당 열에 인덱스를 지정해도 다음과 같은 이진트리가 되어 좋은 구조를 가지지 못한다.
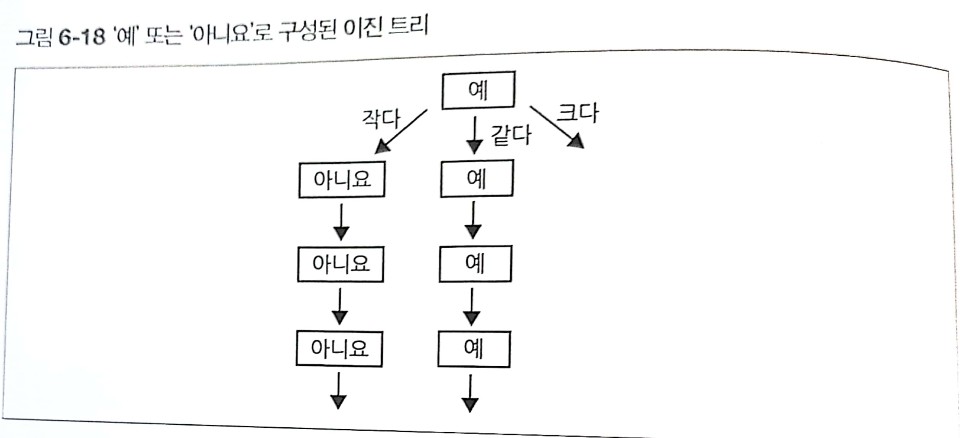
- 이는 단순한 리스트와 별다른 차이가 없는 구조로, 이진탐색에 의한 효율화를 기대할 수 없다.
- 물론 '예' 또는 '아니오'는 극단적인 사례이지만 데이터의 종류가 적으면 적을수록 인덱스의 효율도 떨어진다.
- 반대로 서로 다른 값으로 여러 종류의 데이터가 존재하면 그만큼 효율은 좋아진다.
- 이렇게 인덱스의 품질을 고려해 실행계획이 세워지는 것이다.